BigQuery 連携ガイド
Revision: 1.6.0-10082-768e556f
1 はじめに
1.1 本書の構成
本書では、GridDB CloudとGoogle CloudのBigQueryとの連携方法について説明します。各章の内容は次のとおりです。
※Google Cloud、BigQueryはGoogle社が提供するクラウドサービスです。
はじめに
本書の構成及び用語について説明します。BigQueryについて
BigQueryについて説明します。GridDB CloudとBigQueryとの連携手順
GridDB Cloudから出力したCSVファイルをGoogle Cloudに連携し、BigQueryのデータとして読み込む例を紹介します。GridDB CloudとBigQueryのデータ型のマッピング
GridDB CloudとBigQueryのデータ型のマッピングを表に示します。
1.2 用語の説明
本書で用いられる用語の説明です。
| 用語 | 意味 |
|---|---|
| Google Cloud | Google社が提供しているクラウドサービスです。詳細は(cloud.google.com)を参照してください。 |
| BigQuery | Google Cloudで提供されているサービスの一つです。データウェアハウスを構築して、分析を行えるサービスです。 |
| Data Transfer | Google Cloudで提供されているサービスの一つです。外部のデータソースからのデータ転送を行えるサービスです。 |
| Cloud Storage | Google Cloudで提供されているサービスの一つです。データの格納、蓄積を行えるサービスです。 |
| Azure Blob Storage | Microsoftが提供しているクラウドサービス Microsoft Azureのサービスの一つです。データの格納、蓄積を行えるサービスです。 |
2 BigQueryについて
BigQueryとは、Googleから提供されているクラウドサービス Google Cloudのサービスの一つです。
指定したデータソースからデータウェアハウスを構築して、データの分析を行うサービスです。
詳細は(cloud.google.com/bigquery)を参照してください。
3 GridDB CloudとBigQueryとの連携手順
GridDB CloudとBigQueryの連携手順について説明します。
GridDB CloudとBigQueryの連携手順では、GridDB Cloudの定期エクスポートとAzureのAzure Blob Storage、 Google CloudのData Transfer、Cloud Storage、BigQueryを用います。

GridDB Cloudの定期エクスポートは、GridDB Cloudに蓄積したデータをAzure Blob Storageに出力する機能です。
定期エクスポートの詳細は、『GridDB Cloud 運用管理GUIリファレンス』の (定期エクスポート・スケジュール機能) と(定期エクスポート・ジョブ機能) を参照してください。
GridDB Cloudの定期エクスポートによって、以下の命名規則でCSVファイルが出力されます。
- [GridDBデータベース名.コンテナ名_yyyyMMddHH_id.csv]
出力されたファイルをGoogle CloudのTransfer ServiceでCloud Storageに転送して、Cloud StorageからBigQueryにテーブルのデータとして読み込ませて連携します。連携手順には、手動または不定期で都度実施する手順と、一時間ごとや一日ごと、一週間ごとなど、定期的に実施する手順があります。下記にそれぞれの手順について示します。
■手動または不定期にGridDB CloudとBigQueryとの連携を実施する場合
3.1 GridDB Cloudからの定期エクスポート
3.2 GridDB Cloudからエクスポートしたファイルの転送手順
3.3 Google Cloud Storageのファイルをもとに、BigQueryでテーブルを作成する手順
3.4 BigQueryのテーブルへのデータ追加手順
■定期的にGridDB CloudとBigQueryとの連携を実施する場合
3.1 GridDB Cloudからの定期エクスポート
3.2 GridDB Cloudからエクスポートしたファイルの転送手順
3.3 Google Cloud Storageのファイルをもとに、BigQueryでテーブルを作成する手順
3.5 BigQueryのテーブルへの定期データ追加手順
3.1 GridDB Cloudからの定期エクスポート
GridDB Cloudには定期エクスポート機能があり、GridDBのデータを指定した間隔でエクスポートすることができます。(GridDB CloudとBigQueryとの連携手順の図:①)

定期エクスポートの手順については、『GridDB Cloud 運用管理GUIリファレンス』の (定期エクスポート・スケジュール機能) と(定期エクスポート・ジョブ機能) を参照して、実施してください。
GridDBの定期エクスポートの手順の実施が完了したら、『GridDB Cloud 運用管理GUIリファレンス』の「定期エクスポート・ジョブ機能」の (ストレージアクセス情報/ステップ4) に示すダイアログから以下の情報をメモします。
- [Storage Account]
- [Container Name]
- [SAS]
3.2 GridDB Cloudからエクスポートしたファイルの転送手順
GridDB Cloudの定期エクスポートで出力してAzure Blob Storageに格納されたファイルをGoogle CloudのCloud Storageへ転送する手順について説明します。(GridDB CloudとBigQueryとの連携手順の図:②)

- Google CloudのCloud Storageに転送先のバケットを作成します。
Google Cloudのコンソール上で「Cloud Storage」を選択して、Cloud Storageの一覧画面を開きます。
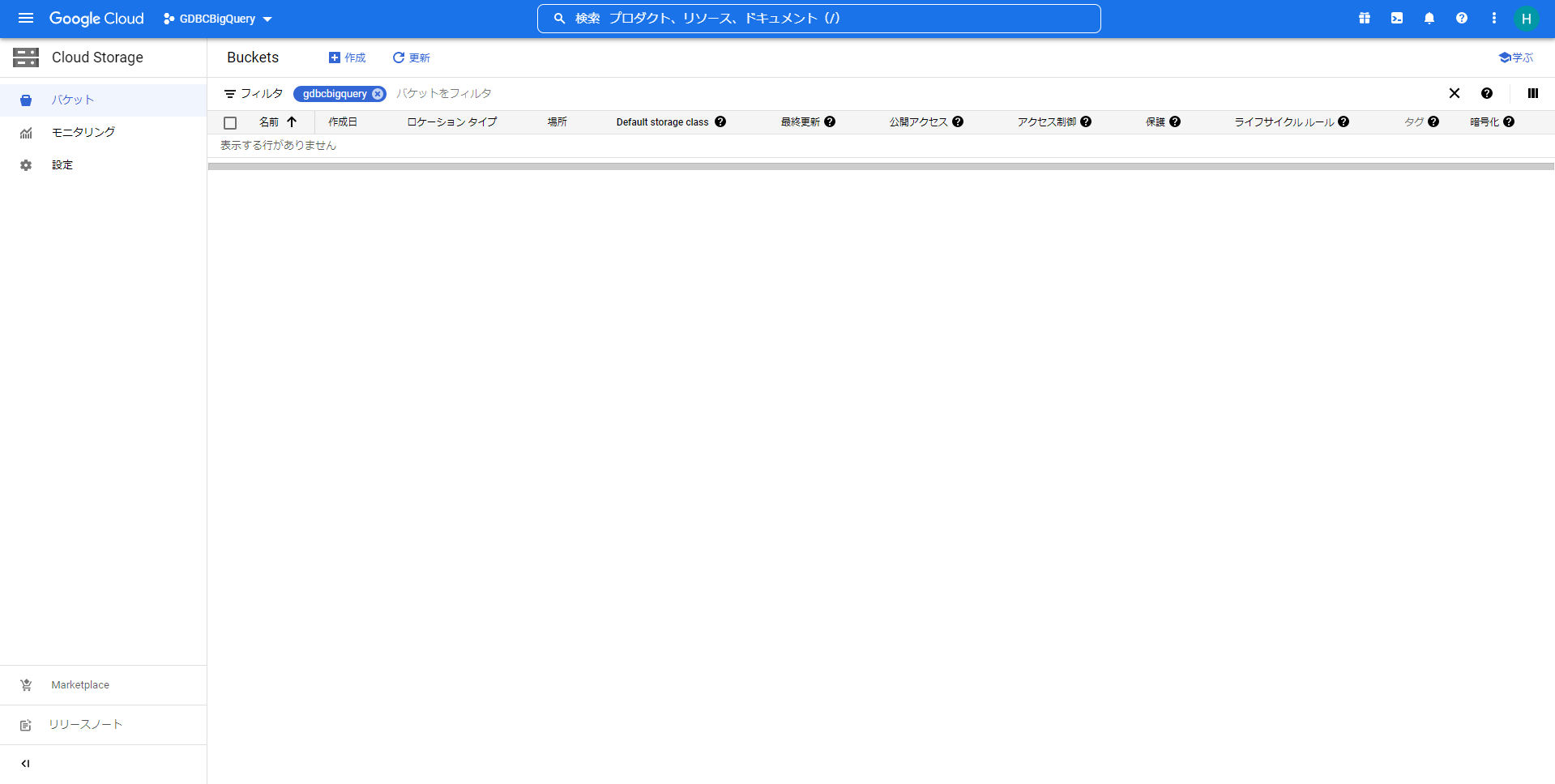
Cloud Storageの一覧画面から「作成」を押して、バケットの作成画面を開きます。
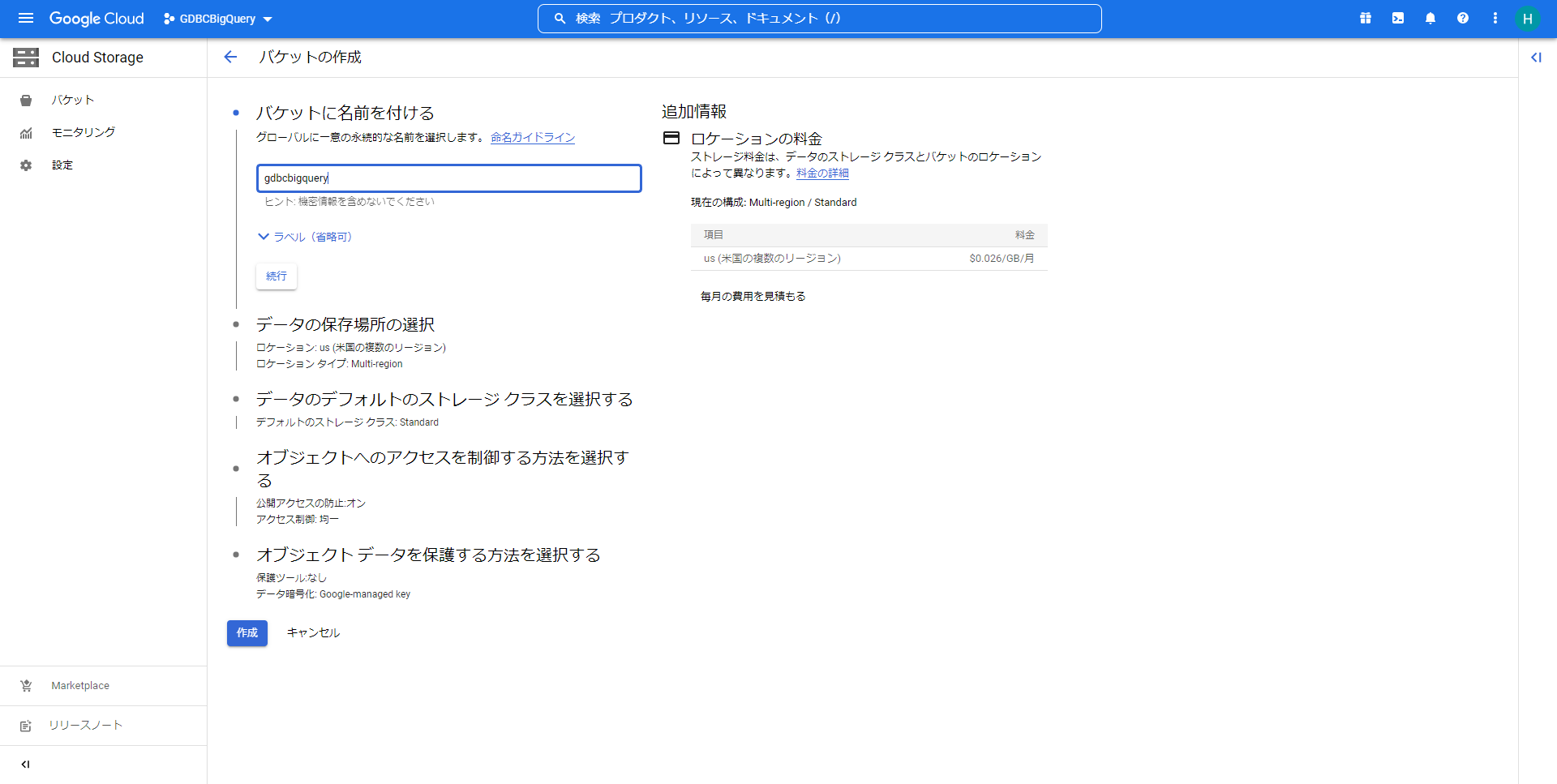
バケット名やデータの保存場所などを設定して、「作成」ボタンを押してバケットを作成します。
- Google CloudのData TransferでファイルをCloud Storageに転送します。
Google Cloudのコンソール上で「Data Transfer」を選択して、転送ジョブの一覧画面を開きます。
![]()
転送ジョブの一覧画面から「転送ジョブを作成」ボタンを押して、転送ジョブの作成画面を開きます。
転送ジョブの作成画面の「①開始」を開いて、「ソースタイプ」に「Azure Blob StorageまたはData Lake Storage Gen2」を選択して、「宛先の種類」に「Google Cloud Storage」を選択して、「次のステップ」ボタンを押して、次の設定に進みます。
![]()
「②ソースの選択」で、以下をそれぞれ記載します。
「ストレージアカウント名」
「GridDB Cloudからの定期エクスポート」でメモした [Storage Account] をストレージアカウント名として記載します。「コンテナまたはフォルダ」
「GridDB Cloudからの定期エクスポート」でメモした [Container Name] をコンテナー名として記載します。「Shared Access Signature(SAS)」
「GridDB Cloudからの定期エクスポート」でメモした [Storage Account] 、 [Container Name] 、 [SAS] から以下のようにURLを作成します。
https://[Storage Account].blob.core.windows.net/[Container Name]?[SAS]
作成したURLを「SAS」として記載します。2022年12月現在、入力フィールドにはSASがプレースホルダとして記載してありますが、SASは直接入力せず、上記のように組み立てたSAS付きのURLを入力してください。フィルタ(省略可)
GridDB Cloudの定期エクスポートで出力ファイル名が「GridDBデータベース名.コンテナ名_yyyyMMddHH_id.csv」となるので、「接頭辞を追加」を押して、「GridDBデータベース名.コンテナ名_yyyyMMdd」などとすると転送するファイルを絞り込むことができます。用途に合わせて適宜設定してください。
各項目の入力が完了したら、「次のステップ」ボタンを押して、次の設定に進みます。
![]()
「③転送先を選択してください」で、「バケットまたはフォルダ」の「参照」から「Google CloudのCloud Storageに転送先のバケットを作成します。」で作成したバケットを選択します。
選択できたら、「次のステップ」ボタンを押して、次の設定に進みます。
![]()
「④ジョブを実行する方法とタイミングを選択する」で、転送のジョブを実行する方法とタイミングを設定します。
「1回だけ実行」
1回だけ転送のジョブを実行します。「毎日実行」
毎日転送のジョブを実行します。「毎週実行」
毎週転送のジョブを実行します。「カスタム頻度で実行」
「カスタム頻度」で設定した間隔で転送のジョブを実行します。
定期的に転送のジョブを実行したい場合は、この設定で転送のジョブの実行のタイミングを設定します。
設定が完了したら、「次のステップ」ボタンを押して、次の設定に進みます。
![]()
「⑤設定の選択」で、ジョブをカスタマイズしたい場合は各設定を行います。
- 削除のタイミング
「転送後にファイルをソースから削除する」を選択してください。
その他の設定は適宜用途に合わせて設定してください。
設定が完了したら、最後に「作成」ボタンを押して、転送ジョブを作成します。
![]()
転送ジョブの一覧画面に戻り、作成したジョブが一覧に追加されます。
設定した方法とタイミングに従い、作成したジョブが実行されて、成功すれば転送は完了です。
![]()
3.3 Google Cloud Storageのファイルをもとに、BigQueryでテーブルを作成する手順
Google CloudのCloud Storage上のファイルをもとに、BigQueryでテーブルを作成する手順について説明します。(GridDB CloudとBigQueryとの連携手順の図:③)

- Google CloudのBigQueryでデータセットを作成します。
Google Cloudのコンソール上で「BigQuery」を選択して、BigQueryのエクスプローラーを開きます。
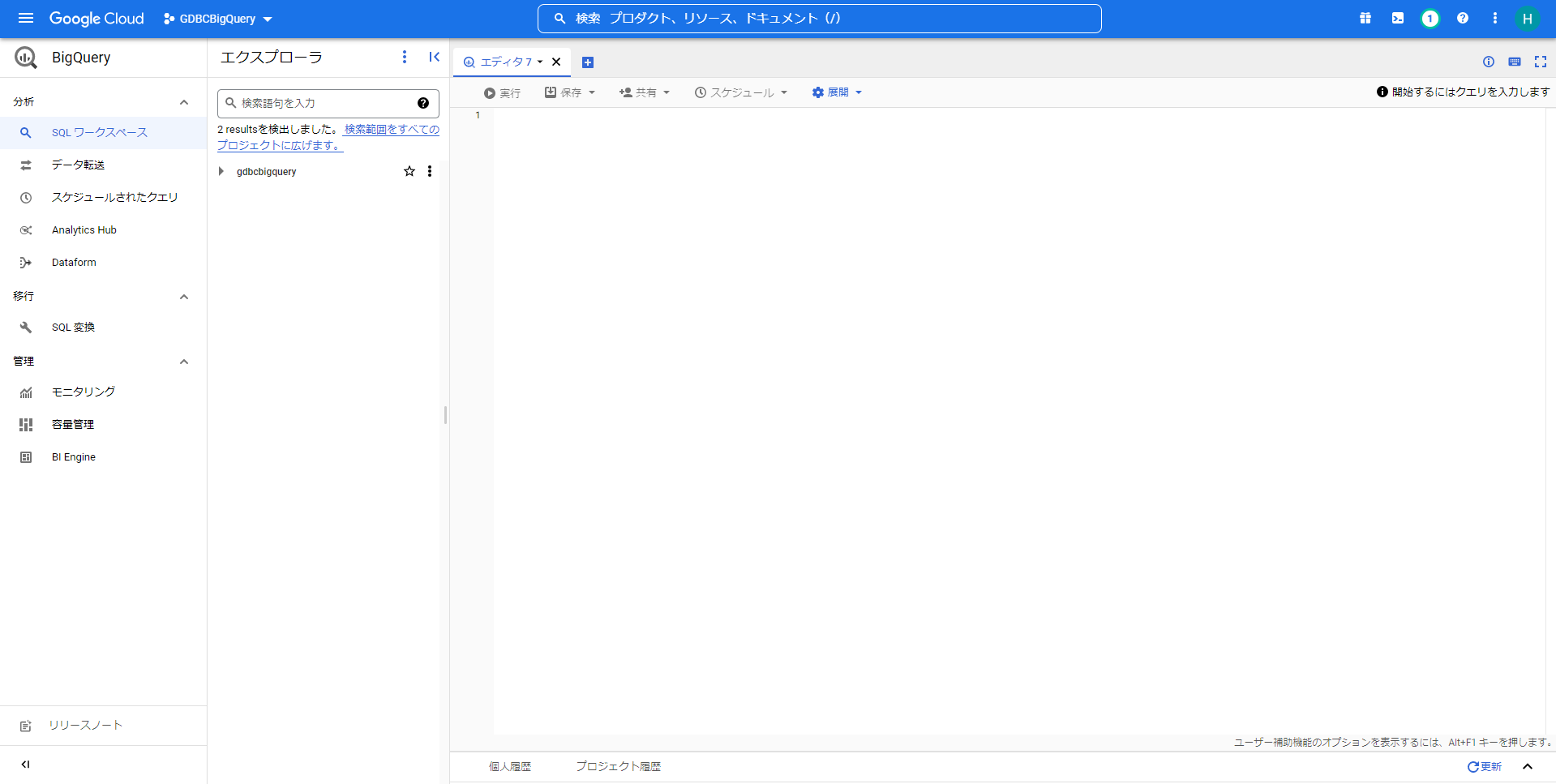
Google Cloudのプロジェクトの「アクション」から「データセットを作成」を押して、データセットの作成画面を開きます。
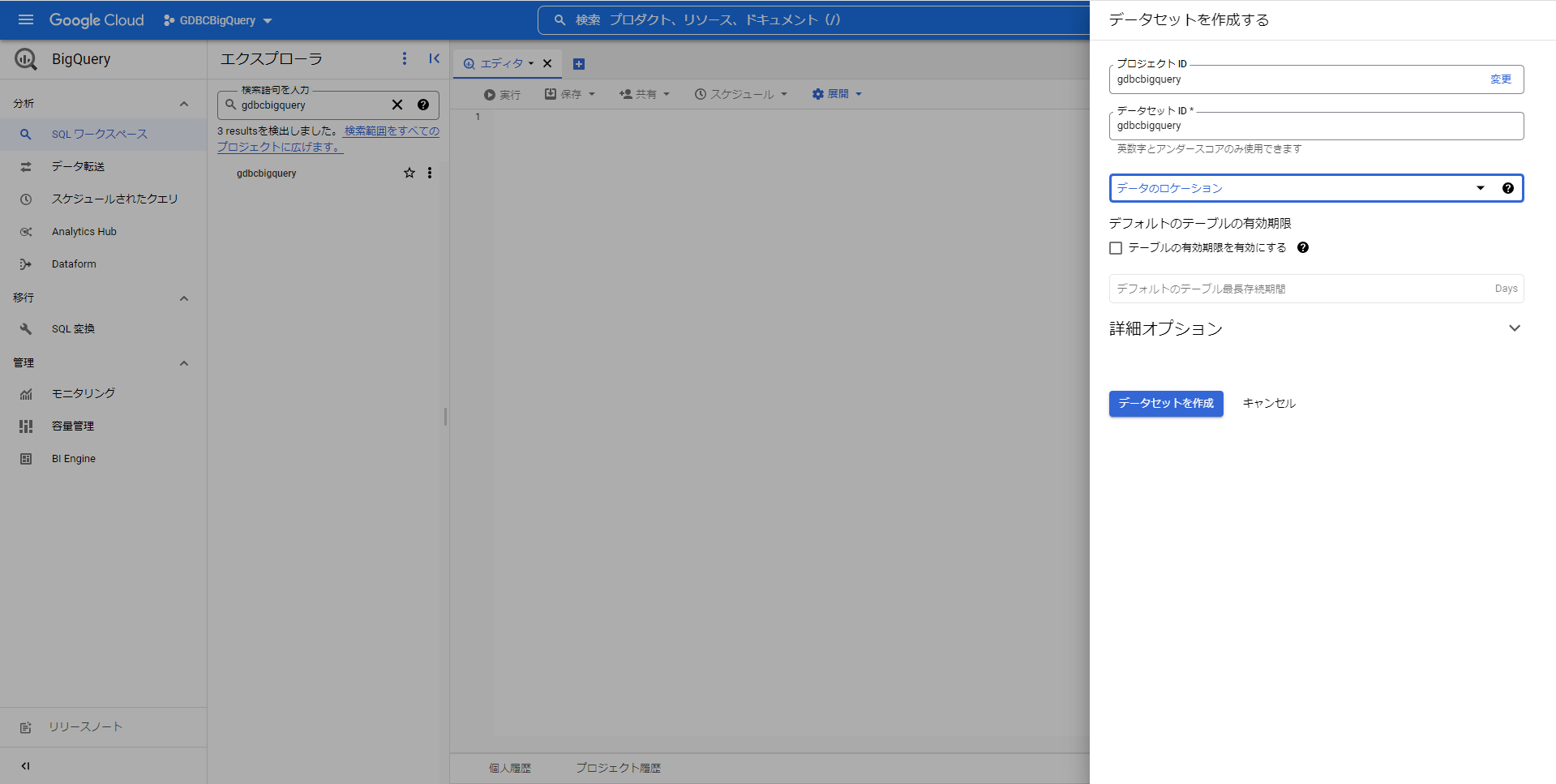
「データセットID」や「データのロケーション」など入力して、「データセットを作成」ボタンを押して、データセットを作成します。
- Google CloudのBigQueryでCloud Storageのファイルからテーブルを作成します。
作成したデータセットの「アクション」から「テーブルを作成」を選択して、テーブルの作成画面を開きます。
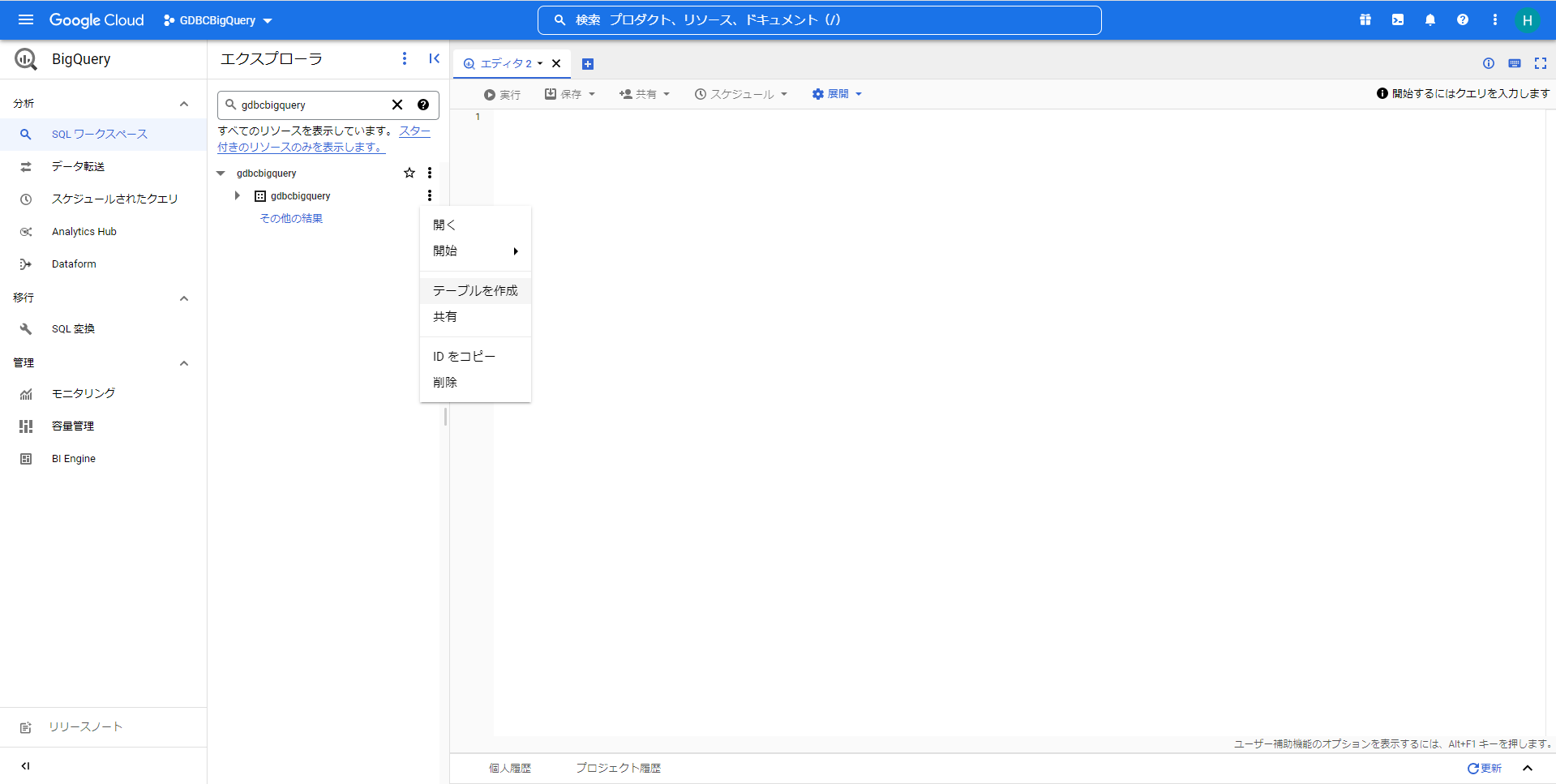
テーブルの作成画面で、以下をそれぞれ記載します。
テーブルの作成元
「Google Cloud Storage」を選択します。GCSバケットからファイルを選択するか、URIパターンを使用
Google Cloudのバケットから「GridDB Cloudからエクスポートしたファイルの転送手順」で転送したファイルを選択します。テーブル
作成するテーブル名を記載します。スキーマ
「自動検出」にはチェックを入れずに、「+」で「フィールドを追加」し、「フィールド名(カラム名)」と「タイプ(カラム型)」、「モード(NULLABLE)」などを設定します。 GridDB CloudとBigQuery間のカラム型については「GridDB CloudとBigQueryのデータ型のマッピング」を参照してください。詳細オプション
「スキップするヘッダー行」に「4」を設定します。
その他の設定は適宜用途に合わせて設定してください。設定が完了したら「テーブルを作成」ボタンを押して、テーブルを作成します。
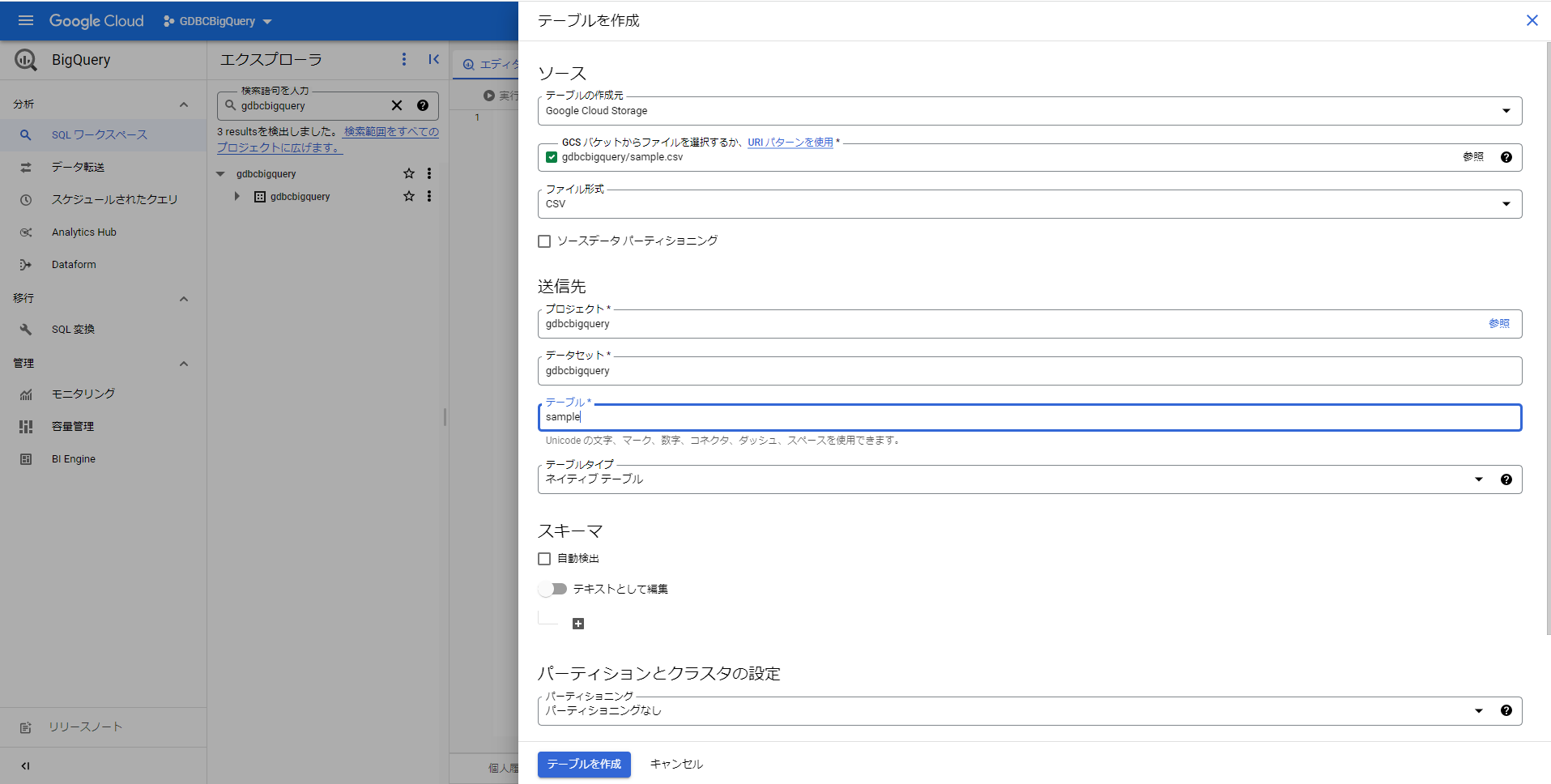
テーブル作成に成功するとテーブルが作成された旨がメッセージで表示されます。
以上で、BigQueryのテーブル作成は完了です。
3.4 BigQueryのテーブルへのデータ追加手順
BigQueryの作成済みテーブルへのデータ追加手順について説明します。
- BigQueryのテーブルにデータを追加します。
「Google Cloud StorageからBigQueryのテーブル作成手順」で作成したデータセットの「アクション」から「テーブルを作成」を選択して、テーブルの作成画面を開きます。
テーブルの作成画面で、以下をそれぞれ記載します。
テーブルの作成元
「Google Cloud Storage」を選択します。GCSバケットからファイルを選択するか、URIパターンを使用
Google Cloudのバケットからデータを追加するファイルを選択します。 ※追加するデータのデータ型、スキーマは作成済みのテーブルと一致する必要があります。テーブル
作成済みテーブルのテーブル名を記載します。スキーマ
「自動検出」にチェックを入れます。
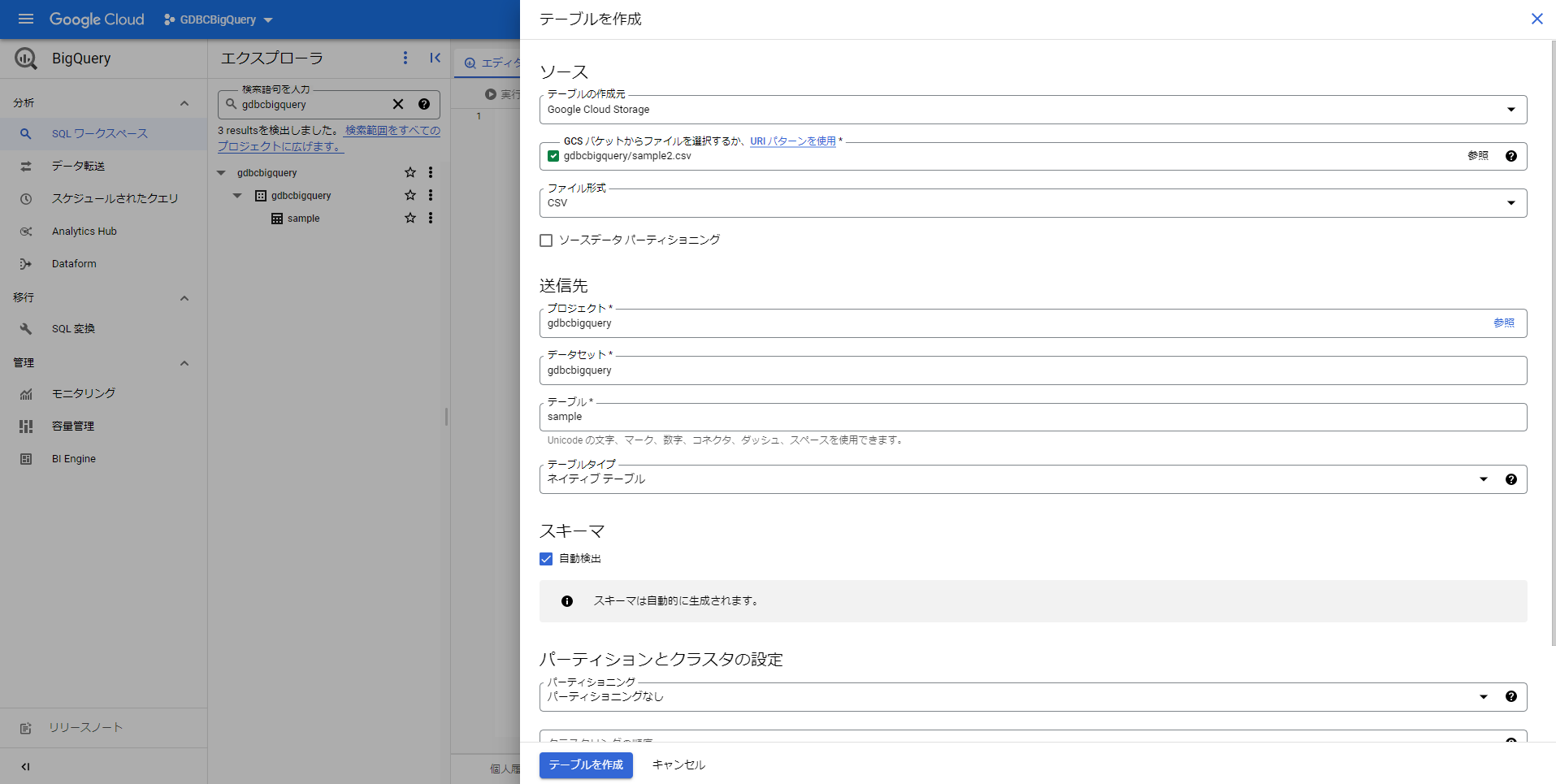
- 詳細オプション
「書き込み設定」で「テーブルに追加する」を選択します。
GridDB Cloudの定期エクスポートで出力したファイルを追加する場合は、「スキップするヘッダー行」に「4」を設定します。
その他の設定は適宜用途に合わせて設定してください。設定が完了したら「テーブルを作成」ボタンを押して、データを追加します。
テーブルへのデータ追加が成功するとテーブルが作成された旨がメッセージで表示されます。
以上で、BigQueryのテーブルへのデータ追加は完了です。
3.5 BigQueryのテーブルへの定期データ追加手順
- GridDB Cloudからエクスポートしたファイルを定期的にGoogle CloudのCloud Storageに転送します。
(GridDB CloudとBigQueryとの連携手順の図:②)の定期実行
「3.2 GridDB Cloudからエクスポートしたファイルの転送手順」の「2. Google CloudのData TransferでファイルをCloud Storageに転送します。」の「 ④ジョブを実行する方法とタイミングを選択する」の設定で、転送のジョブの実行のタイミングを設定します。
- Cloud Storageからファイルのデータを定期的にBigQueryのテーブルに転送します。
(GridDB CloudとBigQueryとの連携手順の図:③)の定期実行
Google Cloudのコンソール上で「BigQuery」を選択して、BigQueryのエクスプローラーを開きます。
左のタブから「分析/データ転送」を選択して、「データ転送」(Data Transfer Service)の一覧画面を開きます。
![]()
「転送を作成」ボタンを押して、転送ジョブを作成します。
ソース
「Google Cloud Storage」を選択します。転送構成名
転送ジョブ名を設定します。スケジュールオプション
繰り返しの頻度を設定します。用途に合わせて適宜設定してください。データセット
「Google Cloud StorageからBigQueryのテーブル作成手順」で作成したデータセット名を設定します。データソースの詳細/Destination table
「Google Cloud StorageからBigQueryのテーブル作成手順」で作成したテーブル名を設定します。データソースの詳細/Cloud Storage URI
転送対象とするCloud Storageのバケットを設定します。「Delete source files after transfer」
一度転送したファイルを重複して読み込むことを避けたい場合にチェックを入れます。
チェックを入れた場合、転送したファイルは転送元のCloud Storageから削除されます。Header rows to skip
「Header rows to skip」に「4」を設定します。Allow quoted newlines
「Allow quoted newlines」にチェックを入れます。
![]()
その他、用途に合わせて設定を行います。
「保存」ボタンを押して、転送ジョブを作成します。
以上で、定期的にデータを転送するジョブ作成が完了です。
4 GridDB CloudとBigQueryのデータ型のマッピング
GridDB CloudとBigQueryのデータ型のマッピングを下記の表に示します。
| GridDB データ型 | BigQueryデータ型 |
|---|---|
| BOOL | BOOLEAN |
| STRING | STRING |
| BYTE | INTEGER |
| SHORT | INTEGER |
| INTEGER | INTEGER |
| LONG | INTEGER |
| FLOAT | FLOAT |
| DOUBLE | FLOAT |
| TIMESTAMP | TIMESTAMP |
上記以外のデータ型についてはサポート対象外となります。
5 制限事項
1時間で処理可能なコンテナ数は100コンテナです。
④ジョブを実行する方法とタイミングを選択するの設定で、転送の間隔が1時間の場合、1時間で処理可能なコンテナ数は100コンテナ以下です。1日で転送可能なトータルのデータ量は1GB以下です。
GridDB Cloudからエクスポートしたファイルの転送手順で、ファイル転送は、1GBの範囲内なら何回でも可能ですが、転送可能なデータ量は1日トータル1GB以下です。