GridDB データベース管理者ガイド
Revision: 5.7.0-932
1 はじめに
本書はGridDBの提供する設計・構築・運用について説明したものです。
本書は、GridDBを用いたシステム開発を行う設計者、GridDBの運用管理を行う管理者の方を対象としています。
本書は、以下のような構成となっています。
概要
- GridDBの特徴と、設計・構築・運用に必要なGridDBアーキテクチャの概要について説明します。
物理設計
- システムの非機能要求を実装するために必要なGridDBの設計項目について説明します。
構築
- GridDBのインストールおよびアンインストールについて説明します。
運用
- 監視や障害発生時の対応など、運用管理を説明します。
2 概要
2.1 GridDBの特徴
GridDBは、高性能でかつ拡張性と可用性を備えた分散NoSQL型のデータベースで、以下の特徴があります。
■データモデルとサポートするインターフェース
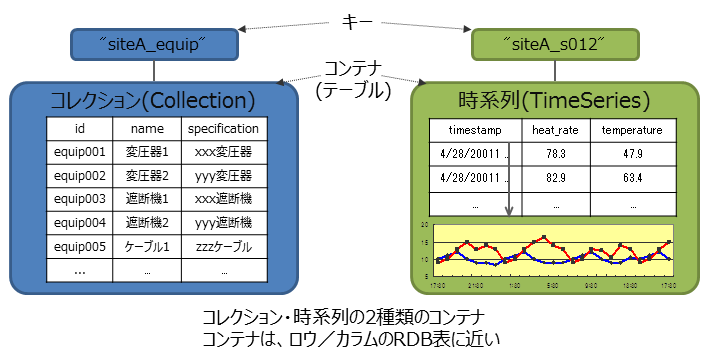
Key-Valueを発展させたデータモデルです。RDBのテーブルに相当するコンテナに対して、データを格納します。
NoSQLインターフェースのクライアントAPIやSQLライクなクエリ言語TQLだけでなく、NewSQLインターフェースとしてJDBC/ODBCやSQLも利用可能です。
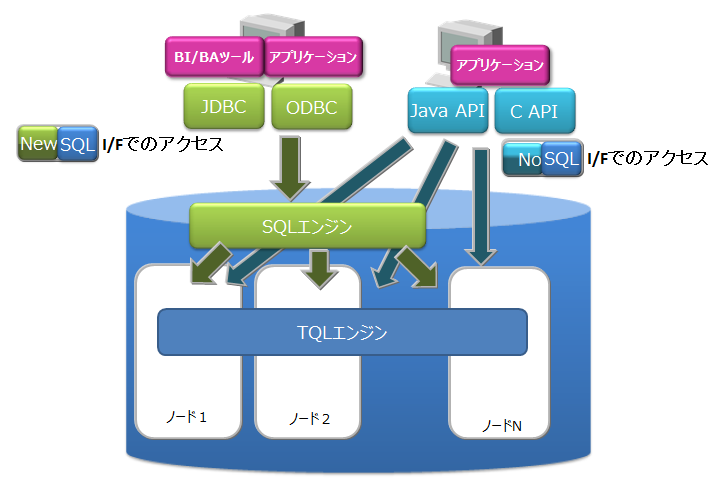
■可用性
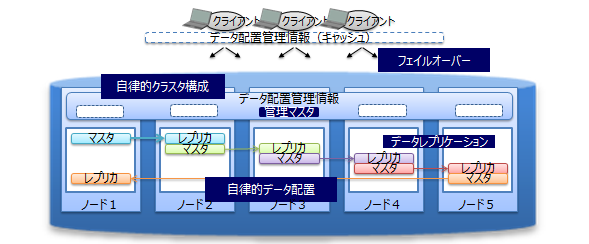
GridDBは、複数のノード(サーバプロセス)で構成されたクラスタで動作します。
ノードで障害が発生した場合、クラスタが自動的に障害を検知して、障害が発生したノードの役割を他のノードに移してクラスタの稼動を継続することができます。また、クラスタ内ではデータを複製して複数のノード上に多重配置(レプリケーション)しています。ノードに障害が発生した場合でも、クラスタが自動的にレプリカを再配置するため(自律的データ配置)、継続的にデータアクセスすることができます。
■拡張性
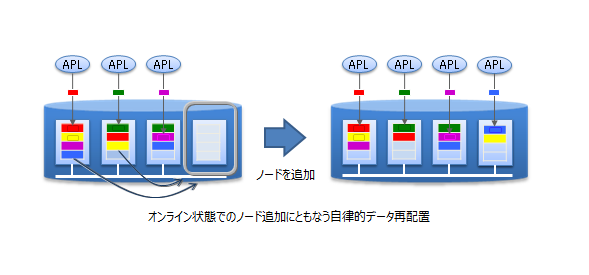
GridDBのクラスタの性能を向上させるには、ノードが稼働するサーバをスケールアップする方法だけでなく、クラスタにノードを追加するスケールアウトも選択することができます。
スケールアウトでのシステム拡張はオンラインで行うことができます。また、スケールアウトでシステムに追加したノードには、システムの負荷に応じて適切にデータが配置されるため、運用も容易です。
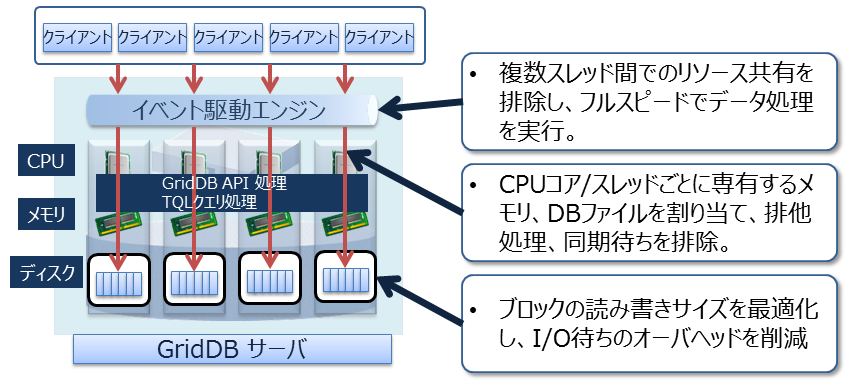
■高速性
データベースの実行待ちとなる時間をできるだけ少なくするために、GridDBでは、CPUコア・スレッドごとに専有するメモリとデータベースファイルを割当て、排他、同期処理の待ちをなくしています。
また、高速化のために、他にも以下の機能を持ちます。
- 索引機能
- テーブルパーティショニング
- データ圧縮
- 期限解放
- アフィニティ
詳細は、『GridDB 機能リファレンス』(GridDB_FeaturesReference.html)をご参照ください。
2.2 GridDBのアーキテクチャ概要
設計・構築・運用に必要なGridDBアーキテクチャの概要について説明します。
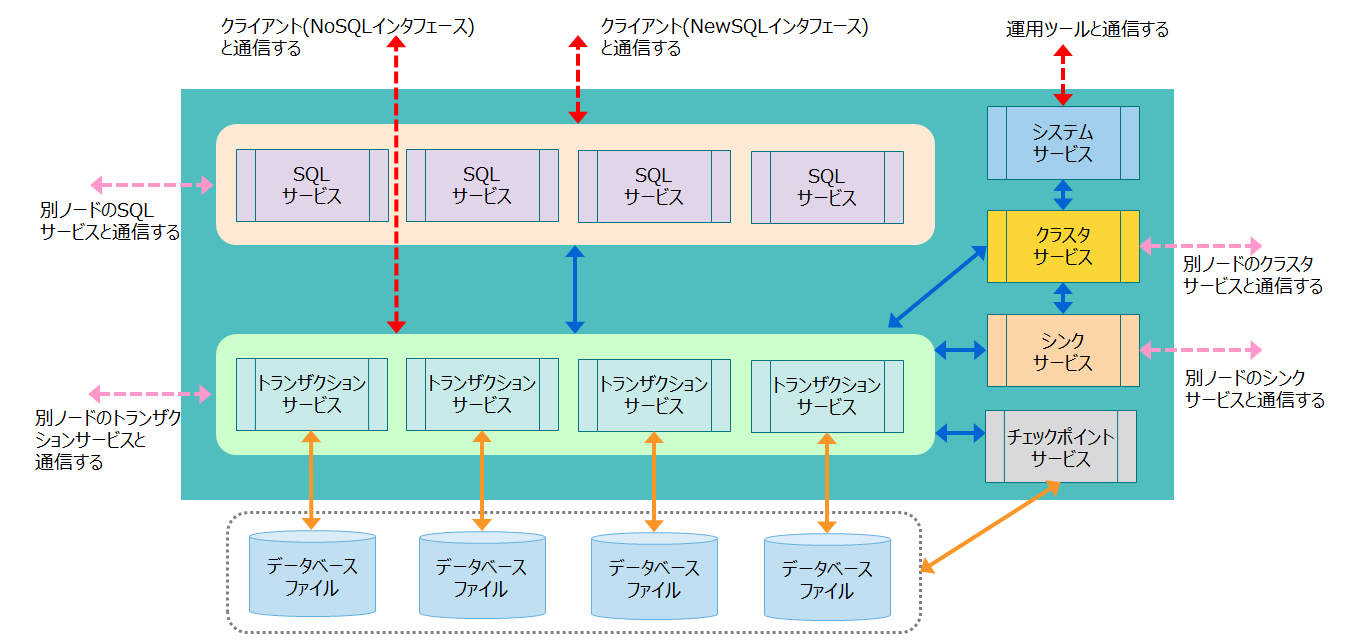
2.2.1 スレッド構成
ノードには、さまざまな処理を行うスレッド(サービスと呼びます)が複数存在します。ノードのスレッド構成と処理内容を説明します。
| スレッド名称 | スレッドの処理内容 |
|---|---|
| トランザクションサービス | ロウの登録、検索処理などのトランザクション処理や、データベースファイル書き込み処理などを行う |
| チェックポイントサービス | チェックポイント処理を行う |
| クラスタサービス | ハートビートや、ノードの参加・離脱などのクラスタ構成処理を行う |
| シンクサービス | パーティション再配置の際にデータ同期のための長期同期、短期同期処理を行う |
| システムサービス | 運用管理操作の要求を受け付ける |
| SQLサービス | SQL処理を行う |
クライアントからの処理の流れ
- NoSQLクライアントからの処理要求は、トランザクションサービスに処理が割り当てられ、ロウの登録、検索処理などを行います。
- NewSQLクライアントからの処理要求は、一度SQLサービスがSQL処理を行ってから、トランザクションサービスに処理を割当てます。
2.2.2 データ管理
データを管理するデータベースファイルとトランザクションサービスは、一対一の関係にあります。
このデータベースファイルには、複数コンテナを管理するパーティションという内部構造があります。各トランザクションサービスは、ひとつのパーティションのみを操作するため、他のトランザクションサービスとの排他処理なく実行可能です。
2.2.3 ファイル構成
ノードが管理するファイルには、定義ファイルやデータベースファイルなどのファイルがあります。ファイルの構成と内容について説明します。
定義ファイル
名前 内容 ノード定義ファイル
(gs_node.json)ノードのリソースや動作を設定する定義ファイルです。 クラスタ定義ファイル
(gs_cluster.json)クラスタ構成のためのリソースや動作を設定する定義ファイルです。 ユーザ定義ファイル
(password)管理ユーザを登録するファイルです。 データベースファイル
名前 内容 データファイル データを格納するファイルです。
データファイルは複数に分割して配置することも可能です。
○ファイル数
・パーティションごとにファイルを1つ作成します。
・データファイルを分割して配置する場合は、パーティションごとに分割数分のファイルを作成します。チェックポイントログファイル データベースのブロック管理情報を格納するファイルです。
チェックポイントのタイミングで、ブロック管理情報の書き込みを分割で行います。
パーティションごとにファイルをデフォルトで最大10個作成します。ノード定義ファイルの/checkpoint/partialCheckpointIntervalで調整できます。トランザクションログファイル トランザクションログを格納するファイルです。
ひとつのファイルには、前回のチェックポイント開始から次のチェックポイント開始までに実行されたトランザクションログを格納します。
パーティションごとにファイルをデフォルトで最大3個(現在のログファイルと過去2世代分のログファイル)作成します。その他のファイル
名前 内容 バックアップファイル オンラインバックアップを開始した時に作成されるファイルです。バックアップしたデータベースファイルやバックアップ情報のファイルを総称してバックアップファイルと呼びます。 イベントログファイル ノードの動作ログを格納するファイルです。エラーや警告などのメッセージが出力されます。 監査ログファイル ノードの監査ログを格納するファイルです。アクセスログ、操作ログ、エラーログが出力されます。 同期処理用一時ファイル パーティション再配置による同期処理の時に、同期データを一時的に格納するためのファイルです。 SQL中間結果用スワップファイル SQLの中間結果を一時的に格納するためのファイルです。ノード停止時にファイルは削除されます。
上記に説明したとおり、データベースファイルとして、パーティション単位に、データファイル、チェックポイントログファイル、トランザクションログファイルを持ちます。
更新に同期してデータをシーケンシャルにトランザクションログファイルに書き込むトランザクションログ処理により、トランザクション保証を行います。また、メモリ上の更新データをブロック単位にデータファイルとチェックポイントログファイルに定期的に保存するチェックポイント処理により、データの永続化を行います。
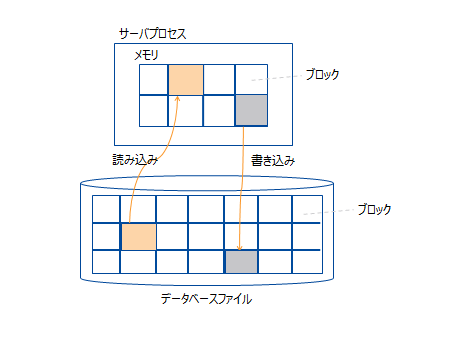
2.2.4 メモリ構造
GridDBは、ディスクI/Oを減らし、効率的に処理を行うために各種メモリエリアを持ちます。
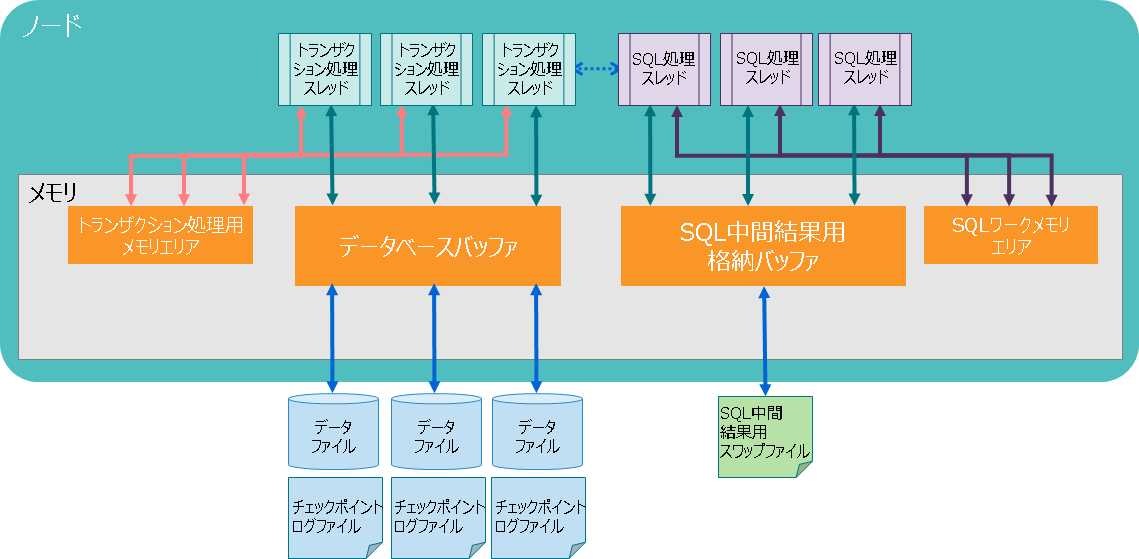
| 名称 | 内容 |
|---|---|
| データベースバッファ | 読み込んだデータをキャッシュするためのI/Oバッファです。 データファイルから読み込んだデータイメージ(ブロック)をメモリ上にキャッシュします。データベースバッファのサイズが大きい程、ブロックがメモリ上にキャッシュされやすくなるため検索および登録性能が向上します。 ノード上にデータベースバッファの領域はひとつで、複数のトランザクション処理スレッドが共有して使用します。 |
| トランザクション処理用メモリエリア | ロウの登録や検索処理などを行うトランザクション処理スレッドが使用する領域です。 |
| SQL中間結果格納バッファ | SQL処理中の中間結果を格納するための領域です。 中間結果がバッファのメモリサイズ上限を超える場合は、一時的にSQL中間結果用スワップファイルに書き出します。 |
| SQLワークメモリエリア | SQL処理において、ジョインや集計などの途中結果を一時的に格納するための領域です。 |
GridDBは、メモリとディスクの両方を用いるハイブリッド方式のデータベースです。 メモリをデータのキャッシュとして用いてアクセスを高速化し、データをディスクに格納して大容量データの管理を実現しています。メモリのサイズが大きい方がより多くのデータがメモリ上にキャッシュされるため、ディスクI/Oが減って性能が向上します。
2.2.5 クラスタ管理
GridDBは、複数のノードでクラスタを構成します。
ノードには「マスタ」と「フォロワ」という二つの役割があります。マスタはクラスタ全体の管理を行います。 マスタ以外のノードはすべて「フォロワ」になります。
クラスタが開始する時には、クラスタを構成するノードのひとつが必ず「マスタ」になり、フォロワはマスタからの指示に基づいて同期などのクラスタ処理を行います。マスタノードはGridDBが自動的に決定します。もしマスタノードに障害が発生した場合、フォロワノード群から新たなマスタを自動で決定してクラスタの稼動を継続します。
また、クラスタ内ではデータを複製して、複数のノード上にデータ(レプリカ)を多重配置します。レプリカの中で、マスタのデータをオーナ、複製したデータをバックアップと呼びます。クラスタを構成するいずれかのノードに障害が発生した場合でも、レプリカを使用することで処理を継続できます。ノード障害発生後のデータ再配置もシステムが自動的に行うため(自律的データ配置)、特別な運用操作は不要です。障害対象のノードに配置されていたデータはレプリカから復旧され、自動的に設定されたレプリカ数となるようにデータは再配置されます。
レプリカは、パーティション単位で作成します。クラスタにノード増設/削除を行った場合は、パーティションを自動で再割り当て・再配置することにより、各ノードにレプリカを分散配置します。
3 物理設計
システムの非機能要求を実装するために必要なGridDBの設計項目について説明します。
3.1 設計のポイント
システムで実現すべき非機能要求として、IPAにより「非機能要求グレード」が定義されています。以下にその一部を引用します。
非機能要求グレード2018 利用ガイド[解説編] 「非機能要求グレードの6大項目」より (c)2010-2018 独立行政法人情報処理推進機構
| 非機能要求 大項目 | 要求の例 | 実現方法の例 |
|---|---|---|
| 可用性 | ・運用スケジュール(稼働時間・停止予定など) ・障害、災害時における稼働目標 |
・機器の冗長化やバックアップセンターの設置 ・復旧・回復方法および体制の確立 |
| 性能・拡張性 | ・業務量および今後の増加見積り ・システム化対象業務の特性(ピーク時、通常時、縮退時など) |
・性能目標値を意識したサイジング ・将来へ向けた機器・ネットワークなどのサイズと配置=キャパシティ・プランニング |
| 運用・保守性 | ・運用中に求められるシステム稼働レベル ・問題発生時の対応レベル |
・監視手段およびバックアップ方法の確立 ・問題発生時の役割分担、体制、訓練、マニュアルの整備 |
| 移行性 | ・新システムへの移行期間および移行方法 ・移行対象資産の種類および移行量 |
・移行スケジュール立案、移行ツール開発 ・移行体制の確立、移行リハーサルの実施 |
| セキュリティ | ・利用制限 ・不正アクセスの防止 |
・アクセス制限、データの秘匿 ・不正の追跡、監視、検知 ・運用員などへの情報セキュリティ教育 |
これらの非機能要求を満たすために必要なGridDBの設計項目は、以下になります。
- データ領域の設計
- メモリ領域の設計
- コンテナ設計
- クラスタ構成設計
- ネットワーク設計
- セキュリティ設計
- 監視設計
- バックアップ設計
設計内容は、システム要件のレベルや内容によって大きく変わりますが、GridDBの特徴である可用性および性能・拡張性を生かすために考慮すべき設計ポイントを中心に説明します。
3.2 データ領域の設計
GridDBのデータは、ブロック、コンテナ、テーブル、ロウ、パーティションという単位でデータ管理されています。これらのデータ領域の設計は、可用性および性能・拡張性を決める重要な要因となります。
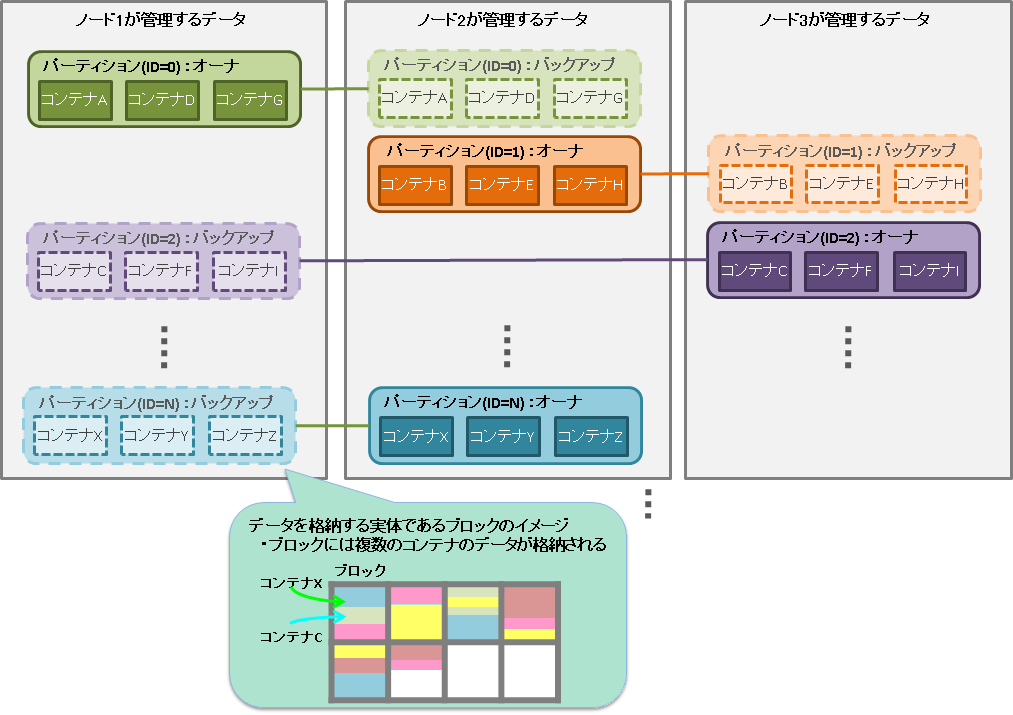
ブロックとコンテナの関係
- ブロックはデータ管理の最小単位でありブロックにコンテナのロウデータやメタ情報を格納します。ブロックには複数コンテナのデータが格納されます。
コンテナとパーティションの関係
- コンテナが所属するパーティションは、コンテナの名前から算出したハッシュ値によってクラスタが決定します。コンテナとパーティションの関係は恒久的なものであり、コンテナ作成時にパーティションが決定した後は変わりません。
パーティションとノードの関係
- パーティションは、クラスタ間でのデータ配置の単位です。パーティションの配置は、クラスタが自動的に決定します。パーティションとノードの関係は流動的なものであり、障害発生時の自律的データ配置によって、パーティションは別のノードに移動することがあります。
同一パーティション上のコンテナへのアクセス
- 同じパーティションに属するコンテナ群への操作は、ひとつの処理スレッド(トランザクションサービス)が処理します。そのため、これらのコンテナ群に対する操作は逐次実行になります。
[メモ]
- ノードアフィニティ機能を使用すると、関連の強いコンテナを同じパーティションに強制的に格納することができます。GridDBのSQLのテーブルのジョイン時にクラスタの別ノードに配置されたテーブルのネットワークアクセスでの負荷を減少させることができます。
下記項目の設計ポイントについてまとめます。
- ブロックサイズ
- パーティション数
- 処理スレッド数(トランザクションサービス、SQLサービス)
- チェックポイント処理
- ファイル構成
3.2.1 ブロックサイズ
ブロックとは、コンテナのロウデータやメタ情報などを格納するための物理的なデータ単位であり、GridDBのディスクI/Oの最小単位です。
ブロックのサイズは64KB、1MB、4MB、8MB、16MB、32MBから選択します。デフォルトは64KBで、通常はデフォルト値のままで変更不要です。
ただし、ブロックサイズにより、コンテナのカラム数の上限値が異なります。ブロックサイズ64KBの場合のカラム数の上限値より多くのカラムを作成する場合は、ブロックサイズを変更してください。上限値の詳細は『GridDB 機能リファレンス』(GridDB_FeaturesReference.html)の「システムの制限値」をご参照ください。
■ブロックに格納するデータ
ブロックに格納するデータは、ロウのデータやコンテナのメタ情報、索引データなどの種類があります。データの種類ごとに分類してブロックに格納します。
| ブロック種別 | 説明 |
|---|---|
| metaData | コンテナのメタ情報を格納するブロック |
| rowData | コンテナ(期限解放設定なし)のロウのデータを格納するブロック |
| mapData | コンテナ(期限解放設定なし)の索引のデータを格納するブロック |
| batchFreeRowData | コンテナ(期限解放設定あり)のロウのデータを格納するブロック |
| batchFreeMapData | コンテナ(期限解放設定あり)の索引のデータを格納するブロック |
また、ひとつのブロックには、複数のコンテナのデータを格納します。アプリケーションから登録・更新された順にブロックに格納します。時間または種類が近いデータをまとめてブロックに格納することで、データが局所化してメモリ効率が向上します。期間を条件とするような時系列データの検索処理を、少ないリソースで高速に行えます。
関連するパラメータ
●クラスタ定義ファイル(gs_cluster.json)
パラメータ 初期値 内容 起動後の変更 /dataStore/storeBlockSize 64KB ブロックサイズ 不可
[メモ]
- ノードの初期起動後は、ブロックサイズは変更できません。
- クラスタを構成する全ノードで同じブロックサイズを指定してください。
- 表の「起動後の変更」は、運用開始後にパラメータを変更できるかどうかを表します。
- 不可:ノードを一度でも起動した後は、変更することができません。変更するためにはデータベースファイルの初期化が必要になります。
- データアフィニティ機能を利用して各ブロックに関連性の強いデータのみを格納することで、データアクセスの局所化を図り、メモリヒット率を高めることができます。
- また、データアフィニティ機能のヒント情報に文字列「#unique」を指定すると、コンテナ単位にブロックを占有してデータを配置することができます。コンテナ単位のスキャンや、データ削除を高速化することができます。
- データアフィニティの詳細は、『GridDB 機能リファレンス』(GridDB_FeaturesReference.html)をご参照ください。
3.2.2 パーティション数
クラスタ上のデータ管理の仕組みとして、コンテナをパーティションと呼ぶデータの入れ物で管理します。
- コンテナは必ずひとつのパーティションに属し、パーティションは複数のコンテナを格納します。
- トランザクションサービスとデータベースファイルには、パーティション単位でコンテナを割り当てます。
パーティション数のデフォルトは128です。通常はデフォルト値のままで変更不要ですが、以下の条件式を満たさない場合はパーティション数を増やす必要があります。
パーティション数 >= トランザクションサービスの並列度 × クラスタの構成ノード数
- 条件式を満たさない場合、パーティションが割当たらないトランザクションサービスが出来てしまいます。そのため、上記の式を満たすようにパーティション数を設定してください。
- 例) 並列度32でノード数5の場合
- パーティション数128(デフォルト)では条件式を満たさない:128 < (32 × 5=160)
- パーティション数は160以上に設定してください。
- 例) 並列度32でノード数5の場合
関連するパラメータ
●クラスタ定義ファイル(gs_cluster.json)
パラメータ 初期値 内容 起動後の変更 /dataStore/partitionNum 128 パーティション数 不可 ■ノード定義ファイル(gs_node.json)
パラメータ 初期値 内容 起動後の変更 /dataStore/concurrency 4 トランザクション処理スレッドの並列度 可(ノード再起動)
[メモ]
- 表の「起動後の変更」は、運用開始後にパラメータを変更できるかどうかを表します。
- 不可:ノードを一度でも起動した後は、変更することができません。変更するためにはデータベースファイルの初期化が必要になります。
- 可(ノード再起動):パラメータを記載している定義ファイルを書き換えて、ノードを再起動すると変更できます。
3.2.3 処理スレッド数
GridDBノードは1つのプロセスから構成されています。プロセス内にはさまざまな処理を行うスレッド(サービスと呼びます)が複数存在します。
ここでは、サービスの中で「トランザクションサービス」と「SQLサービス」の並列度を決定します。
| スレッド名称 | スレッド数 (デフォルト) |
スレッドの処理内容 |
|---|---|---|
| トランザクションサービス | 4 (設定可) | ロウの登録、検索処理などのトランザクション処理や、データベースファイル書き込み処理などを行う |
| チェックポイントサービス | 1 | チェックポイント処理を行う |
| クラスタサービス | 1 | ハートビートや、ノードの参加・離脱などのクラスタ構成処理を行う |
| シンクサービス | 1 | パーティション再配置の際にデータ同期のための長期同期、短期同期処理を行う |
| システムサービス | 1 | 運用管理操作の要求を受け付ける |
| SQLサービス | 4 (設定可) | SQL処理を行う |
各サービスが行う処理を「イベント」と言います。サービスはひとつのイベントキューを持ち、イベントキューに登録されたイベントを順次処理します。他のサービスに処理を依頼する時には、そのサービスが持つイベントキューにイベントを登録します。
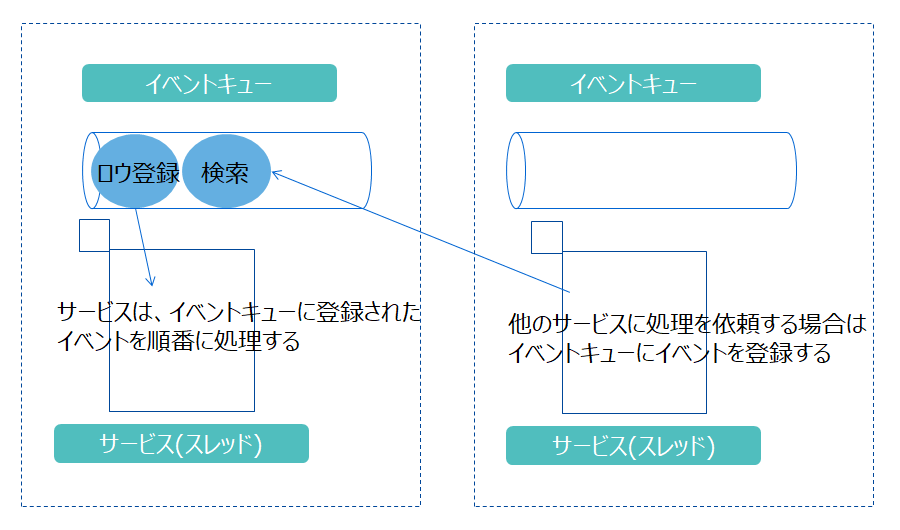
- スレッドの種類ごとに、イベントキューに登録できるイベントの種類が異なります。
- イベントキューに登録されたイベントは、そのスレッドで順番に処理します。並列実行されません。
- 実行中のイベントの情報は、運用ツールのgs_shで確認することができます。『GridDB 運用ツールリファレンス』(GridDB_OperationToolsReference.html)を参照してください。
[メモ]
- ノード定義ファイルでスレッド数を設定可能なのは、トランザクションサービスとSQLサービスのみです。
検索や登録の並列性能に特に影響するスレッドは、トランザクション処理を行うスレッド(トランザクションサービス)とSQLの処理を行うスレッド(SQLサービス)です。 ノードを稼動するマシンのCPUコア数に合わせて、これらの処理スレッドの並列度(concurrency)を設定します。
トランザクションサービスの並列度
トランザクションサービスは、ロウの登録・検索処理、データベースファイルへの書き込み処理などを行うスレッドです。
トランザクションサービスの並列度を増やすと、複数のコンテナへの並列アクセス性能が向上します。
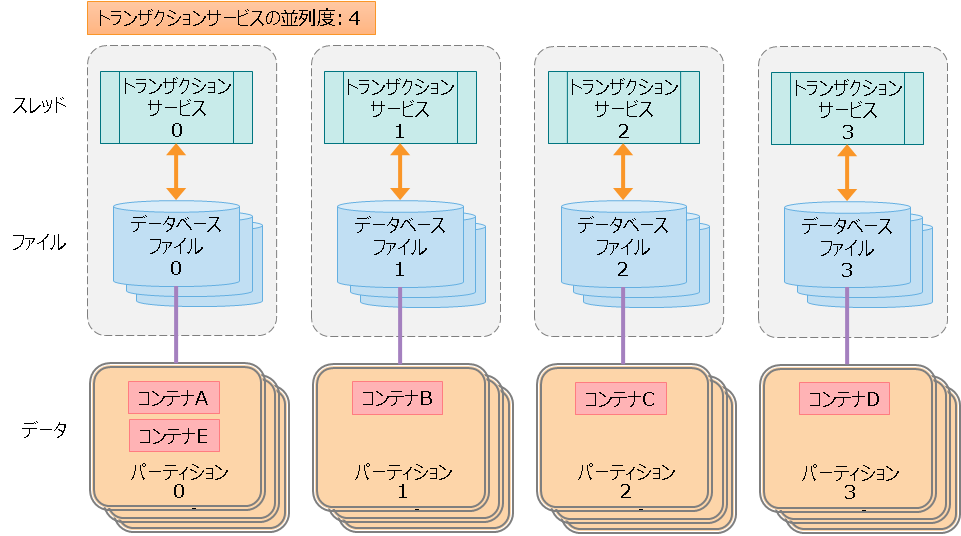
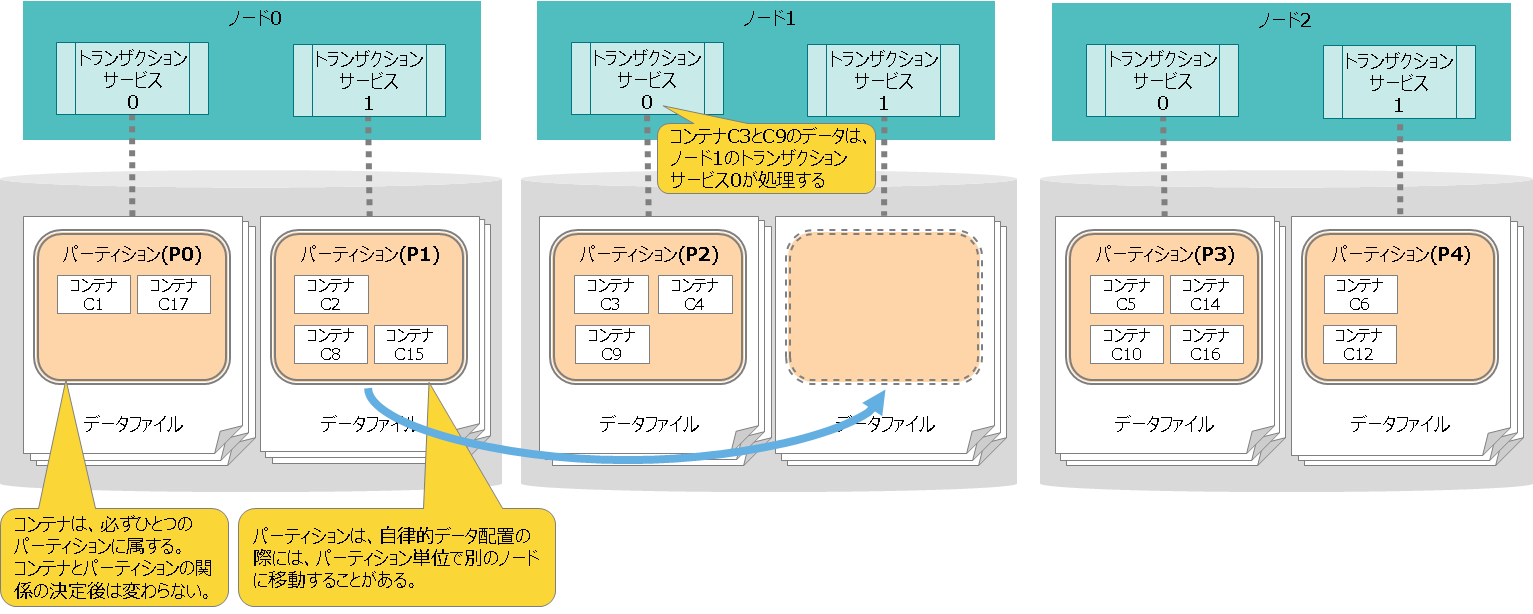
トランザクションサービス(スレッド)とデータベースファイル(ファイル)とコンテナ(データ)との関係は下図のように1対1対1になります。
- コンテナAのデータは、トランザクションサービス0が処理して、データベースファイル0に格納します。コンテナAのデータを、トランザクションサービス0と1が同時にアクセスすることはありません。
- データとスレッドとファイルのリソースを分離することで、リソースの排他やロック競合がなくなり、高速に処理できます。
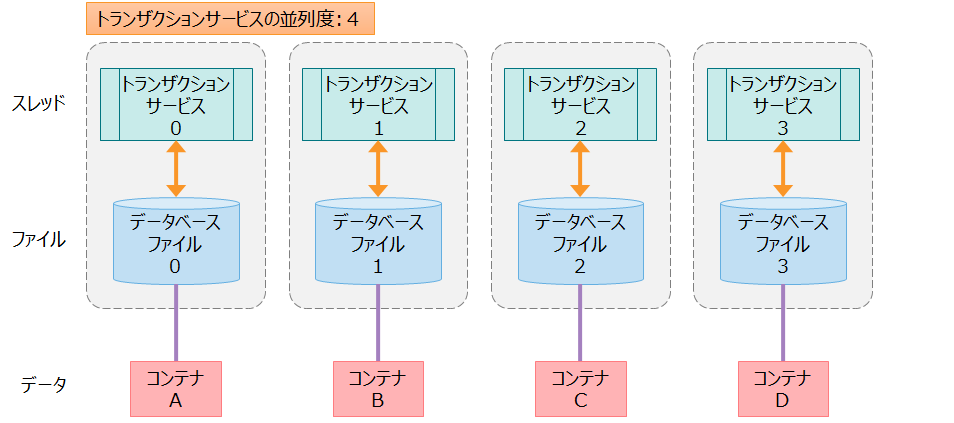
ひとつのノードが管理するデータ・スレッド・ファイルの関係
SQLサービスの並列度
- SQLサービスは、SQLの処理を行うスレッドです。
- SQLサービスは、トランザクションサービスのようなデータとファイルとの関係はありません。データベースファイルへのアクセスが必要な場合やその他トランザクション処理が必要な場合は、トランザクションサービス経由で行います。
並列度設定の目安は以下になります。
ノードを稼動するマシンのCPUコア数に合わせて、トランザクションサービスの並列度を大きくすることを推奨します。
- 並列度を増やすと、複数のコンテナへの並列アクセス性能が向上します。
- ただし、同一コンテナへの操作はひとつのスレッドが行うので、並列度を増やしても同一コンテナへの処理性能は向上しません。
トランザクションサービスとSQLサービスの並列度の合計が、マシンのCPUコア数を超えないことを推奨します。
- トランザクションサービスの並列度(/dataStore/concurrency) + SQLサービスの並列度(/sql/concurrency)
[メモ]
- トランザクションサービスおよびSQLサービスの並列度は、ノードの再起動で変更可能です。
関連するパラメータ
■ノード定義ファイル(gs_node.json)
パラメータ 初期値 内容 起動後の変更 /dataStore/concurrency 4 トランザクション処理スレッドの並列度 可(ノード再起動) /sql/concurrency 4 SQL処理スレッドの並列度 可(ノード再起動)
[メモ]
- 表の「起動後の変更」は、運用開始後にパラメータを変更できるかどうかを表します。
- 不可:ノードを一度でも起動した後は、変更することができません。変更するためにはデータベースファイルの初期化が必要になります。
- 可(ノード再起動):パラメータを記載している定義ファイルを書き換えて、ノードを再起動すると変更できます。
3.2.4 チェックポイント処理
チェックポイント処理は、データベースバッファ上の更新されたブロックをデータファイル、チェックポイントログファイルに書き込む処理です。
チェックポイント実行周期をパラメータで設定できます。通常は、パラメータはデフォルト値のままで変更は不要です。
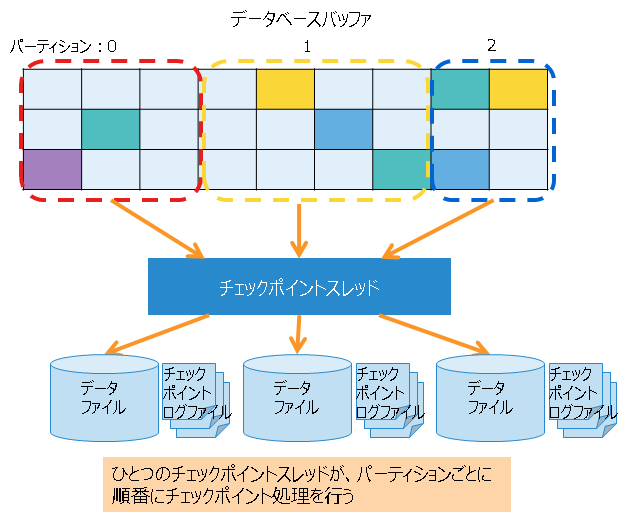
また、チェックポイント実行時、チェックポイントログファイルへブロック管理情報を分割で書き込みます。この分割数はパラメータで設定できますが、通常はデフォルト値のままで変更は不要です。設定値を大きくすることで、チェックポイントログファイルへの1回の書き込み量を減少させることができますが、ノード起動時のリカバリ時間が増える可能性があります。
チェックポイント処理は、以下のタイミングで実行されます。
| タイミング | 内容 |
|---|---|
| 定期 | 一定周期で自動的に実行する(周期はパラメータで指定。定期実行を一時的に無効に設定することもできる) |
| 手動 | ユーザがgs_checkpointコマンドを実行した時に実行する |
| ノード起動/停止 | ノード起動時のリカバリ処理の後、およびノードの通常停止の時に自動的に実行する |
| 長期同期開始/終了 | 長期同期処理を開始/終了する時に自動的に実行する |
データファイルの圧縮を指定することもできます。データファイルを圧縮することで、データ量に伴って増加するストレージコストを削減できます。データ圧縮の機能の詳細については『GridDB 機能リファレンス』(GridDB_FeaturesReference.html)の「データブロック圧縮」をご参照ください。
関連するパラメータ
■ノード定義ファイル(gs_node.json)
パラメータ 初期値 内容 起動後の変更 /checkpoint/checkpointInterval 60s チェックポイント実行周期 可(ノード再起動) /checkpoint/partialCheckpointInterval 5 チェックポイントログファイルへブロック管理情報を書き込む処理の分割数 可(ノード再起動) /dataStore/storeCompressionMode NO_COMPRESSION データファイル圧縮書き出し設定
圧縮しない:"NO_COMPRESSION"または0
圧縮する:"COMPRESSION"または1可(ノード再起動)
[メモ]
- 表の「起動後の変更」は、運用開始後にパラメータを変更できるかどうかを表します。
- 可(ノード再起動):パラメータを記載している定義ファイルを書き換えて、ノードを再起動すると変更できます。
3.2.5 ファイル構成
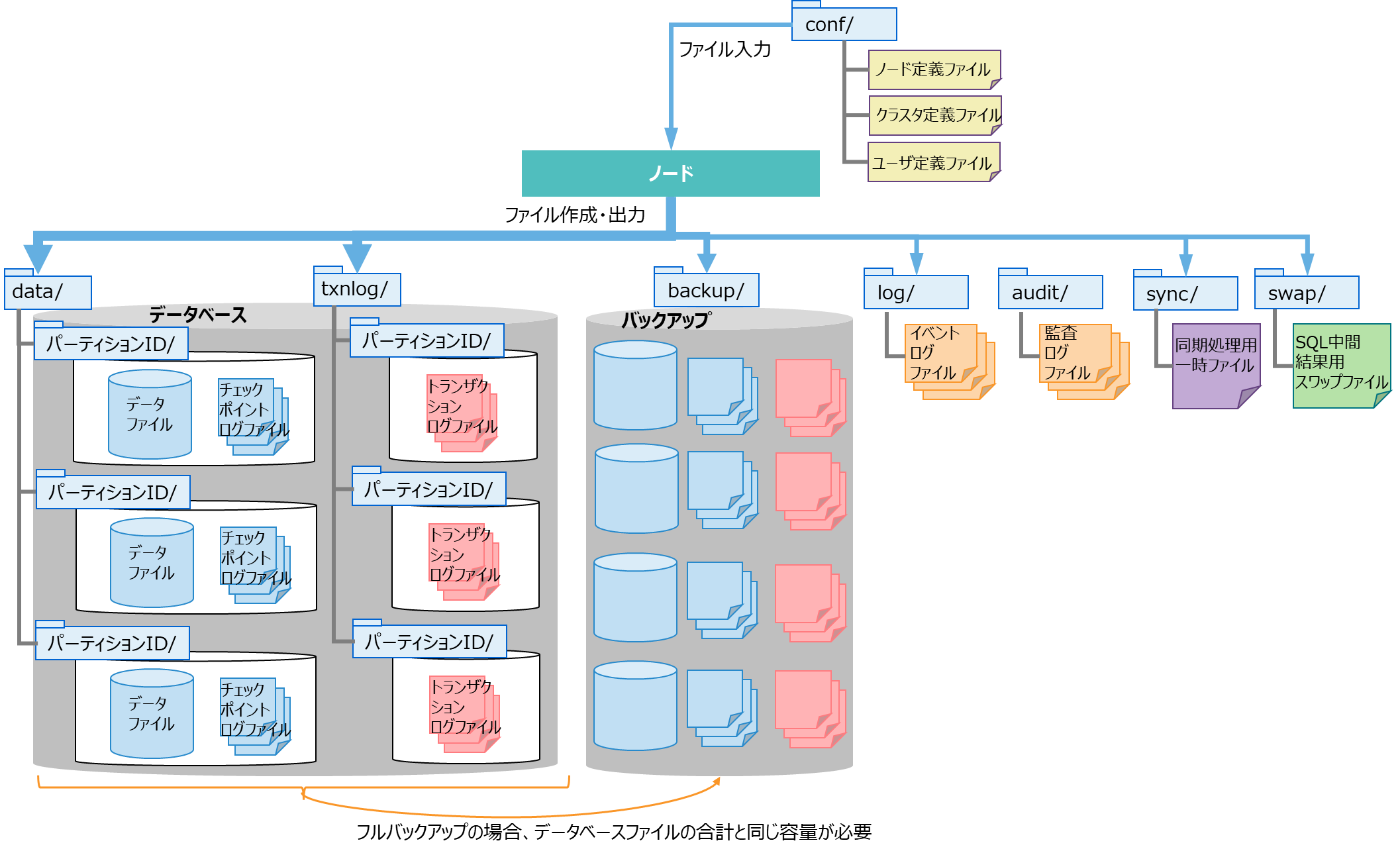
GridDBノードが稼働中に作成および出力するファイルには、データベースファイルやバックアップファイルなどの種類があります。
データベースファイルおよびバックアップファイルは、ファイルサイズが大きくなることやディスクI/Oが性能に大きく影響することから、ストレージの容量やI/O性能を考慮して適切な配置ディレクトリを指定してください。
配置ディレクトリは、デフォルトではGridDBホームディレクトリ(/var/lib/gridstore)下のディレクトリになります。
データベースファイルの配置ディレクトリ
- データファイル、チェックポイントログファイル、トランザクションログファイルを総称してデータベースファイルと呼びます。
- データファイル、チェックポイントログファイルの格納先として、DBディレクトリを指定します。また、トランザクションログファイルの格納先として、txnlogディレクトリを指定します。それぞれのディレクトリを別の物理ディスクに配置することで、ディスクに対する負荷分散が可能です。
- DBディレクトリ、txnlogディレクトリ以下に、パーティションID数分のディレクトリを自動で作成します。パーティションID数分作成されるディレクトリ毎に別の物理ディスクに配置することで、ディスクに対する負荷分散が可能です。
バックアップファイルの配置ディレクトリ
- ディスクの物理障害を考慮して、データベースファイルとは異なる物理ディスクに配置するように設定してください。
- フルバックアップを取ると、データベースファイルと同じ容量が必要になります。
出力ファイル一覧
データベースファイル
名前 内容 ファイル名 データファイル データを格納するファイルです。
○ファイル数
・デフォルトでは、パーティションごとにファイルを1つ作成します。
・設定により、データファイルを分割することも可能です。ノード定義ファイルの/dataStore/dbFileSplitCountで、データファイルの分割数を定義できます。
○ファイルサイズ
・ファイル内の空き容量が少なくなった場合は自動的にファイルサイズを拡張します。/<PartitionID>/<PartitionID>_part_<n>.dat
(n:0からの連番)チェックポイントログファイル データベースのブロック管理情報を格納するファイルです。
チェックポイントのタイミングで、ブロック管理情報の書き込みを分割で行います。
○ファイル数
パーティションごとにファイルをデフォルトで最大10個保持します。ノード定義ファイルの/checkpoint/partialCheckpointIntervalで調整できます。/<PartitionID>/<PartitionID>_<CheckpointNumber>.cplog トランザクションログファイル トランザクションログを格納するファイルです。
ひとつのファイルには、前回のチェックポイント開始から次のチェックポイント開始までに実行されたトランザクションログを格納します。
○ファイル数
・パーティションごとにファイルをデフォルトで最大3個(現在のログファイルと過去2世代分のログファイル)保持します。/<PartitionID>/<PartitionID>_<CheckpointNumber>.xlog その他のファイル
名前 内容 バックアップファイル オンラインバックアップを開始した時に作成されるファイルです。バックアップしたデータファイル、チェックポイントログファイル、トランザクションログファイル、およびバックアップ情報のファイルを総称してバックアップファイルと呼びます。 イベントログファイル ノードの動作ログを格納するファイルです。エラーや警告などのメッセージが出力されます。 監査ログファイル ノードの監査ログを格納するファイルです。アクセスログ、操作ログ、エラーログが出力されます。 同期処理用一時ファイル パーティション再配置による同期処理の時に、同期データを一時的に格納するためのファイルです。 SQL中間結果用スワップファイル SQLの中間結果を一時的に格納するためのファイルです。ノード停止時にファイルは削除します。
関連するパラメータ
■ノード定義ファイル(gs_node.json)
ディレクトリパスが相対パスの場合の起点は、GridDBホームディレクトリになります。
パラメータ 初期値 内容 起動後の変更 /dataStore/dbPath data データファイル、チェックポイントログファイル配置ディレクトリ 可(ノード再起動) /dataStore/transactionLogPath txnlog トランザクションログファイル配置ディレクトリ 可(ノード再起動) /dataStore/backupPath backup バックアップファイル配置ディレクトリ 可(ノード再起動) /dataStore/syncTempPath sync 同期処理用一時ファイル配置ディレクトリ 可(ノード再起動) /system/eventLogPath log イベントログファイル配置ディレクトリ 可(ノード再起動) /trace/auditLogsPath audit 監査ログファイル配置ディレクトリ 可(ノード再起動) /sql/storeSwapFilePath swap SQL中間結果用スワップファイル配置ディレクトリ 可(ノード再起動) /dataStore/dbFileSplitCount なし データファイルの分割数。
例) データファイルの分割数=4の場合
データファイルはパーティションごとに4分割され、/<PartitionID>/<PartitionID>_part_0.dat ~ /<PartitionID>/<PartitionID>_part_3.datを作成不可
[メモ]
表の「起動後の変更」は、運用開始後にパラメータを変更できるかどうかを表します。
- 不可:ノードを一度でも起動した後は、変更することができません。変更するためにはデータベースファイルの初期化が必要になります。
- 可(ノード再起動):パラメータを記載している定義ファイルを書き換えて、ノードを再起動すると変更できます。
監査ログファイルを配置するディレクトリ(audit)はデフォルト設定では作成されません。監査ログ機能を有効にした場合のみ作成されます。
3.3 メモリ領域の設計
GridDBは、メモリとディスクの両方を用いるハイブリッド方式のデータベースです。 メモリをデータのキャッシュとして用いてアクセスを高速化し、データをディスクに格納して大容量データの管理を実現しています。
下図のように、メモリのサイズが大きい方がより多くのデータがメモリ上にキャッシュされるため、ディスクI/Oが減って性能が向上します。 メモリサイズの大きさはGridDBの性能に大きく影響するため、システムの性能要件やデータ量を考慮して設計を行います。
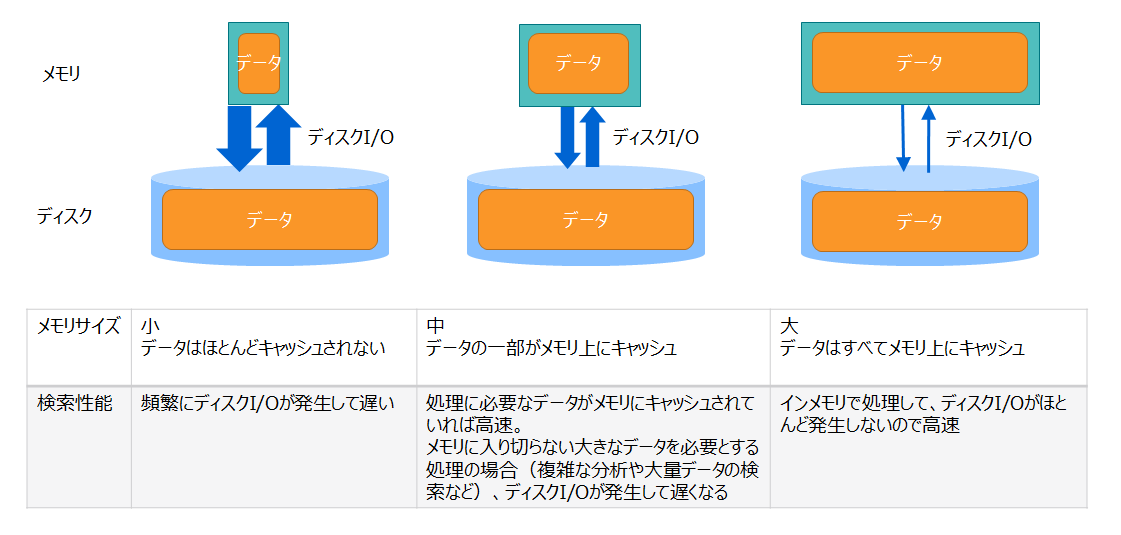
GridDBノードには、用途に応じて様々なバッファやメモリエリアがあります。主なメモリは以下の通りです。
| 名称 | 内容 |
|---|---|
| データベースバッファ | 読み込んだデータをキャッシュするためのI/Oバッファです。 データファイルから読み込んだデータイメージ(ブロック)をメモリ上にキャッシュします。データベースバッファのサイズが大きい程、ブロックがメモリ上にキャッシュされやすくなるため検索および登録性能が向上します。 ノード上にデータベースバッファの領域はひとつで、複数のトランザクション処理スレッドが共有して使用します。 |
| トランザクション処理用メモリエリア | ロウの登録や検索処理などを行うトランザクション処理スレッドが使用する領域です。 |
| SQL中間結果格納バッファ | SQL処理中の中間結果を格納するための領域です。 中間結果がバッファのメモリサイズ上限を超える場合は、一時的にSQL中間結果用スワップファイルに書き出します。 |
| SQLワークメモリエリア | SQL処理において、ジョインや集計などの途中結果を一時的に格納するための領域です。 |
メモリ領域の設計では、各メモリ領域の上限サイズや関連するパラメータの値を設計する必要があります。特にポイントとなるのが「データベースバッファ」と「SQL処理用メモリエリア」のメモリサイズです。

システムの性能に最も影響がでるのは「データベースバッファ」のサイズです。 物理メモリの容量に余裕があれば、このバッファに出来るだけ多くサイズを割り当てることを推奨します。
GridDBに格納するデータの特性から、頻繁に使うもの/使わないものを分類する
多くの場合、時系列データの経過時間による分類を行うと良い
例
- 頻繁に使うもの→直近1時間のセンサーデータ
- 頻繁に使わないもの→1年前のデータ
- 1年分のデータを格納しているが、通常業務で検索する範囲は直近の1ヶ月分のデータ
- 5つの工場の生産データを格納しているが、高速に検索する必要があるのは1つの工場のみ
そのため、一番性能が必要な処理が使うデータの種類と期間を調査します
頻繁に使うデータが入り切るようにデータベースバッファのサイズを設定する
SQL処理用メモリバッファのサイズについては、システムで使用する代表的なSQLクエリで評価を実施して、メモリサイズを設定してください。
必須の設計項目
使用するデータ量に合わせてバッファのサイズを決めます。
バッファ名 設計の目安 データベースバッファ 頻繁に検索する範囲のデータサイズを見積り、メモリサイズを設定する SQL関連のバッファ システムで使用するSQLのクエリで評価を実施してメモリサイズを設定する
必要に応じて変更する設計項目
運用状況に応じて、バッファのサイズを変更します。
バッファ名 変更が必要なケース トランザクション処理用メモリエリア TQLやSQLによる操作でメモリ不足エラー[CM_MEMORY_LIMIT]が発生する場合は、変更が必要
下記項目の設計ポイントについてまとめます。
- データベースバッファ
- トランザクション処理用メモリエリア
- SQL処理用メモリエリア
- その他のメモリ
3.3.1 データベースバッファ
データファイルから読み込んだブロックをメモリ上にキャッシュするための領域です。
データベースバッファのサイズが大きい程、データのブロックがメモリ上にあるため、検索および登録性能が向上します。
バッファのサイズ上限値は、ノード定義ファイルで指定します。 バッファの空きが無くなった時は、LRUで古いブロックをデータファイルに書き出して空き領域を作り、ファイルから残りのブロックを読み込みます。ファイルからの読み込み/ファイルへの書き込み処理をスワップ処理と呼びます。もし、ブロックが使用中で書き出せずに空き領域を作れない場合は、バッファサイズを一時的に拡張します。処理が終了して領域が不要になると、サイズ上限値まで縮小します。
バッファの内部は、パーティション単位で分割して使用します。パーティションごとのサイズは、データ量やアクセス状況に応じてノードが動的に決定します。
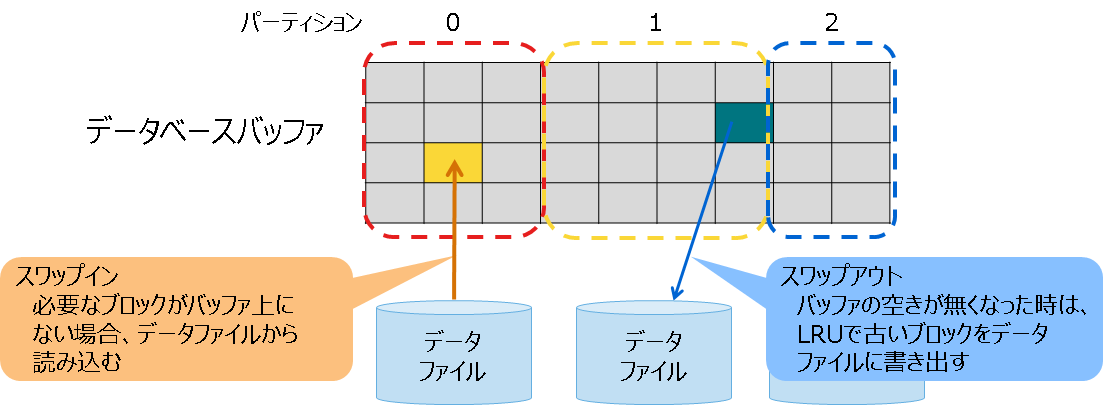
ノード起動直後は、データベースバッファに何もブロックが読み込まれていないため、起動直後の検索や登録処理では頻繁にブロックの読込みによるスワップ処理が発生して性能が遅くなる場合があります。
関連するパラメータ
■ノード定義ファイル(gs_node.json)
パラメータ 初期値 内容 起動後の変更 /dataStore/storeMemoryLimit 1024MB データベースバッファのサイズ上限値 可(オンライン) [メモ]
- サイズ上限値は、ノード起動中にオンラインでの変更も可能です。ただし、変更を永続化するためにはノードを停止して定義ファイルを書き換える必要があります。
- データベースバッファのサイズ上限については、GridDBが使用可能な物理メモリの60~70%を割り当ててください。運用開始後、スワップ処理の量を確認してください。スワップ処理が大量に発生している場合は、データベースバッファが足りずに性能が低下している可能性があります。メモリ増設とデータベースバッファサイズの上限値の見直しを検討してください。
- スワップ処理については、以下の「関連する情報の確認方法」でスワップ処理の読み込みと書き込みの情報を確認してください。
- 表の「起動後の変更」は、運用開始後にパラメータを変更できるかどうかを表します。
- 可(オンライン):ノード稼動中にオンラインでパラメータを変更できます。永続化するためには定義ファイルの書き換えが必要です。
関連する情報の確認方法
設定値や現在値の情報は、ノード稼働中に運用コマンドgs_statを実行して確認することができます。
gs_statのJSON形式の表示項目 設定値/現在値 内容 /performance/storeMemoryLimit 設定値 データベースバッファのサイズ上限値 (単位:バイト) /performance/storeMemory 現在値 データベースバッファの現在のサイズ (単位:バイト) /performance/swapRead 現在値 スワップ処理のファイルからの読み込み回数(累計) (単位:回数) /performance/swapReadSize 現在値 スワップ処理のファイルからの読み込みサイズ(累計) (単位:バイト) /performance/swapReadTime 現在値 スワップ処理のファイルからの読み込み時間(累計) (単位:ミリ秒) /performance/swapWrite 現在値 スワップ処理のファイルへの書き込み回数(累計) (単位:回数) /performance/swapWriteSize 現在値 スワップ処理のファイルへの書き込みサイズ(累計) (単位:バイト) /performance/swapWriteTime 現在値 スワップ処理のファイルへの書き込み時間(累計) (単位:ミリ秒) [実行例]
$ gs_stat -u admin/admin -s 192.168.0.1:10040 { : "performance": { "storeMemory": 4294967296, "storeMemoryLimit": 4294967296, "storeTotalUse": 9792126976, "swapRead": 2072705, "swapReadSize": 135836794880, "swapReadTime": 3920574, "swapWrite": 2172, "swapWriteSize": 142344192, "swapWriteTime": 601, :
3.3.2 トランザクション処理用メモリエリア
ロウの登録や検索処理などを行うトランザクションサービスが使用するメモリエリアです。各トランザクションサービスは、処理に必要なサイズ分のメモリをメモリエリアから確保して使用します。1回のトランザクション処理が終了すると、確保していたメモリをメモリエリアに戻します。
トランザクションサービスの数(並列度)の値は、/dataStore/concurrency(デフォルト4)になります。
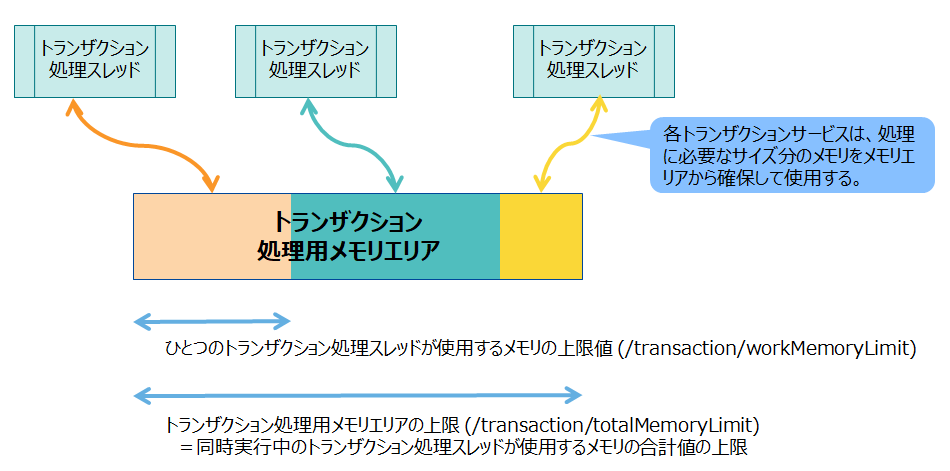
メモリエリア上のメモリが全て使用中で、トランザクションサービスに必要なメモリを確保できない時はエラーになります。
トランザクションサービスでは、TQLでの数千万ヒットのクエリを実行、巨大なサイズのBLOBの登録、MultiPutによる巨大なサイズのデータの一括登録などの処理でメモリを多く使う場合があります。 トランザクションの処理内容や、トランザクションサービスの数(並列度/dataStore/concurrency)に応じて、メモリエリアのサイズ上限値を設定する必要があります。
関連するパラメータ
■ノード定義ファイル(gs_node.json)
パラメータ 初期値 内容 起動後の変更 /transaction/totalMemoryLimit 1024MB トランザクション処理用メモリエリアのサイズ上限値 可(ノード再起動) /transaction/workMemoryLimit 128MB ひとつのトランザクション処理スレッドが使用するメモリのサイズ上限値 可(ノード再起動) [メモ]
- サイズ上限値は、オンラインでの変更はできません。変更するためにはノードを停止して定義ファイルを書き換える必要があります。
- 処理に必要なメモリが確保できない時にはエラーになります。現在の上限値の設定を確認し、メモリ増設と上限値の見直しを検討してください。
- 表の「起動後の変更」は、運用開始後にパラメータを変更できるかどうかを表します。
- 可(ノード再起動):パラメータを記載している定義ファイルを書き換えて、ノードを再起動すると変更できます。
関連する情報の確認方法
設定値の情報は、ノード稼働中に運用コマンドgs_paramconfを実行して確認することができます。
gs_paramconfのJSON形式の表示項目 設定値/現在値 内容 /transaction/totalMemoryLimit 設定値 トランザクション処理用メモリエリアのサイズ上限値 (単位:バイト) /transaction/workMemoryLimit 設定値 ひとつのトランザクション処理スレッドが使用するメモリのサイズ上限値 (単位:バイト)
3.3.3 SQL処理用メモリエリア
SQL処理用のメモリエリアには、主にSQL中間結果格納バッファとSQLワークメモリエリアがあります。
SQL中間結果格納バッファは、SQL処理におけるスキャンやジョインなどのタスクの中間結果のテーブルのデータを格納するためのメモリです。中間結果がバッファのメモリサイズ上限を超える場合は、一時的にSQL中間結果用スワップファイルに書き出します。SQLを利用した大量データに対する分析クエリを実行する場合は、データベースバッファとのバランスを考慮しながらできるだけ値を大きくすることを推奨します。
SQLワークメモリは、SQL処理におけるタスクの処理で使用するメモリです。タスクごとの使用量に関するワークメモリ上限の設定については、原則として変更する必要はありません。
ただし、中間結果格納バッファとワークメモリのサイズは、次の式を満たすように設定してください。
- 中間結果格納バッファの上限値(storeMemoryLimit) >= ワークメモリの上限値(workMemoryLimit) × タスク処理の同時実行数
満たさない場合は、中間結果用スワップファイルへの書き出しが頻発する場合があります。
関連するパラメータ
■ノード定義ファイル(gs_node.json)
パラメータ 初期値 内容 起動後の変更 /sql/storeMemoryLimit 1024MB SQL中間結果格納バッファのサイズ上限値(ノード単位) 可(ノード再起動) /sql/workMemoryLimit 32MB SQLワークメモリバッファのサイズ上限値(タスク単位) 可(ノード再起動) /sql/workCacheMemory 128MB workMemoryLimitのメモリのうち、使用後に解放せずにキャッシュするサイズ(ノード単位) 可(ノード再起動) /sql/storeSwapFilePath swap SQL中間結果を格納するファイルを配置するディレクトリ 可(ノード再起動) /sql/concurrency 4 SQL処理の並列度 可(ノード再起動) /sql/failOnTotalMemoryLimit false SQL処理用メモリの総上限を超えるメモリを必要とする場合に、SQLの実行を強制停止するかどうか 可(オンライン) /sql/totalMemoryLimit 0MB SQL処理用メモリの総上限(ノード単位) 可(オンライン) [メモ]
- サイズ上限値は、オンラインでの変更はできません。変更するためにはノードを停止して定義ファイルを書き換える必要があります。
- SQL処理用のメモリが不足している場合、スワップ処理(スワップファイルへの書き込みやスワップファイルからの読み込み処理)が行われます。
- スワップ処理が多く発生している場合は、SQL処理用メモリのサイズを大きくしてください。スワップ処理の発生状況は、「関連する情報の確認方法」のsqlStoreSwapXXXXの項目で確認できます。
- SQL処理用のメモリの総使用量は、次のメモリエリアの合計値となります。この値は、SQL処理用メモリの総上限を超えるかどうかの判断基準として使用されます。
- SQL中間結果格納バッファ(キャッシュを含む、ノード内の合計値)
- SQLワークメモリエリア(キャッシュを含む、ノード内の全タスク分の合計値)
- その他のSQL処理用メモリエリア(SQLイベント処理やタスクの管理情報など)
- SQL処理用のメモリの総上限の設定ついて、指定がないか、0が指定された場合、次の式により上限値を自動的に計算します。
- concurrency×workMemoryLimit×4.0+storeMemoryLimit
- 表の「起動後の変更」は、運用開始後にパラメータを変更できるかどうかを表します。
- 可(ノード再起動): パラメータを記載している定義ファイルを書き換えて、ノードを再起動すると変更できます。
- 可(オンライン): ノード稼動中にオンラインでパラメータを変更できます。永続化するためには定義ファイルの書き換えが必要です。
関連する情報の確認方法
設定値の情報は、ノード稼働中に運用コマンドgs_paramconfを実行して確認することができます。
gs_statのJSON形式の表示項目 設定値/現在値 内容 /sql/storeMemoryLimit 設定値 SQL中間結果格納バッファのサイズ上限値 /sql/workMemoryLimit 設定値 SQLワークメモリバッファのサイズ上限値 /sql/workCacheMemory 設定値 workMemoryLimitのメモリのうち、使用後に解放せずにキャッシュするサイズ /sql/storeSwapFilePath 設定値 SQL中間結果を格納するファイルを配置するディレクトリ 現在値の情報は、ノード稼働中に運用コマンドgs_statを実行して確認することができます。
gs_statのJSON形式の表示項目 設定値/現在値 内容 /performance/sqlStoreSwapRead 現在値 スワップ処理のファイルからの読み込み回数(累計) (単位:回数) /performance/sqlStoreSwapReadSize 現在値 スワップ処理のファイルからの読み込みサイズ(累計) (単位:バイト) /performance/sqlStoreSwapReadTime 現在値 スワップ処理のファイルからの読み込み時間(累計) (単位:ミリ秒) /performance/sqlStoreSwapWrite 現在値 スワップ処理のファイルへの書き込み回数(累計) (単位:回数) /performance/sqlStoreSwapWriteSize 現在値 スワップ処理のファイルへの書き込みサイズ(累計) (単位:バイト) /performance/sqlStoreSwapWriteTime 現在値 スワップ処理のファイルへの書き込み時間(累計) (単位:ミリ秒)
3.3.4 その他のメモリ
3.3.4.1 コンテナ、データファイル管理情報保持用メモリ
処理用のバッファ以外にも、コンテナやファイルの管理情報を保持するためにメモリを使用します。次の2つのメモリのサイズは、それぞれコンテナ数とデータ容量に比例して大きくなります。
コンテナ管理用メモリ
- ノード上のコンテナ数 × 64バイト程度のメモリを常時使用します。
- 例えば、コンテナ数が1000万の場合、約640MBのメモリを使用します。
データファイル管理用メモリ
- ノード上の全データ容量 ÷ ブロックサイズ × 32バイト程度のメモリを常時使用します。
- 例えば、全データ容量が1TBでブロックサイズ64KBの場合、約500MBのメモリを使用します。
3.4 コンテナ設計
コンテナの最適な設計はシステムやアプリケーションの要件によって大きく異なります。本節ではコンテナ設計の参考になる基本的なポイントを説明し、関連する情報を示します。
3.4.1 推奨する設計
日々生成されるデータは時系列コンテナに格納
コンテナの種別にはコレクションと時系列コンテナの2つがあります。
まずは、格納するデータに対して時系列コンテナが利用できるかを検討し、時系列コンテナが利用できない場合にのみコレクションの利用を検討します。
IoTシステムのように機器のセンサデータやログが時々刻々生成され、増加していく場合は、時系列コンテナを使いましょう。時系列コンテナは時系列データの格納と参照に対して最適化されているため、データベースバッファの利用効率がコレクションを利用したときと比べて高くなります。
また、時系列コンテナには、時系列データ特有の演算機能があります。この機能への理解を深めると、コンテナ設計に役立ちます。
[参考]
- 本書
- GridDB 機能リファレンス
- GridDB プログラミングガイド
- GridDB TQLリファレンス
コンテナは少数より多数
1つのコンテナに対する処理は、1台のノードの1つの処理スレッドで行われます。そのため、少数のコンテナにそれぞれ大量のデータを格納するようなコンテナ設計を行うと、ノードの処理並列度(マルチコア)が活かせません。また、特定のノードにアクセスが集中することにも繋がるため、ノードを増設した場合に性能がスケールアウトしません。
例えば、時系列データの場合は、次のようにデータソースごとに時系列コンテナを作成します。
- センサデータは個々のセンサごとに1つの時系列コンテナを作成する
- 生産データは個々の製品ごとに1つの時系列コンテナを作成する
また、同種のデータであっても、クラスタのノード数 * ノードあたりの処理並列度を目安とした複数のコンテナに分割することを推奨します。
複数のコンテナの操作を直列に実行してしまうと、性能の低下に繋がります。分割したコンテナは一括処理機能を使ってなるべく並列に処理しましょう。
[参考]
- 本書
- GridDB 機能リファレンス
- GridDB プログラミングガイド
データに合った方法でコンテナを分割する
コンテナを分割する方法は3つあります。
- ロウの分割
同種のデータを検索条件に合わせて分割する方法です。例えば、あるセンサデータを1つのコンテナに格納し続けるのではなく、1日分のデータのみを1つのコンテナに格納します。このように格納すると、ある日のすべてのデータやあるセンサの1週間分のデータといった検索で並列処理が容易になり、検索性能が向上します。 - カラムの分割
参照頻度の低いデータを別のコンテナに分けて分割する方法です。例えば、機器のログすべてを1つのコンテナに格納するのではなく、解析によく使用する情報のみ同じコンテナに格納し、それ以外の情報を別のコンテナに格納します。このように格納すると、余計なデータを参照する必要がなくなり、検索性能が向上します。 - テーブルパーティショニング特定のカラムをパーティショニングキーに指定することで、そのカラムの値によって自動的に複数の内部コンテナにデータを振り分ける方法です。分割の方法には種別があり、データに合わせて種別を選択します。
検索の条件やデータの特徴に合わせて、適切な分割方法を選択しましょう。
[参考]
- GridDB 機能リファレンス
最小限の索引が最大限の性能を引き出す
システムのデータ検索条件に合わせて適切に索引を作成することで、検索性能を向上させることができます。1つのコンテナには複数の索引を作成することができますが、必要最低限としなければなりません。
なぜなら、索引のデータがデータベースバッファを圧迫するためです。メモリサイズが潤沢ではないシステムにおいて、余分な索引をつけてしまうと、バッファヒット率が下がってスワップ処理が多くなり、性能低下に繋がります。
必要のない索引を後から削除することもできますが、対象のコンテナに大量のロウが既に格納されている場合、削除完了までに長い時間を要することがあります。そのため、あらかじめ十分に設計し、必要な索引のみを作成するようにしましょう。
主キーによる検索のみでデータの絞り込みを行えるようにコンテナを設計すると、自然と最小限の索引になります。また、そのような設計を行った場合、自ずとコンテナを分割することになるため、各ノードの処理並列度を活かせるようになります。
また、効果的な索引を作成するには、SQLの最適化ルールを参考にしてください。
[参考]
- 本書
- GridDB 機能リファレンス
- GridDB プログラミングガイド
- GridDB SQLチューニングガイド
3.5 クラスタ構成設計
クラスタ構成設計では、システムの稼働率やRTOなどの可用性の要件に合わせて、以下の項目を設計する必要があります。
- クラスタ構成ノード数
- 障害検知(ハートビート)
- レプリカ処理(レプリカ数、処理モード)
- クライアントフェイルオーバタイムアウト
GridDBは、複数のノード(サーバプロセス)で構成されたクラスタ上に、レプリカ(データ)を自律的に配置し、クラスタ全体の管理を行うマスタノードを自動的に決定します。ノードに障害が発生しても、フェイルオーバによってクライアントアプリケーション(NoSQLインタフェース)からの処理を継続することができます。
また、ラックやアベイラビリティゾーンなどの物理的な機器のグループがある環境上にクラスタを構築する場合には、ラックゾーンアウェアネス機能の利用を検討し、利用する場合は以下の項目を設計する必要があります。設計の方法については、ラックゾーンアウェアネスを参照してください。
- ラックやアベイラビリティゾーンなどのグループ数
- ラックやアベイラビリティゾーンなど各機器のグループに配置するノード数
ラックゾーンアウェアネス機能は、機器のグループ全体に障害が発生した場合にもDBデータへのアクセスができるよう、オーナとバックアップを別グループに配置するように制御する機能です。
3.5.1 クラスタ構成ノード数
クラスタを構成するノードの台数によって、何台まで同時にノード障害が発生してもクラスタのサービスが継続できるかが異なります。
システムの稼動率を満たすために、同時にダウンするノードは何台まで許容できるかでクラスタを構成するノード数を決めます。
クラスタは、構成ノード数の半数以上の台数がダウンするとサービスが停止します。
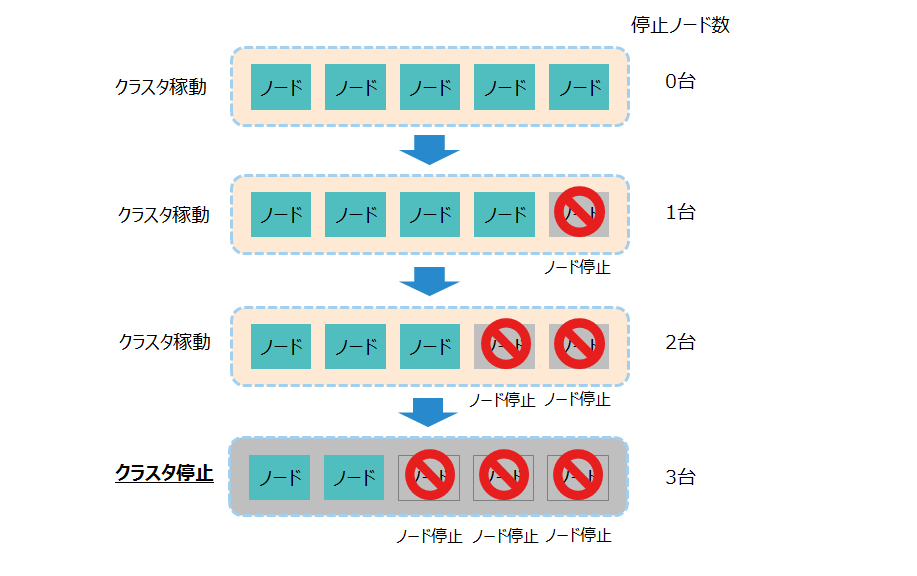
クラスタの稼動台数 可用性が必要なシステムであれば、クラスタを構成するノードの台数は3台以上を推奨します。2台以下の場合は、ノードが1台停止するとクラスタの稼動も停止します。
構成ノード数と、クラスタが稼働可能な停止ノード数の関係は以下の通りです。
構成ノード数 クラスタ稼働が可能な停止ノード数 1台 0台 (低可用性) 2台 0台 (低可用性) 3台 1台 4台 1台 5台 2台
可用性が要求されないシステムであれば、ノード1台のシングル構成で稼動することも可能です。
[メモ]
- ハードウェアメンテナンスなどの計画停止の場合は、1台ずつノードを停止してください。複数のノードを停止すると、他のノードで障害が発生した場合に、停止している台数が過半数を超えてクラスタが停止してしまう可能性があります。
また、ノードがダウンした場合には、自動的に以下の復旧処理を行います。
マスタがダウンした場合
- マスタの再決定
- パーティション(レプリカ)再配置
フォロワがダウンした場合
- パーティション(レプリカ)再配置
パーティション(レプリカ)再配置は、ノードダウンによるクラスタ縮退だけでなく、クラスタ拡張時にも発生します。
再配置を行う際にバックアップのデータがオーナよりも古い場合、クラスタは差分のデータをバックアップノードへ転送してオーナとバックアップの同期をとります。
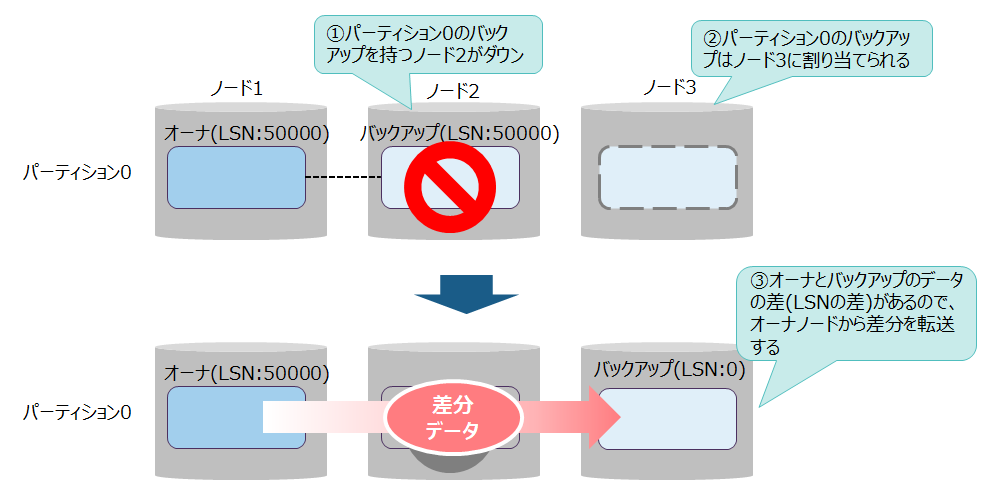
- オーナとバックアップのデータの差は、各データが持つLSN(Log Sequence Number)の値で判断します。LSNの値はデータを更新するごとに加算するので、値が大きい方が新しいデータであることを意味します。
- 同期処理には、オーナとバックアップのデータの差の大きさによって2種類の処理があります。
- 短期同期
- データの差が小さい場合に行う同期処理です。データの転送量が少ないので短い処理時間で終わります。
- 長期同期
- データの差が大きい場合に行う同期処理です。データの転送量が多く、時間がかかる場合があります。
- 短期同期
上記の同期処理は、サーバが自動で行うため、設計が必要な項目はありません。
3.5.2 障害検知(ハートビート)
クラスタは、ノード間のハートビートによって、障害を検知します。ノードの生存を確認するために、マスタは一定周期で全フォロワにハートビートを送信します。 ハートビートを受信したフォロワは、応答をマスタに返します。

また、フォロワはマスタからのハートビートが届いていることを確認するために、ハートビートの受信時間を一定周期で確認します。
ハートビートでは、マスタとフォロワ間で最新のデータを反映するために、構成ノード情報やパーティション情報管理テーブルの情報も一緒にやり取りします。
フォロワの応答がマスタに届かなかった場合
- 2回連続でフォロワからのハートビート応答がマスタに届かなかった場合、マスタはフォロワがダウンしたと判断します。
- マスタは持っている構成ノード情報を更新し、次のハートビートで各フォロワに送信します。
- クラスタは障害検知時の処理を行います。
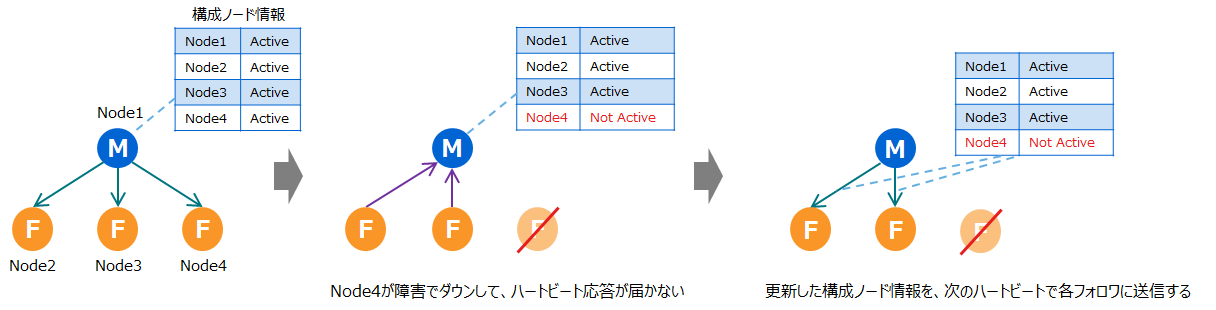
フォロワのハートビート応答が届かなかった場合 マスタのハートビートがフォロワに届かなかった場合
- 2回連続でマスタからのハートビートがフォロワに届かなかった場合、フォロワはマスタがダウンしたと判断します。
- 新たにマスタを決めるため、全フォロワが一度サブマスタに変わった後、ノードの中から1台がマスタ、それ以外がフォロワになります。
- クラスタは障害検知時の処理を行います。
一定周期の時間は、マスタとフォロワともにデフォルト5秒(gs_cluster.jsonの/cluster/heartbeatIntervalの値)です。
関連するパラメータ
●クラスタ定義ファイル(gs_cluster.json)
パラメータ 初期値 内容 /cluster/heartbeatInterval 5秒 ・マスタがハートビートの送信を行う周期
・フォロワがマスタからのハートビート受信時間の確認を行う周期■ノード定義ファイル(gs_node.json)
パラメータ 初期値 内容 /cluster/serviceAddress 127.0.0.1 ハートビート送受信に使用するアドレス /cluster/servicePort 10010 ハートビート送受信に使用するポート番号
3.5.3 レプリカ処理(レプリカ数、処理モード)
GridDBでは、データの可用性のために、レプリカを作成して複数ノードで分散して保持します。これにより、ノード障害が発生した場合でも残りのノード上のレプリカを使ってデータへのアクセスを継続することができます。
以下に、レプリカ、レプリカを作成するレプリケーション、および障害からレプリカを復旧する同期処理の仕組みの設計ポイントについて説明します。
3.5.3.1 レプリカ
レプリカは以下のような特徴を持ちます。
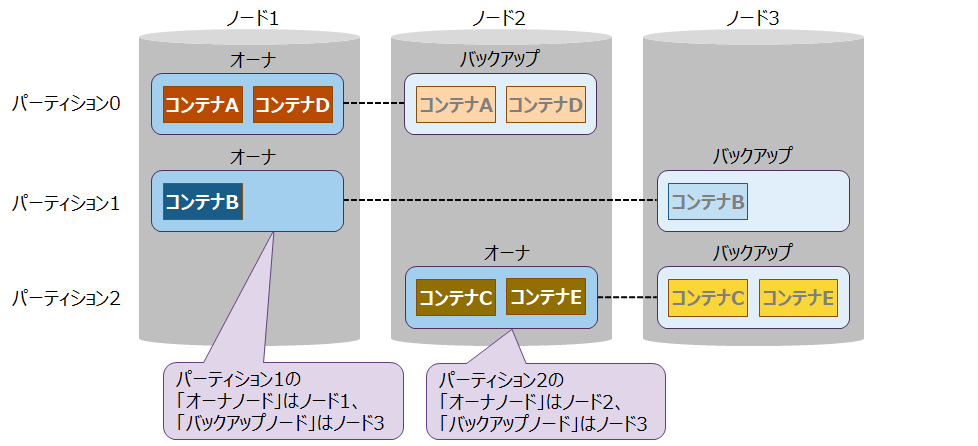
レプリカのデータ単位はパーティションです。
レプリカのうち、マスタのデータを「オーナ」、オーナから複製したデータを「バックアップ」と呼びます。また、それぞれのデータを持つノードを「オーナノード」・「バックアップノード」と呼びます。
アプリケーションからの登録や参照は、オーナに対して行います。バックアップは、オーナに障害が発生した時のリカバリ用のデータのため、アプリケーションがバックアップに対してアクセスすることはありません。
レプリカ パーティションのオーナとバックアップは、異なるノード上に分散して配置します。どのノードに配置するかはクラスタが自動的に決定します。
レプリカ数はシステムの稼動率として、何台のノードの多重障害までデータアクセスを保証するべきかによって決めます。
多重障害とは、複数のノードで障害が発生して一度にダウンすることです。
- 多重障害のノード数がレプリカ数よりも少ない場合には、データアクセスは継続できます。
- 一時的にクラスタ上のレプリカの数が少なくなり、クラスタは「レプリカロス」という可用性が低い状態になりますが、同期処理によってレプリカが新たに自動作成されて正常な状態に戻ります。

- 多重障害のノード数がレプリカ数以上の場合には、多重障害でダウンしたノードにすべてのレプリカが配置されているパーティションのデータにアクセスできなくなります。
- オーナとバックアップがすべて無くなったパーティションは「オーナロス」という状態になります。レプリカを持っているノードを復旧してクラスタに参加させるまで、該当のパーティションにはアクセスできません。
- ただし、複数のノードがダウンしている多重障害であっても、ダウンが同時にではなく時間間隔が空いている場合は、その間に同期処理が行われて別のノードにレプリカが作成されて、クライアントのデータアクセスが継続できることもあります。

レプリカ数を増やすと可用性は上がりますが、以下のような影響があります。
データ容量への影響
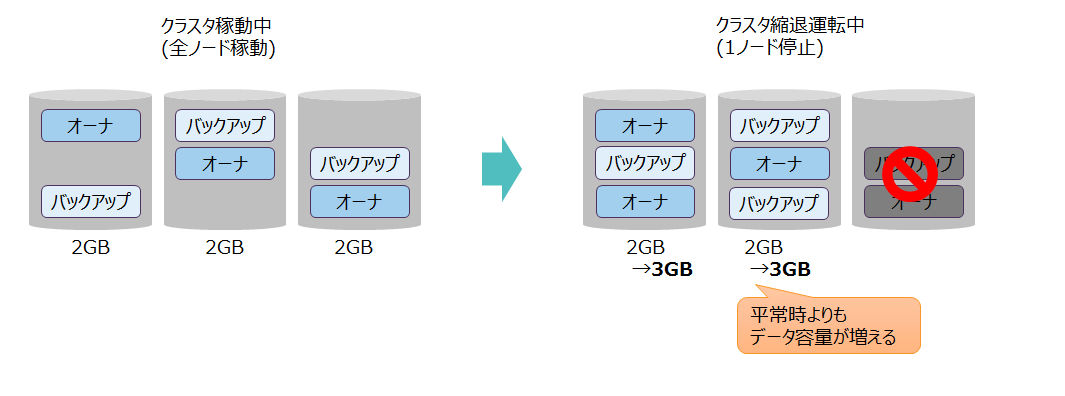
- レプリカ数を増やすとデータ容量が増えるので、処理するために必要なメモリとディスクの容量が増加します。
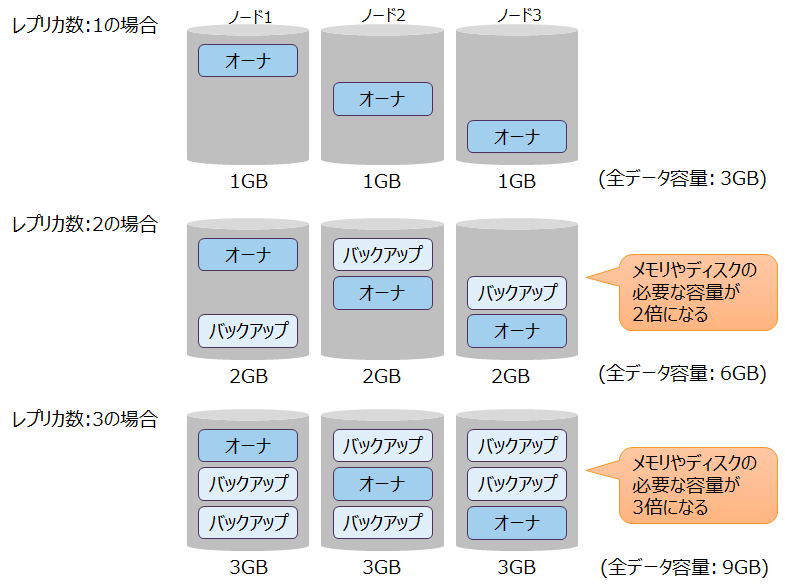
レプリカ数とデータ容量の関係 - クラスタが縮退運転している場合は、停止しているノードのデータを他のノード上に配置して運用するので、縮退運転中はひとつのノードで扱うデータ容量が増えます。
レプリカ数とデータ容量の関係
レプリカ数の目安は以下になります。
- 複数ノードのクラスタ構成の場合は、レプリカ数は2が推奨値です。(定義ファイルのデフォルト値です)
- シングル構成の場合は、レプリカ数は1が推奨値です。レプリカ数2以上を指定しても、同一ノード上にレプリカを作成するため可用性の効果はありません。
- メモリやディスクのリソースが十分にあり、かつ、高い可用性を求められるシステムの場合は、レプリカ数を3以上にすることを検討してください。
- その場合、構成ノード数の過半数以下の値を設定してください。
- レプリカ数 <= (構成ノード数 + 1) / 2
- 上記の式を満たさない場合、レプリカ数より少ない台数の障害時に、レプリカのデータが存在していても、サービスの稼動条件(過半数のノードが稼動)を満たせずにサービスが停止してしまいます。
- その場合、構成ノード数の過半数以下の値を設定してください。
関連するパラメータ
●クラスタ定義ファイル(gs_cluster.json)
パラメータ 初期値 内容 起動後の変更 /cluster/replicationNum 2 レプリカの数 可(クラスタ再起動)
[メモ]
- 表の「起動後の変更」は、運用開始後にパラメータを変更できるかどうかを表します。
- 可(クラスタ再起動):パラメータを記載している定義ファイルを書き換えて、全ノードとクラスタを再起動すると変更できます。
3.5.3.2 レプリケーション処理
データの登録や削除などのトランザクション処理で更新したデータは、ディスクに書き込んで永続化することでノード障害発生時などのデータ欠損から保護します。 また、更新したデータをバックアップのノードにレプリケーションで転送して複製することで可用性を高めます。
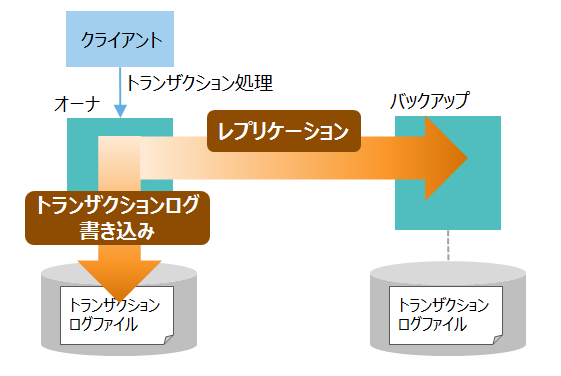
トランザクション処理におけるログファイルへの書き込みやレプリケーションには同期や非同期のモードがあり、システムの可用性や性能要件に応じて選択します。
レプリケーション方式
方式 内容 非同期
(デフォルト)トランザクション処理ごとにバックアップノードに更新データを転送した後、受信完了を待ち合わせません。 準同期 トランザクション処理ごとにバックアップノードに更新データを転送した後、受信完了を待ち合わせます。(バックアップノード側の更新データの反映処理は非同期です) トランザクションログの書き込みモード
方式 内容 非同期
(デフォルト)トランザクション処理のタイミングとは関係なく、一定の周期でトランザクションログファイルへのフラッシュを行います。 同期 トランザクション処理ごとに、トランザクションログファイルへのフラッシュを行います。 - 非同期モードは、IoTシステムのように高頻度にデータを登録するシステムのためのモードです。非同期に書き込むことで速度は向上します。一方でデータ欠損の可能性が高まりますが、GridDBではレプリケーションのためのデータ転送を同時に行うことで、非同期の場合も可用性を高めています。例えば、アプリケーションにトランザクション処理の完了を通知した後、ログ書き込み周期より前にオーナのマシンがダウンしてしまった場合、オーナ側では更新したデータは失われてしまいますが、バックアップ側に更新データは転送されているためデータ欠損の可能性を低くすることができます。
以下に、トランザクションログとレプリケーションのモードの組合せと、それぞれの処理の流れや性能などを説明します。
| モードの 組合せ |
処理の流れ | 性能 | アプリケーションにトランザクション処理の完了を通知した時点のデータの状態 |
|---|---|---|---|
| [1] ログ: 非同期(1秒) レプリケーション: 非同期 (デフォルト値) |
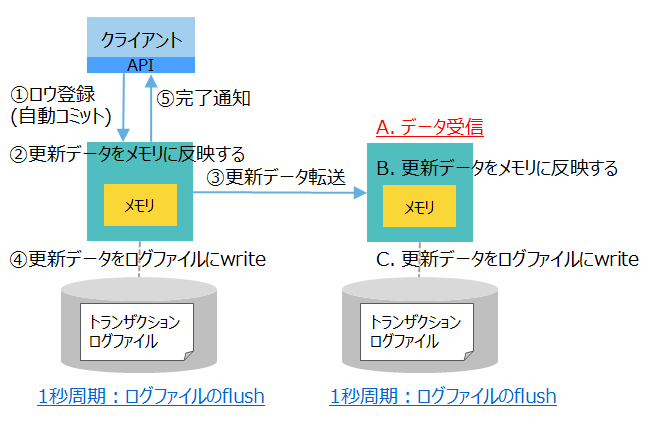 |
高速 | ・1秒以内に更新データをフラッシュする ・バックアップノードにデータ転送(受信は未確認) |
| [2] ログ: 非同期(1秒) レプリケーション: 準同期 |
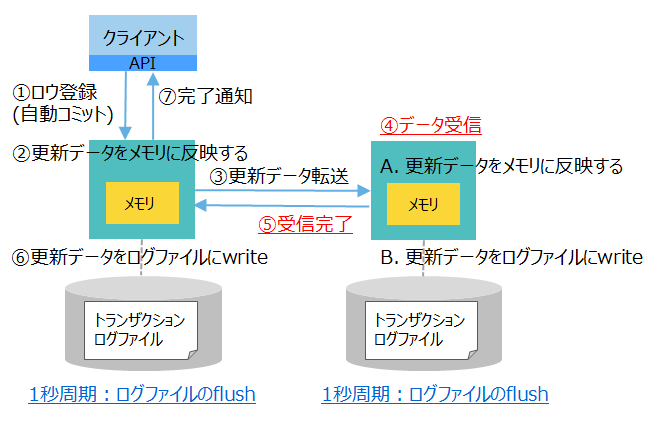 |
やや高速 | ・1秒以内に更新データをフラッシュする ・バックアップノードにデータ転送完了 |
| [3] ログ: 同期 レプリケーション: 非同期 |
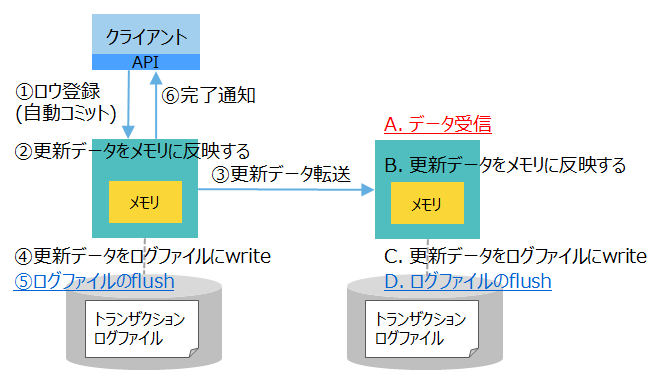 |
やや低速 | ・更新データをフラッシュ完了 ・バックアップノードにデータ転送(受信は未確認) |
| [4] ログ: 同期 レプリケーション: 準同期 |
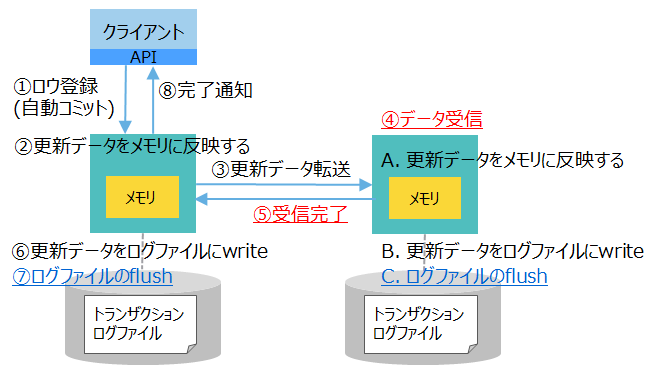 |
低速 | ・更新データをフラッシュ完了 ・バックアップノードにデータ転送完了 |
- 高性能の順: [1] > [2] > [3] > [4] (数字は、上表の「モードの組合せ」の番号)
- 高可用の順: [4] > [3] > [2] > [1] (数字は、上表の「モードの組合せ」の番号)
トランザクションログの書き込みモード・レプリケーションモード設定の目安は以下になります。
- 通常のシステムにおいては、トランザクションログは非同期(1秒)・レプリケーションは非同期の組合せを推奨します。(この組合せが定義ファイルのデフォルト値です)。
- 両方とも非同期のため高速で、かつ、上記の通りレプリケーションのデータ転送の仕組みで最低限の可用性を見込んだ設定です。
- 性能と可用性はトレードオフの関係です。非常に高い可用性や信頼性を求められるシステムにおいては、性能要件とのバランスで準同期や同期のモードの組合せを検討してください。
関連するパラメータ
●クラスタ定義ファイル(gs_cluster.json)
パラメータ 初期値 内容 起動後の変更 /transaction/replicationMode 0(非同期) レプリケーションのモードです。
非同期:0またはASYNC
準同期:1またはSEMISYNC可(クラスタ再起動) /transaction/replicationTimeoutInterval 10s レプリケーションが準同期モードの場合に、バックアップノードの受信完了を待ち合せるタイムアウト時間です。 可(クラスタ再起動) ■ノード定義ファイル(gs_node.json)
パラメータ 初期値 内容 起動後の変更 /dataStore/logWriteMode 1 トランザクションログの書き込みモードです。
非同期:1以上231未満の整数で周期の時間(秒)を指定
同期:0または-1可(ノード再起動)
[メモ]
- 表の「起動後の変更」は、運用開始後にパラメータを変更できるかどうかを表します。
- 可(クラスタ再起動):パラメータを記載している定義ファイルを書き換えて、全ノードとクラスタを再起動すると変更できます。
- 可(ノード再起動):パラメータを記載している定義ファイルを書き換えて、ノードを再起動すると変更できます。
3.5.4 クライアントフェイルオーバタイムアウト
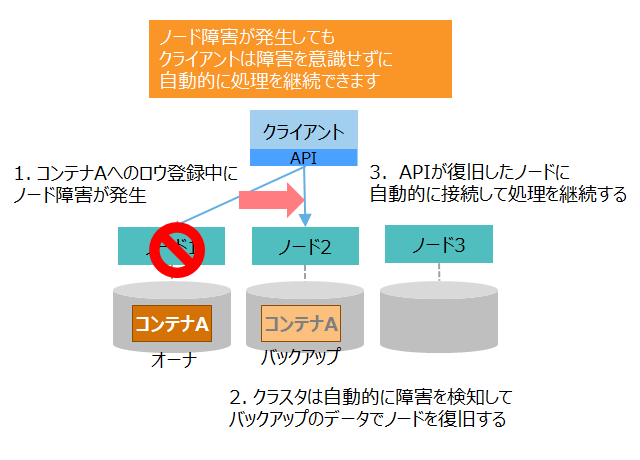
ノード障害が発生しても、ノードやクライアントAPI(NoSQLインタフェース)のフェイルオーバ機能により、アプリケーションは継続してデータにアクセスすることができます。
ノード障害が発生した時のフェイルオーバの仕組みを、障害発生から復旧までの流れに沿って詳細に説明します。
| 流れ | 図 | 説明 |
|---|---|---|
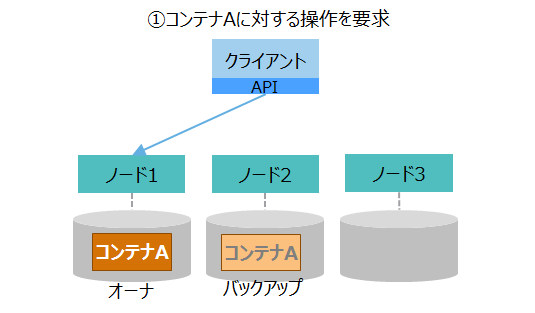
| (1)クライアントの処理要求 |
|
①クライアントは、クライアントAPIを用いて、コンテナに対する操作を要求します。 クライアントAPIは、操作対象のコンテナAを格納しているノード1に接続して操作を行います。 |
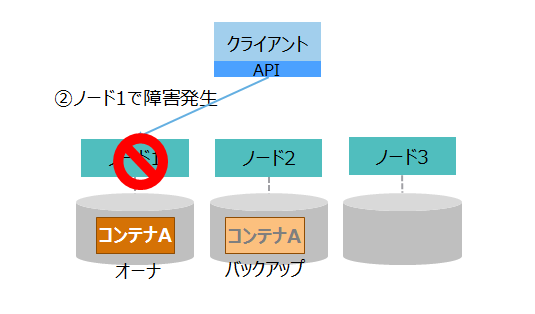
| (2)障害発生 |
|
②クライアントからの要求処理中に、ノード1で障害が発生してダウンします。 |
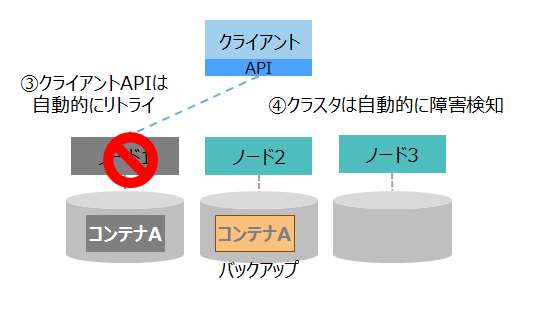
| (3)自動復旧1 |
|
③クライアントAPIは、ノード1との接続が切れたため、自動的に処理をリトライします。 ④クラスタは、ノード1がダウンしたことを自動的に検知して、残りのノードでクラスタを再構成します。 |
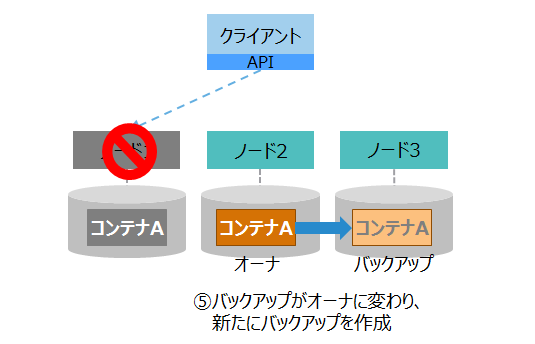
| (4)自動復旧2 |
|
⑤クラスタは、ノード1上のオーナの代わりとして、ノード2のバックアップをオーナに変更します。 バックグラウンドで別のノードにバックアップを作成します。 |
| (5)処理継続 |
|
⑥クライアントAPIは、新たにコンテナAのオーナとなったノード2に接続して、自動的に処理をリトライします。 クライアントは処理を継続でき、エラーは発生しません。 |
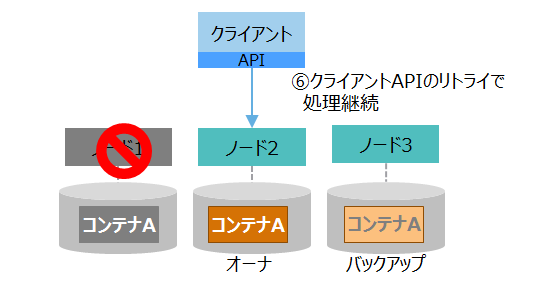
クライアントAPIがアクセスしているパーティションのノードに障害が発生した場合、クライアントAPIは処理を自動的にリトライします。 リトライしている間に、クラスタの自律的データ配置によってパーティションが復旧した場合、クライアントAPIは自動的に処理を継続します。リトライする時間「フェイルオーバタイムアウト」は、アプリケーションの接続処理のプロパティで変更することができます。
- 処理が継続できずにエラーになるケース
- 自律的データ配置の同期処理に時間がかかり、フェイルオーバタイムアウト時間までにパーティションが復旧しなかった場合
- ノード障害によりデータが欠損して、パーティションがオーナロスの状態になった場合
[メモ]
- クライアントフェイルオーバの機能を持つのは、NoSQLインタフェースのみです。
関連するパラメータ
クライアントAPIからクラスタに接続する際のプロパティ
パラメータ 初期値 内容 failoverTimeout 120秒 クライアントのフェイルオーバタイムアウト時間
アプリケーションのプログラムで指定します。
3.5.5 ラックゾーンアウェアネス
GridDBは、ラックやアベイラビリティゾーンなどの物理的な構成グループ単位の障害が発生した場合の可用性を向上させる、ラックゾーンアウェアネス機能を提供します。ラックやアベイラビリティゾーンといった機器のグループ全体に障害が発生した場合にもDBデータへのアクセスができるよう、オーナとバックアップを別グループに配置するように制御する機能です。
あるデータのオーナとバックアップがともに同じ構成グループに配置されていると、そのグループに障害が発生した場合にはそのデータへのアクセスができなくなります。ラックゾーンアウェアネス機能を利用すると、クラスタのノードが属するグループを事前に定義しておくことができ、GridDBは、その定義を参照し、オーナとバックアップを別グループに配置するように制御します。これにより、あるグループに障害が発生した場合でも、別のグループにデータのバックアップがあるため、データへのアクセスが可能になります。この際、オーナとバックアップが各グループ、各ノードにできるだけ均等に配置されるように割り当てるため、耐ノード障害だけでなく、耐アベイラビリティゾーン障害などにも対応できるようになります。
ラックゾーンアウェネス機能を利用する場合に考慮すべき項目は以下になります。
- クラスタ構成ノード数:クラスタ構成ノード数が3未満の場合、可用性を担保できないためクラスタ構成ノード数は3以上としてください。(GridDBクラスタの構成ノード数はクラスタ構成ノード数に従います)
- 構成グループ数:1つの構成グループに対して少なくとも1ノードは必ず割り当てるようにしてください。最小クラスタ構成ノード数は3であるので、構成グループ数は必ず3以上を設定してください。
- 構成グループへのノード割り当て:ノードがどの構成グループに属するかは設定ファイルで設定します。この際、各グループに属するノード数は、できるだけ均等になるようにしてください。各グループのノード数が同じになるケースが最も可用性が高くなります。そのため、クラスタのノード数が構成グループの倍数となるような構成を推奨します。
- 注意点:構成グループ数が3の場合、4ノードでクラスタを構成することは避けてください。この構成の場合、いずれかの構成グループには2ノードが割当たります。もし、この2ノードが割当たった構成グループに障害が発生すると、生存ノード数が2となります。そうすると、残ったノード数がクラスタ継続するための基準値(クラスタのノード数の過半数以上。この例では3以上となります。)を下回ってしまい、クラスタが停止してしまいます。クラスタ構成ノード数が5以上の場合はこのような問題は発生しません。
ラックゾーンアウェアネス機能を用いた障害発生から復帰までの流れを詳細に説明します。アベイラビリティゾーン(AZ)の利用有無による違いを想定して例示しています。
(1)クラスタ安定状態 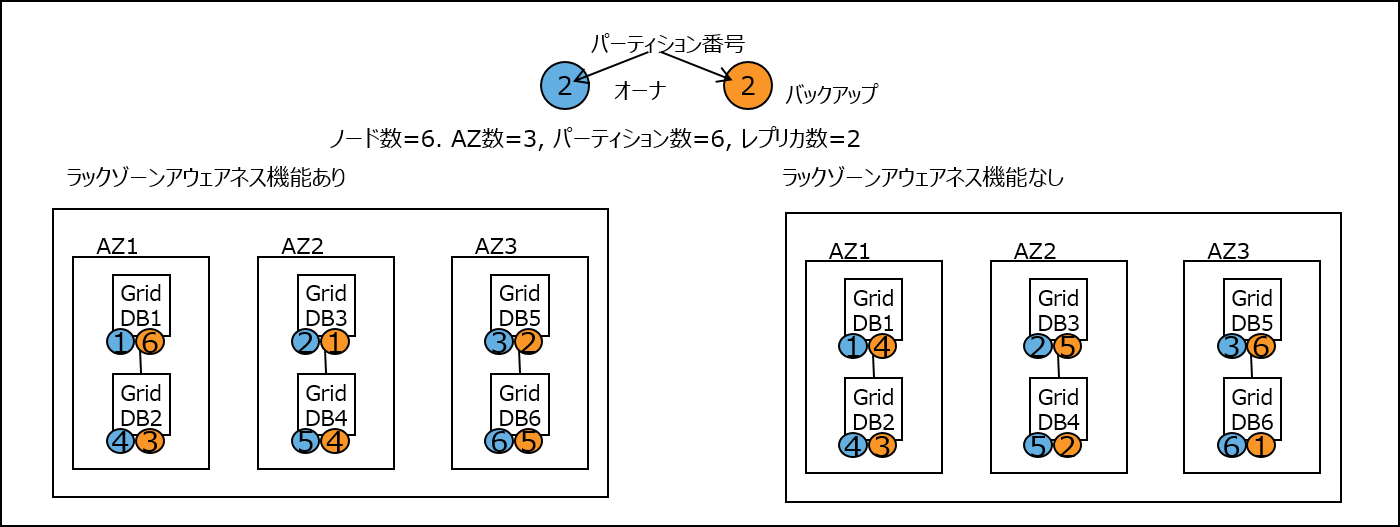
稼働中クラスタが、ノード数=6, AZ数=3(AZ1,AZ2,AZ3), パーティション数=6, レプリカ数=2で安定状態とします。この場合、ラックゾーンアウェアネス機能なしの場合、AZに対する制約がないため、同一AZ内にオーナとバックアップが配置される場合があります。
(2)AZ障害発生 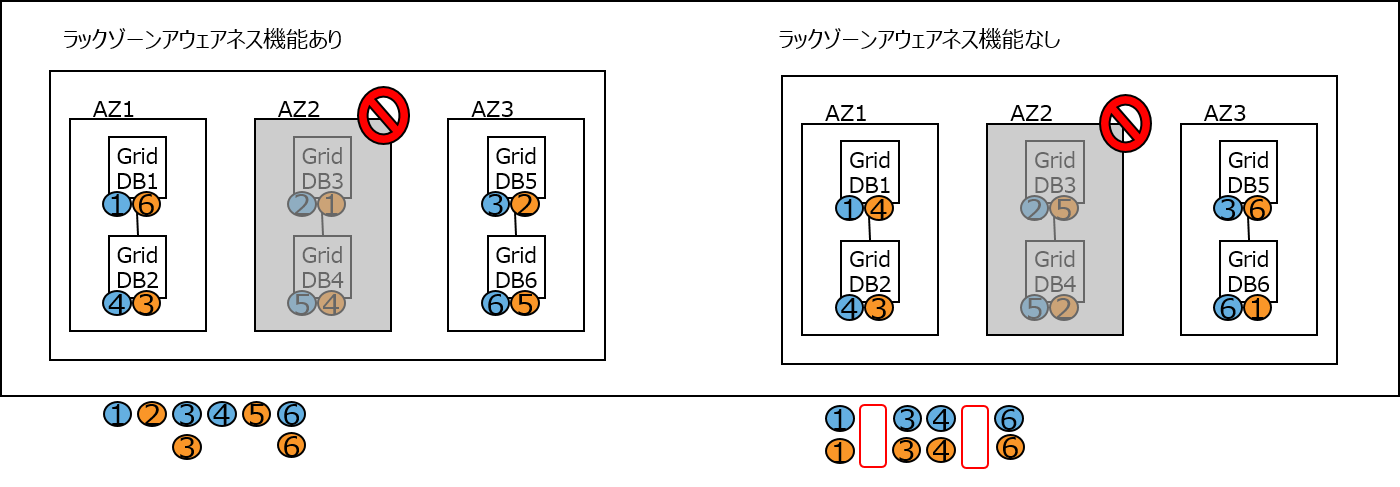
AZ2で障害発生すると、ラックゾーンアウェアネス機能ありの場合は生存するAZ1,AZ3で全パーティションのオーナ、もしくはバックアップのいずれかが存在するため、アプリケーションは全データへのアクセスが継続できます。しかし、ラックゾーンアウェアネス機能なしの場合はパーティション2,5が欠損し、アプリケーションが継続できず停止した状態になります。
(3)縮退運転時 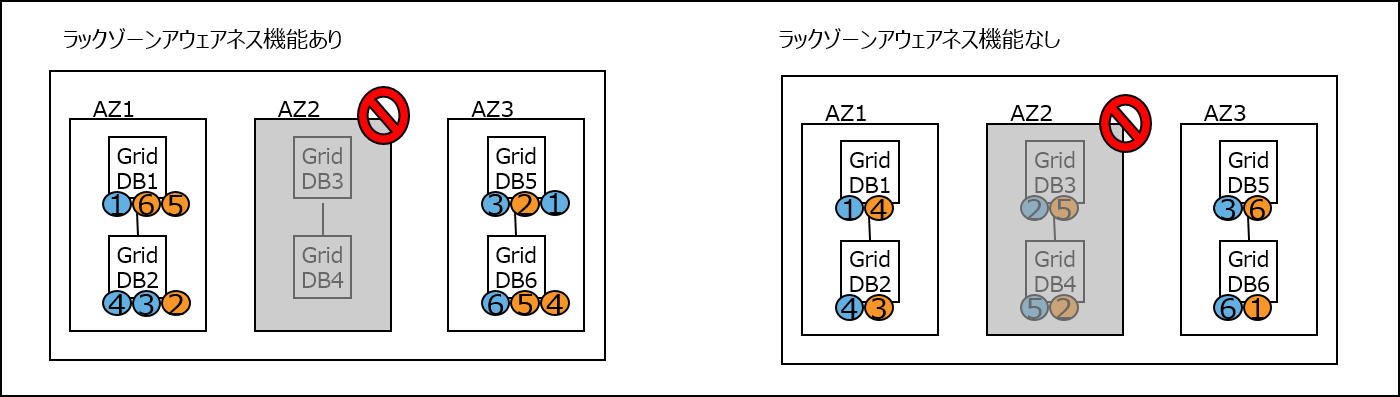
ラックゾーンアウェアネス機能ありの場合、AZ1, AZ3間で欠損したレプリカの復旧、パーティションの再配置処理が自動的に実行されます。ラックゾーンアウェアネスなしの場合は、AZ障害が復旧するまで、アプリケーションが再開できません。
(4)障害AZ復帰時 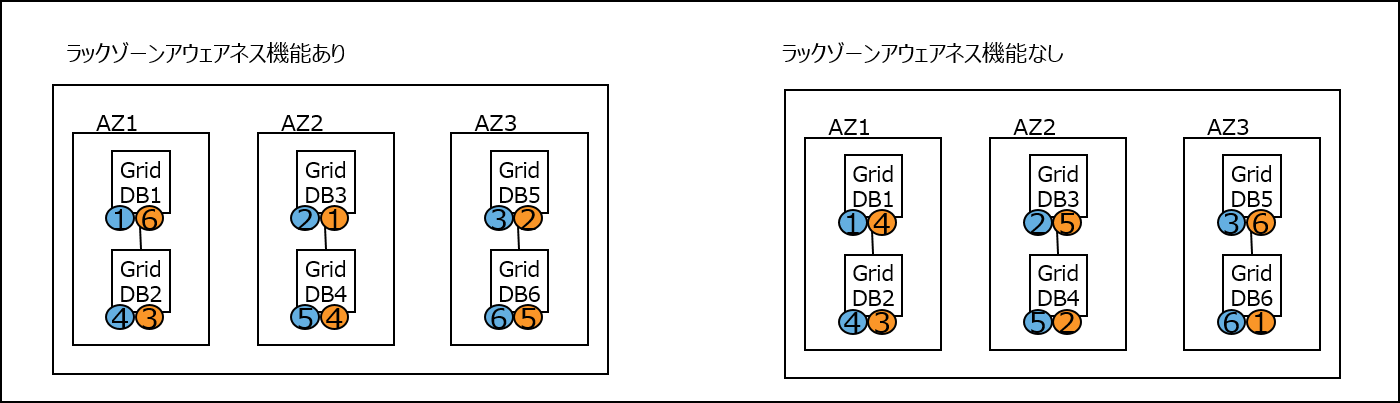
AZ2が正常復帰しクラスタが再構築された場合、ラックゾーンアウェアネス機能あり、なしの場合ともに、AZ1, AZ2, AZ3を対象として、この時点で欠損してレプリカの復旧、パーティションの再配置処理が自動的に実行されます。ラックゾーンアウェネス機能なしの場合は、この時点で停止していたアプリケーションが再開されることになります。
これら(1)~(4)に際して、運用上の特別な手順は必要ありません。
関連するパラメータ
- ノード定義ファイル(gs_node.json)
ラックゾーン関連のパラメータはデフォルトでは記載されていませんので、使用時は以下を設定する必要があります。
| パラメータ | 初期値 | 内容 | 起動後の変更 |
|---|---|---|---|
| /cluster/rackZoneAwareness | false | ラックゾーンアウェアネス機能を有効にする場合はtrueとして起動し、必ず以下のrackZoneIdを設定してください。 | 変更可(再起動) |
| /cluster/rackZoneId | なし | ラックゾーンを識別するIDを1文字以上64文字以内の英数字で入力してください。 | 変更可(再起動) |
{
:
:
"cluster":{
"servicePort":10010
"rackZoneAwareness":true,
"rackZoneId":"zone-01",
},
:
:
}
3.6 ネットワーク設計
GridDBでは、ノードとクラスタ2種類のネットワークを設計する必要があります。
3.6.1 ノードのネットワーク構成
GridDBノードは、クライアントや他のノードと様々なネットワーク通信を行います。その通信経路には、以下のような種類があります。
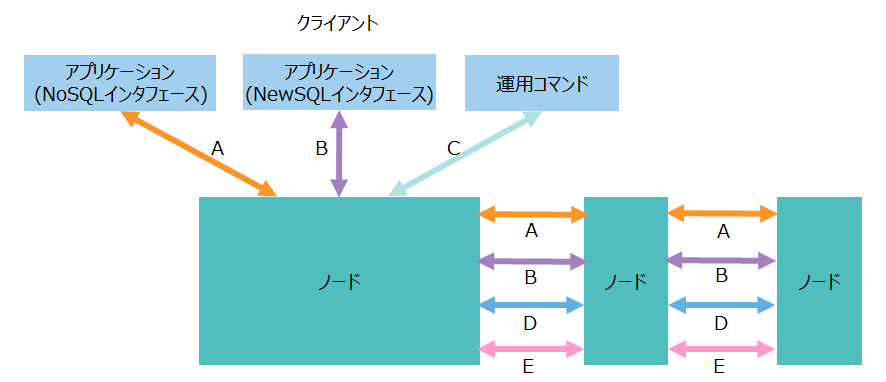
| No. | 項目 | 通信経路 | 説明 |
|---|---|---|---|
| A | トランザクション処理 | ・クライアント-ノード ・ノード間 |
・NoSQLインタフェースを通じたデータ操作のための通信 ・トランザクションのレプリケーション処理のための通信 |
| B | SQL処理 | ・クライアント-ノード ・ノード間 |
・NewSQLインタフェースを通じたデータ操作のための通信 ・SQLの並列分散処理のための通信 |
| C | 運用管理操作 | クライアント-ノード | 運用管理の操作要求を受け付けるための通信 |
| D | クラスタ管理 | ノード間 | ノードの生存を確認するためのハートビートやクラスタ管理情報を授受するための通信 |
| E | 同期処理 | ノード間 | パーティションの再配置によるデータ同期処理のための通信 |
GridDBの主な運用ツールはこれらの通信を使用します。
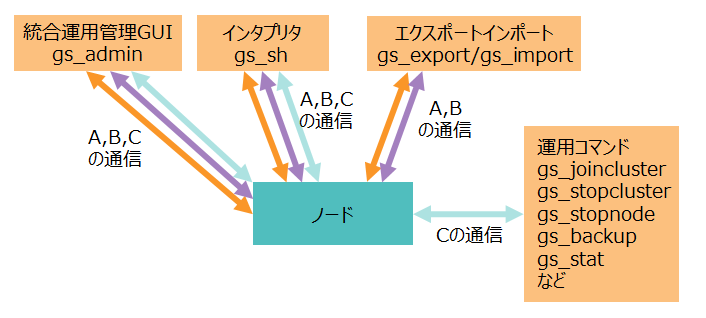
| 運用ツール | 使用する通信 |
|---|---|
| 統合運用管理GUI(gs_admin) | A. トランザクション処理 B. SQL処理 C. 運用管理操作 |
| インタプリタ(gs_sh) | A. トランザクション処理 B. SQL処理 C. 運用管理操作 |
| 運用コマンド(gs_joincluster,gs_statなど) | C. 運用管理操作 |
| エクスポート/インポートツール(gs_export,gs_import) | A. トランザクション処理 B. SQL処理 |
[メモ]
- 通信で使用するIPアドレスは、クライアントや他の全ノードと通信できるアドレスを指定してください。
- IPアドレスにホスト名を指定する場合は、クライアントや他の全ノードにおいて名前解決できる必要があります。
- ノード定義ファイルにIPアドレスの指定(serviceAddress)を省略した場合は、マシンのホスト名に対応付けられているIPアドレスをデフォルト値として使用します。
- ホスト名に対応付けられているIPアドレスを確認する方法
$ hostname -i 172.0.10.1
- ホスト名に対応付けられているIPアドレスを確認する方法
関連するパラメータ
ノード定義ファイル(gs_node.json)
- 各通信ごとに、IPアドレス(serviceAddress)とポート番号(servicePort)を設定します。
パラメータ 初期値 内容 起動後の変更 /cluster/serviceAddress -
(ホスト名と対応付けられたIPアドレス)クラスタ管理用のアドレス 可(ノード再起動) /cluster/servicePort 10010 クラスタ管理用のポート番号 可(ノード再起動) /cluster/notificationInterfaceAddress "" マルチキャストパケットを送信するネットワークインタフェースのアドレス 可(ノード再起動) /sync/serviceAddress -
(ホスト名と対応付けられたIPアドレス)同期処理用のアドレス 可(ノード再起動) /sync/servicePort 10020 同期処理用のポート番号 可(ノード再起動) /system/serviceAddress -
(ホスト名と対応付けられたIPアドレス)運用管理操作用のアドレス 可(ノード再起動) /system/servicePort 10040 運用管理操作用のポート番号 可(ノード再起動) /transaction/serviceAddress -
(ホスト名と対応付けられたIPアドレス)トランザクション処理用のアドレス 可(ノード再起動) /transaction/servicePort 10001 トランザクション処理用のポート番号 可(ノード再起動) /sql/serviceAddress -
(ホスト名と対応付けられたIPアドレス)SQL処理用のアドレス 可(ノード再起動) /sql/servicePort 20001 SQL処理用のポート番号 可(ノード再起動)
[メモ]
表の「起動後の変更」は、運用開始後にパラメータを変更できるかどうかを表します。
- 可(ノード再起動):パラメータを記載している定義ファイルを書き換えて、ノードを再起動すると変更できます。
物理/仮想ネットワークインタフェースが複数ある場合に、マルチキャスト方式を利用した接続を行うには、/cluster/notificationInterfaceAddressを設定することを推奨します。
また、TQLやSQLによるデータ操作では、NoSQL/NewSQLインタフェースを通じてクラスタに接続して処理を行いますが、SQLによるデータ操作はノード間での分散処理を行うため、ノード間の通信量が多くなります。
- TQL(NoSQLインタフェース)の場合は、データ操作をコンテナ単位で処理するので、クライアントはそのコンテナを持っているノードに対して通信を行います。
- SQL(NewSQLインタフェース)の場合は、データ操作を並列分散で処理するため、クライアントはランダムに1台のノードにアクセスし、SQLの処理を各ノードに分散させて行います。
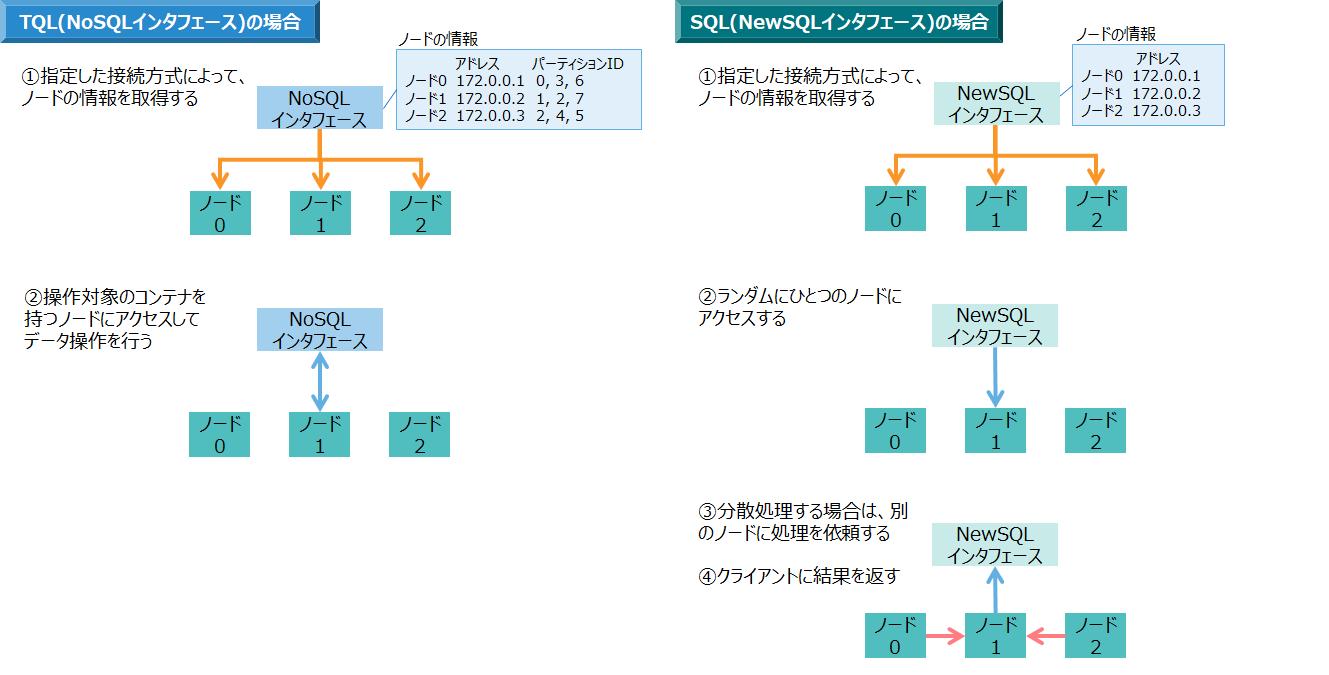
ノードのネットワークに関して設計すべき点は、ポート番号、帯域幅です。それぞれの設計のポイントについて説明します。
3.6.1.1 ポート番号
GridDBのノードが使用するポート番号には次の種類があります。
デフォルトでは以下の番号を使用します。もし他のアプリケーションなどで既に使用済みの場合は、デフォルトのポート番号を変更する必要があります。
| No | 項目 | 内容 | ポート番号 |
|---|---|---|---|
| A | トランザクション処理 | トランザクション処理を行うための通信用ポート | 10001 |
| B | SQL処理 | SQL処理を行うための通信用ポート | 20001 |
| C | 運用管理操作 | 運用管理の操作要求を受け付けるための通信用ポート | 10040 |
| D | クラスタ管理 | ノードの生存を確認するためのハートビートやクラスタ管理情報を授受するための通信用ポート | 10010 |
| E | 同期処理 | パーティション再配置によるデータ同期処理のための通信用ポート | 10020 |
クラスタ構成方式としてマルチキャスト方式を使用する場合には、以下の3つのポート番号も使用します。
| No | 項目 | ポート番号 |
|---|---|---|
| F | トランザクション処理用マルチキャスト | 31999 |
| G | SQL処理用マルチキャスト | 41999 |
| H | クラスタ管理用マルチキャスト | 20000 |
3.6.1.2 帯域幅
GridDBでは多くのデータを通信するため、ネットワークの帯域は10GbEの利用を推奨します。
特にデータ量が多くなる通信経路は以下の3箇所です。
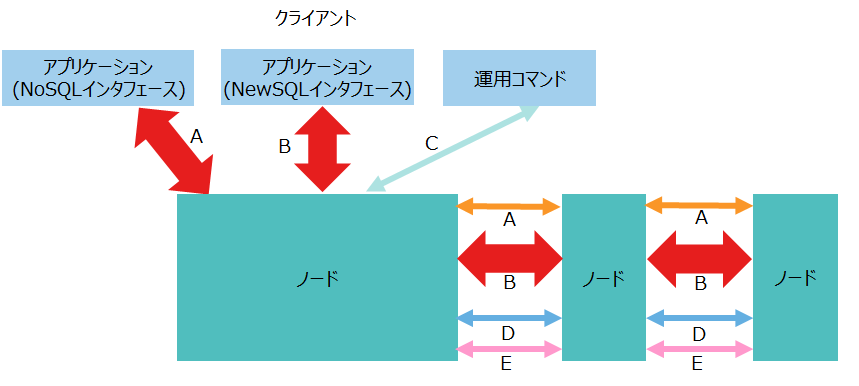
NoSQLインタフェースによるクライアントとノード間の通信(A)
- TQLで大量ヒットする検索を行った場合など、クラスタから大量のデータを取得する場合に通信量が多くなります。
NewSQLインタフェースによるクライアントとノード間の通信(B)
- SQLで大量ヒットする検索を行った場合など、クラスタから大量のデータを取得する場合に通信量が多くなります。
SQLの分散処理によるノード間の通信(B)
- 複数コンテナのジョインなど、複数のノードでSQLを分散処理する場合にノード間での通信量が多くなります。
データ通信量が多くネットワーク帯域が不足する場合には、複数のNICを用いて帯域を増やすことを推奨します。
例) 通常の場合
すべて同一IPアドレスで通信します。
No. 項目 IPアドレス A トランザクション処理 172.0.10.1 B SQL処理 172.0.10.1 C 運用管理操作 172.0.10.1 D クラスタ管理 172.0.10.1 E 同期処理 172.0.10.1
例) 通信量の多い場合
通信量が多い「トランザクション処理」や「SQL処理」の通信のIPアドレスを複数のNICを用いて分けます。
No. 項目 IPアドレス A トランザクション処理 172.0.10.2 B SQL処理 172.0.10.3 C 運用管理操作 172.0.10.1 D クラスタ管理 172.0.10.1 E 同期処理 172.0.10.1
3.6.2 クラスタ構成方式
GridDBは複数のノード間で相互に通信することでクラスタを構成します。各クライアントはこのクラスタに対して相互に通信することでアクセスが可能となります。前者のノード間の通信、後者のクライアントとクラスタ間の通信のための構成方式として、マルチキャスト方式、固定リスト方式、プロバイダ方式の3つから選択することができます。各構成方式のメリット・デメリットを下記に示します。ネットワーク環境や利用用途に応じて構成方式を選択します。
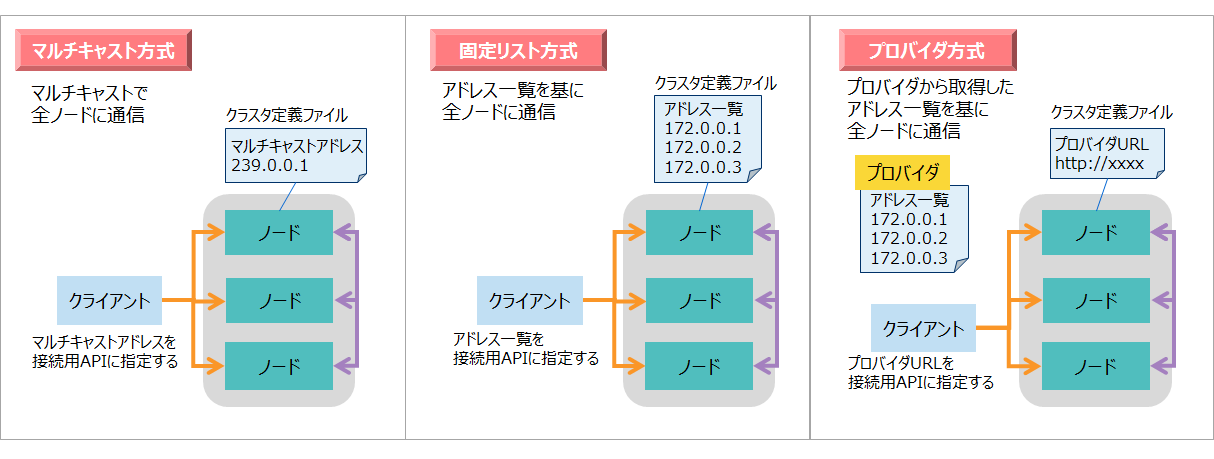
| 方式名 | 内容 | 設定・構築 | ノード増設時の停止 | ネットワーク環境 |
|---|---|---|---|---|
| マルチキャスト方式 | マルチキャスト通信を行う。 | ○ 定義ファイルの記述が容易 |
○ クラスタ停止不要 |
× 全ノードとクライアントを同一サブネットに配置しないと通信できない |
| 固定リスト方式 | 全ノードのアドレス一覧をクライアントとノードに設定する。 アドレス一覧を基にユニキャスト通信を行う。 |
× 定義ファイルの記述が複雑 |
× クラスタ停止が必要 |
○ 環境の制約はない |
| プロバイダ方式 | 全ノードのアドレス一覧をプロバイダに設定する。 クライアントとノードはプロバイダからアドレス一覧を取得してユニキャスト通信を行う。 |
× プロバイダの構築作業が必要 |
○クラスタ停止不要 | ○ 環境の制約はない |
クラスタ構成方式はクラスタ定義ファイルで指定します。デフォルトではマルチキャスト方式が設定されています。ただしマルチキャスト方式の場合は、ネットワーク環境に制約があるため注意が必要です。
マルチキャスト方式では、マルチキャスト通信の制限のため、クライアントとすべてのノードを同一サブネットに配置する必要があります。もし別のサブネットに存在している場合は、マルチキャスト通信できないため、ネットワーク上の全ルータでマルチキャストルーティングの設定を行う必要があります。
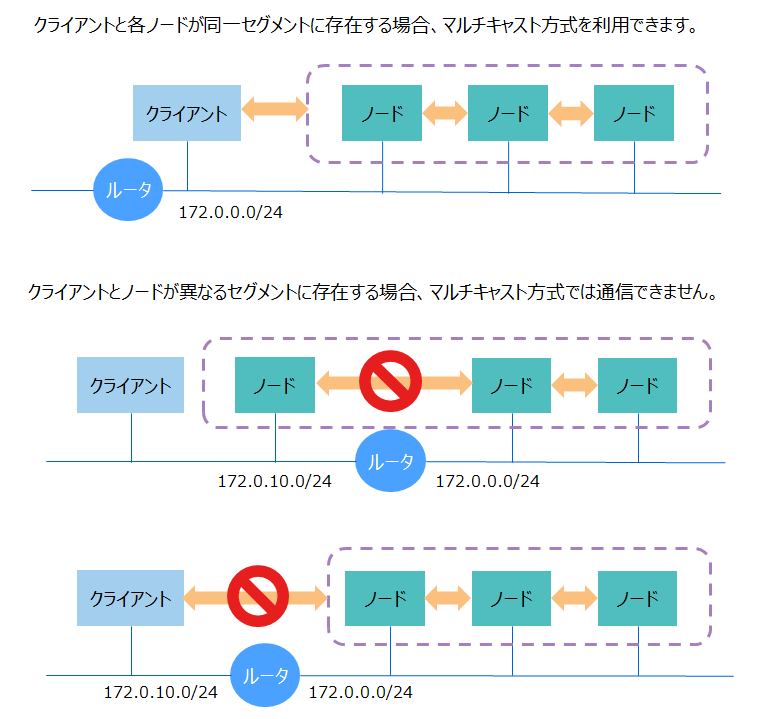
また、AWSなどのクラウド上ではマルチキャスト通信が使用できない場合があります。これらのマルチキャスト通信を使用できないケースでは、固定リスト方式またはプロバイダ方式を選択してください。
固定リスト方式とプロバイダ方式を比較した場合、設定や環境構築の面では固定リスト方式の方が容易です。プロバイダ方式では、アドレス一覧を提供するWebサービスを構築する必要があります。
一方、ノード増設に強いのはプロバイダ方式です。プロバイダが持つアドレス一覧の情報を変更すれば良いので、クラスタの停止は必要ありません。固定リスト方式の場合は、クラスタ定義ファイルを書き換える必要があるのでクラスタ停止が必要です。クライアント側の接続用APIの指定も変更する必要があります。 よって、ノードの増設が見込まれるシステムの場合は、プロバイダ方式を推奨します。
[メモ]
クライアントとは、NoSQLインタフェース/NewSQLインタフェースを用いてクラスタにアクセスするアプリケーションのことです。運用ツールの中では、統合運用管理GUI(gs_admin)やエクスポート/インポートツール、シェルコマンドgs_shなどが該当します。
同一サブネット内に、複数のクラスタ構成を構築することは可能です。
- クラスタ名は必ず異なる名前にしてください。
- マルチキャスト方式の場合は、クラスタごとに異なるマルチキャストアドレスにしてください。
各構成方式の詳細について、以下にまとめます。
3.6.2.1 マルチキャスト方式
マルチキャスト方式は、通信にマルチキャストを使用する方式です。マルチキャストとは、ひとつの送信元から、特定の複数の送信先に、同じデータを同時に送る通信のことです。
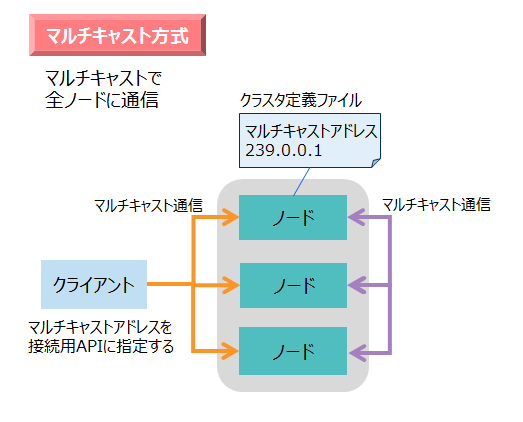
マルチキャスト方式を使用する場合は、クライアントとクラスタの全ノードをすべて同じサブネットに配置してください。もし別のサブネットに存在している場合は、そのままではマルチキャスト通信はできませんので、ネットワーク上の全ルータでマルチキャストルーティングの設定を行う必要があります。
マルチキャスト方式の場合、ノードはネットワークをポーリングして、マルチキャスト通信で一定周期で送信されたデータを受信します。即時受信しないので、通信開始までに一定周期分の時間が最大かかります。この周期の時間はクラスタ定義ファイルで指定できます。
- ノードおよびクライアントには、マルチキャストのアドレスとポート番号を指定します。
- マルチキャストのアドレスは、「239.0.0.0~239.255.255.255」の範囲が使用できます。
関連するパラメータ
● クラスタ定義ファイル(gs_cluster.json)
各通信ごとに、マルチキャストアドレス(notificationAddress)とポート番号(notificationPort)、周期(notificationInterval)の3つの項目を設定します。
| パラメータ | 初期値 | 内容 | 起動後の変更 |
|---|---|---|---|
| /cluster/notificationAddress | 239.0.0.1 | クラスタ管理用のマルチキャストアドレス | 可(クラスタ再起動) |
| /cluster/notificationPort | 20000 | クラスタ管理用のマルチキャストポート番号 | 可(クラスタ再起動) |
| /cluster/notificationInterval | 5s | クラスタ管理用のマルチキャスト周期 | 可(クラスタ再起動) |
| /transaction/notificationAddress | 239.0.0.1 | トランザクション処理用のマルチキャストアドレス | 可(クラスタ再起動) |
| /transaction/notificationPort | 31999 | トランザクション処理用のマルチキャストポート番号 | 可(クラスタ再起動) |
| /transaction/notificationInterval | 5s | トランザクション処理用のマルチキャスト周期 | 可(クラスタ再起動) |
| /sql/notificationAddress | 239.0.0.1 | SQL用のマルチキャストアドレス | 可(クラスタ再起動) |
| /sql/notificationPort | 41999 | SQL用のマルチキャストポート番号 | 可(クラスタ再起動) |
| /sql/notificationInterval | 5s | SQL用のマルチキャスト周期 | 可(クラスタ再起動) |
[メモ]
- 表の「起動後の変更」は、運用開始後にパラメータを変更できるかどうかを表します。
- 可(クラスタ再起動):パラメータを記載している定義ファイルを書き換えて、全ノードとクラスタを再起動すると変更できます。
3.6.2.2 固定リスト方式
固定リスト方式は、クラスタの全ノードのIPアドレスを、クライアントと各ノードに明示的に指定する方式です。アドレス一覧を基にユニキャスト通信を行います。
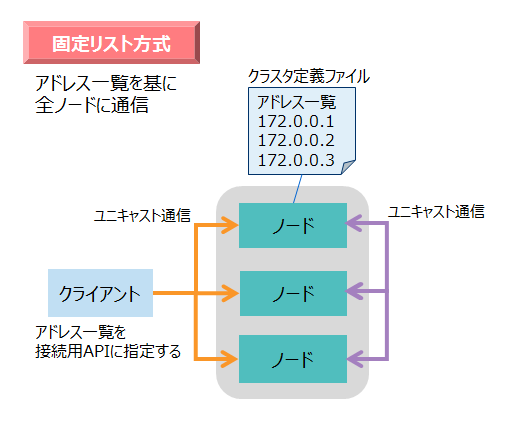
- アドレス一覧のIPアドレスとポート番号には、ネットワーク通信のIPアドレスとポート番号を指定します。
関連するパラメータ
クラスタ定義ファイル(gs_cluster.json)
パラメータ 初期値 内容 起動後の変更 /cluster/notificationMember - 各ノードのネットワーク通信IPアドレスとポート番号の一覧 可(クラスタ再起動) 例)クラスタ定義ファイルに記載するアドレス一覧
- ノード定義ファイル(gs_node.json)に記載されている、ネットワーク通信のIPアドレスとポート番号を一覧にします。
- ノード定義ファイルでIPアドレスの指定を省略している場合は、ホスト名と対応付けられているIPアドレスをアドレス一覧に記載してください。
"notificationMember": [ { "cluster": {"address":"172.0.0.1", "port":10010}, "sync": {"address":"172.0.0.1", "port":10020}, "system": {"address":"172.0.0.1", "port":10040}, "transaction": {"address":"172.0.0.1", "port":10001}, "sql": {"address":"172.0.0.1", "port":20001} }, { "cluster": {"address":"172.17.0.2", "port":10010}, "sync": {"address":"172.17.0.2", "port":10020}, "system": {"address":"172.17.0.2", "port":10040}, "transaction": {"address":"172.17.0.2", "port":10001}, "sql": {"address":"172.17.0.2", "port":20001} }, : :
[メモ]
- 表の「起動後の変更」は、運用開始後にパラメータを変更できるかどうかを表します。
- 可(クラスタ再起動):パラメータを記載している定義ファイルを書き換えて、全ノードとクラスタを再起動すると変更できます。
3.6.2.3 プロバイダ方式
プロバイダ方式は、クラスタの全ノードのIPアドレス一覧を配信するWebサービスを設置する方式です。クライアントや各ノードは、まずプロバイダにアクセスして、クラスタの全ノードのIPアドレスを取得します。
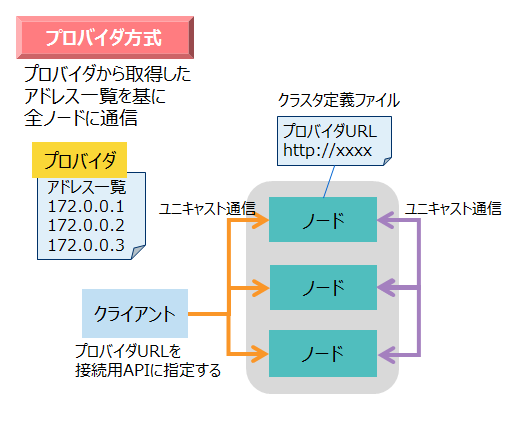
ノードは、起動時にプロバイダからアドレス一覧を取得します。その後も一定周期でプロバイダから最新のアドレス一覧を取得します。そのため、ノード増設などの場合はプロバイダのアドレス一覧を変更すれば、自動的にノードに情報が反映されます。
- ノードおよびクライアントには、プロバイダのURLを指定します。
- プロバイダには、ネットワーク通信のIPアドレスとポート番号を指定します。
関連するパラメータ
クラスタ定義ファイル(gs_cluster.json)
パラメータ 初期値 内容 起動後の変更 /cluster/notificationProvider/url - プロバイダのURL 可(クラスタ再起動) /cluster/notificationProvider/updateInterval 5s プロバイダからアドレス一覧を取得する間隔 可(クラスタ再起動)
[メモ]
- 表の「起動後の変更」は、運用開始後にパラメータを変更できるかどうかを表します。
- 可(クラスタ再起動):パラメータを記載している定義ファイルを書き換えて、全ノードとクラスタを再起動すると変更できます。
3.6.3 複数通信経路を用いたネットワーク構成
3.6.3.1 目的
GridDBは、クラスタとクライアント間の接続に対して複数の通信経路を設定することができます。何も設定を行わないデフォルトの場合は単一の通信経路となりますが、複数通信経路設定を行うとこれとは別の通信経路を用いた接続が可能となります。この通信経路を外部通信経路と呼びます。 複数通信経路を用いた構成は、主に以下の場合に用いられます。
- ユーザのオンプレミス環境から、クラウド環境にあるGridDBサービスを外部通信経路を用いて直接参照、操作を行うことにより、利便性を向上させたい。
- 外部通信経路とデフォルトの通信経路を同時に利用したアプリケーションを構築したい。
複数通信経路を用いた場合のネットワーク構成は以下のようになります。通常のノードネットワーク構成との違いは、新たに外部通信経路となる、A'(トランザクション処理用), B'(SQL処理用)が利用可能となったことです。各クライアントがどちらの通信経路を用いるかはクライアント個別に設定します。設定方法の詳細はクライアントごとに異なりますので、それぞれの設定マニュアルを確認してください。
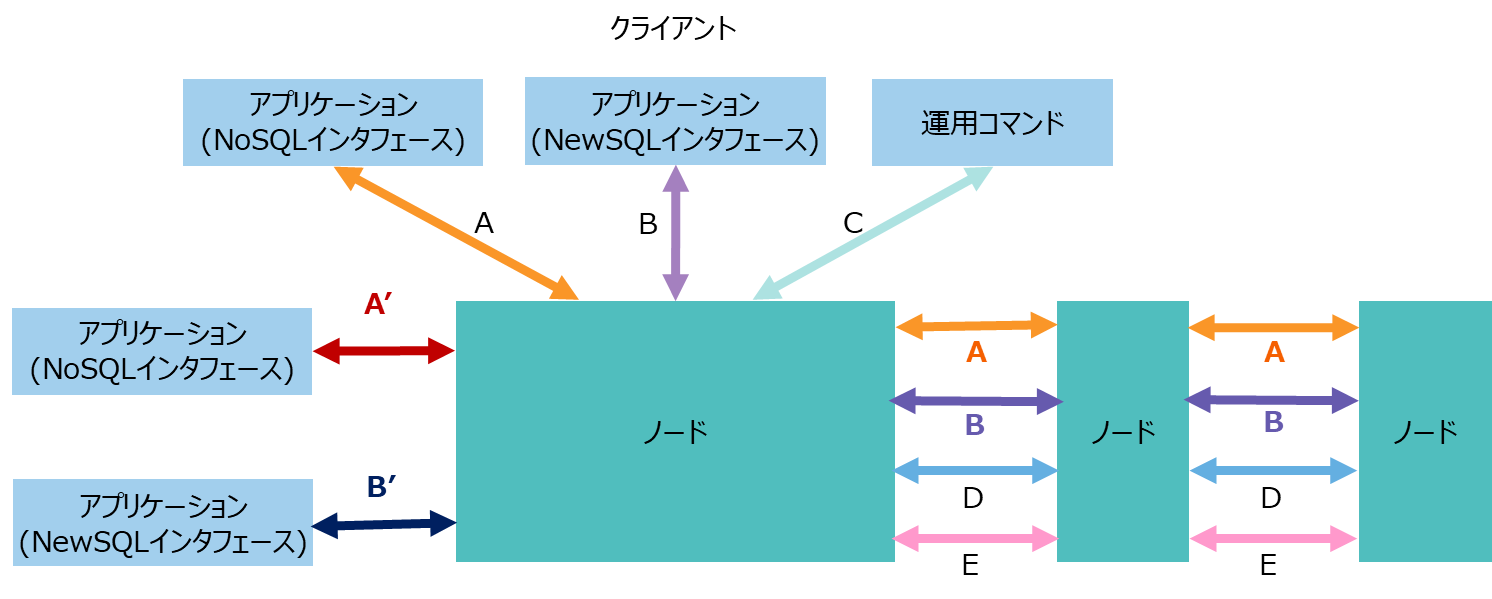
| No. | 項目 | 通信経路 | 説明 |
|---|---|---|---|
| A | トランザクション処理 | クライアント-ノード間、ノード間 | トランザクションのレプリケーション処理のための通信、NoSQLインタフェースを通じたデータ操作のための通信 |
| A' | トランザクション処理 | クライアント-ノード間 | NoSQLインタフェースを通じたデータ操作のための通信(外部通信経路) |
| B | SQL処理 | クライアント-ノード間、ノード間 | SQLの並列分散処理のための通信。NewSQLインタフェースを通じたデータ操作のための通信 |
| B' | SQL処理 | クライアント-ノード間 | NewSQLインタフェースを通じたデータ操作のための通信(外部通信経路) |
| C | 運用管理操作 | クライアント-ノード間 | 運用管理の操作要求を受け付けるための通信 |
| D | クラスタ管理 | ノード間 | ノードの生存を確認するためのハートビートや、クラスタ管理情報を授受するための通信 |
| E | 同期処理 | ノード間 | パーティションの再配置によるデータ同期処理のための通信 |
3.6.3.2 ノードのネットワーク構成
クライアントに対する複数接続経路を有効にする場合は、クラスタにおいて以下の設定を行います。
関連するパラメータ
■ノード定義ファイル(gs_node.json)
| パラメータ | 初期値 | 内容 | 起動後の変更 |
|---|---|---|---|
| /transaction/serviceAddress | - (ホスト名と対応付けられたIPアドレス) |
デフォルトのトランザクション処理用のアドレス | 可(ノード再起動) |
| /transaction/publicServiceAddress | "" | クライアント専用通信となる外部接続時のトランザクション処理用のアドレス | 可(ノード再起動) |
| /transaction/servicePort | 10001 | トランザクション処理用のポート番号 | 可(ノード再起動) |
| /sql/serviceAddress | - (ホスト名と対応付けられたIPアドレス) |
デフォルトのSQL処理用のアドレス | 可(ノード再起動) |
| /sql/publicServiceAddress | "" | クライアント専用通信となる外部接続時のSQL処理用のアドレス | 可(ノード再起動) |
| /sql/servicePort | 20001 | SQL処理用のポート番号 | 可(ノード再起動) |
[メモ]
- 表の「起動後の変更」は、運用開始後にパラメータを変更できるかどうかを表します。
- 可(ノード再起動):パラメータを記載している定義ファイルを書き換えて、ノードを再起動すると変更できます。
- 複数接続経路を有効にする場合は、外部通信経路に対応するIPアドレスを、 /transaction/publicServiceAddressと/sql/publicServiceAddressの両方に設定する必要があります。ポート番号はservicePortで共通のものとなります。
複数のノードでクラスタを構成する場合は、すべてのノードの設定が必要です。また、トランザクション処理用、SQL処理用以外のserviceAddressも省略せずに設定することを推奨します。
例)
"cluster":{
"serviceAddress":"192.168.10.11",
"servicePort":10010
},
"sync":{
"serviceAddress":"192.168.10.11",
"servicePort":10020
},
"system":{
"serviceAddress":"192.168.10.11",
"servicePort":10040,
:
},
"transaction":{
"serviceAddress":"192.168.10.11,
"publicServiceAddress":"172.17.0.11",
"servicePort":10001,
:
},
"sql":{
"serviceAddress":"192.168.10.11",
"publicServiceAddress":"172.17.0.11",
"servicePort":20001,
:
},
3.6.3.3 クラスタのネットワーク構成
ノードのネットワーク構成に合わせて、クラスタのネットワーク構成を設定します。マルチキャスト方式の場合、特別な設定は不要です。マルチキャスト方式を参照ください。但し、外部通信経路を用いる場合、構成方式としてマルチキャスト方式は未サポートとなります。この場合は固定リスト方式、もしくはプロバイダ方式をご利用ください。固定リスト方式の場合、クラスタ定義ファイルに設定するノードアドレス一覧(notificationMember)に外部通信用のIPアドレスとポート番号(transactionPublic, sqlPublic)を追加する必要があります。
例)
"notificationMember": [
{
"cluster": {"address":"192.168.10.11", "port":10010},
"sync": {"address":"192.168.10.11", "port":10020},
"system": {"address":"192.168.10.11", "port":10040},
"transaction": {"address":"192.168.10.11", "port":10001},
"sql": {"address":"192.168.10.11", "port":20001},
"transactionPublic": {"address":"172.17.0.11", "port":10001},
"sqlPUblic": {"address":"172.17.0.11", "port":20001}
},
{
"cluster": {"address":"192.168.10.12", "port":10010},
"sync": {"address":"192.168.10.12", "port":10020},
"system": {"address":"192.168.10.12", "port":10040},
"transaction": {"address":"192.168.10.12", "port":10001},
"sql": {"address":"192.168.10.12", "port":20001},
"transactionPublic": {"address":"172.17.0.12", "port":10001},
"sqlPublic": {"address":"172.17.0.12", "port":20001}
},
:
:
プロバイダ方式におけるノードアドレス一覧は、固定リスト方式のノードリストのフォーマットと同じとなります。
例)
[
{
"cluster": {"address":"192.168.10.11", "port":10010},
"sync": {"address":"192.168.10.11", "port":10020},
"system": {"address":"192.168.10.11", "port":10040},
"transaction": {"address":"192.168.10.11", "port":10001},
"sql": {"address":"192.168.10.11", "port":20001},
"transactionPublic": {"address":"172.17.0.11", "port":10001},
"sqlPublic": {"address":"172.17.0.11", "port":20001}
},
{
"cluster": {"address":"192.168.10.12", "port":10010},
"sync": {"address":"192.168.10.12", "port":10020},
"system": {"address":"192.168.10.12", "port":10040},
"transaction": {"address":"192.168.10.12", "port":10001},
"sql": {"address":"192.168.10.12", "port":20001},
"transactionPublic": {"address":"172.17.0.12", "port":10001},
"sqlPublic": {"address":"172.17.0.12", "port":20001}
},
:
:
[メモ]
- クライアントで外部接続指定を行わない場合は、デフォルト通信経路が用いられます。
3.7 セキュリティ設計
3.7.1 アクセス制御
セキュリティ設計では、アクセスするユーザ数やデータのアクセス範囲などの一般的なセキュリティ要件を検討した後、それに基づいて次の点を設計する必要があります。
- アプリケーションから接続するための「一般ユーザ」とアクセスするデータの範囲「データベース」
- ユーザとデータベースの対応付け
GridDBでは、ユーザごとにデータにアクセスする範囲を分ける場合には、「データベース」機能を用いてアクセス範囲を分離することができます。
一般ユーザは複数のデータベースに対するアクセス権を持つことができますが、データベースをまたがったSQL検索(異なるデータベース上のコンテナのジョインなど)はできないため、ひとりのユーザがアクセスするコンテナはなるべくひとつのデータベースにまとめることを推奨します。
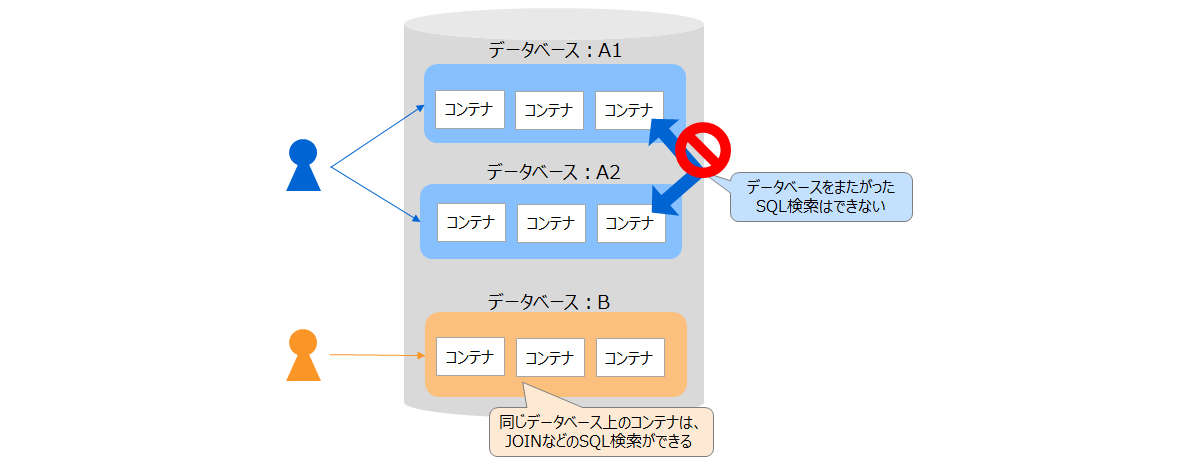
- データベースへのアクセス権の種類は「ALL」「リードオンリー」です。「ALL」権限はコンテナ作成やロウ登録、検索、索引作成などコンテナに関するすべての操作が実行できます。「リードオンリー」権限は検索の操作のみ実行できます。
- 一般ユーザは、アクセス権限があるデータベース上のコンテナにしかアクセスできません。
- 管理ユーザは、すべてのデータベース上のコンテナにアクセスできます。
ユーザの役割
| ユーザ | 役割 |
|---|---|
| 管理ユーザ | データベース、一般ユーザを作成します。一般ユーザにデータベースへのアクセス権を付与します。 |
| 一般ユーザ | アクセス権が付与されたデータベースにアクセスして、データ登録や検索などの操作を行います。 |
3.7.1.1 操作手順
一般ユーザとデータベースを作成して、アクセス権を付与する手順を説明します。ここでは「ALL」権限を付与するものとします。
- 管理ユーザでクラスタに接続します。
$ gs_sh
gs> setcluster cluster myCluster 239.0.0.1 31999 // 接続先のクラスタの情報を設定
gs> setuser admin admin // 管理ユーザのユーザ名とパスワードを指定
gs> connect $cluster // クラスタに接続
gs[public]>
- 一般ユーザを作成します。
gs[public]> createuser userA password
- データベースを作成します。
gs[public]> createdatabase databaseA
- 一般ユーザにデータベースへのアクセス権を付与します。
gs[public]> grantacl ALL databaseA userA
3.7.2 暗号化
GridDBでは、クライアントとGridDBクラスタ間の通信をSSLで保護することができます。詳細は『GridDB 機能リファレンス』(GridDB_FeaturesReference.html)を参照ください。
一方、データベースファイルに保存しているデータは暗号化していません。外部から直接アクセスできない安全なネットワーク上への配置を推奨します。
3.8 監視設計
GridDBクラスタの監視設計のポイントについて、以下にまとめます。GridDBの稼働状況やリソースの使用状況の確認は、パフォーマンスの最適化、障害発生の未然回避のために必要です。監視項目は、システムのサービスレベルにより異なります。
GridDBステータス監視
ノードやクラスタに異常が発生していないかgs_statでステータス監視します。
項目 内容 異常値 ノードステータス /cluster/nodeStatusを監視します ABNORMALになった場合は異常 パーティションステータス /cluster/partitionStatusを監視します OWNER_LOSSになった場合は異常 OSリソース監視
OSリソース不足が発生していないか、OSコマンドで使用状況を確認します。
項目 内容 プロセス監視 gsserver/gssvcプロセスを監視します CPU監視 ノードのCPU使用率、プロセッサキューなどを監視します メモリ監視 ノードのメモリ使用量、スワップイン・アウト量などを監視します ディスク監視 DBファイルサイズ、IOPS、IOスループット、キューなどを監視します GridDBリソース監視
障害や性能ボトルネックが発生していないか、GridDBのイベントログより、GridDBの稼働状況詳細を確認します。
項目 内容 メモリ監視 storeMemoryのメモリ使用量やその内訳(データ、索引、メタデータなど)を監視します。 ディスク監視 データ、索引、メタデータのディスク使用量やSwapRead/Writeなどを監視します。 クエリ監視 GridDBのイベントログより、遅いクエリのログを取得します。 - ログの確認方法は、『GridDB 運用ツールリファレンス』(GridDB_OperationToolsReference.html)のgs_logs「ログの表示」をご参照ください。
- スロークエリの閾値などの設定方法は、『GridDB 運用ツールリファレンス』(GridDB_OperationToolsReference.html)のgs_paramconf「パラメータ表示と変更」をご参照ください。
ノードの処理が進まない場合、重たいトランザクション処理が行われている可能性があります。ノードで現在実行中のイベントの一覧は、運用ツールgs_shで確認することができます。
- 現在実行中の処理一覧の確認方法は、『GridDB 運用ツールリファレンス』(GridDB_OperationToolsReference.html)のgs_sh「実行中イベントの表示」をご参照ください。
これらの監視項目は、以下のようにZabbixを使用して監視することもできます。
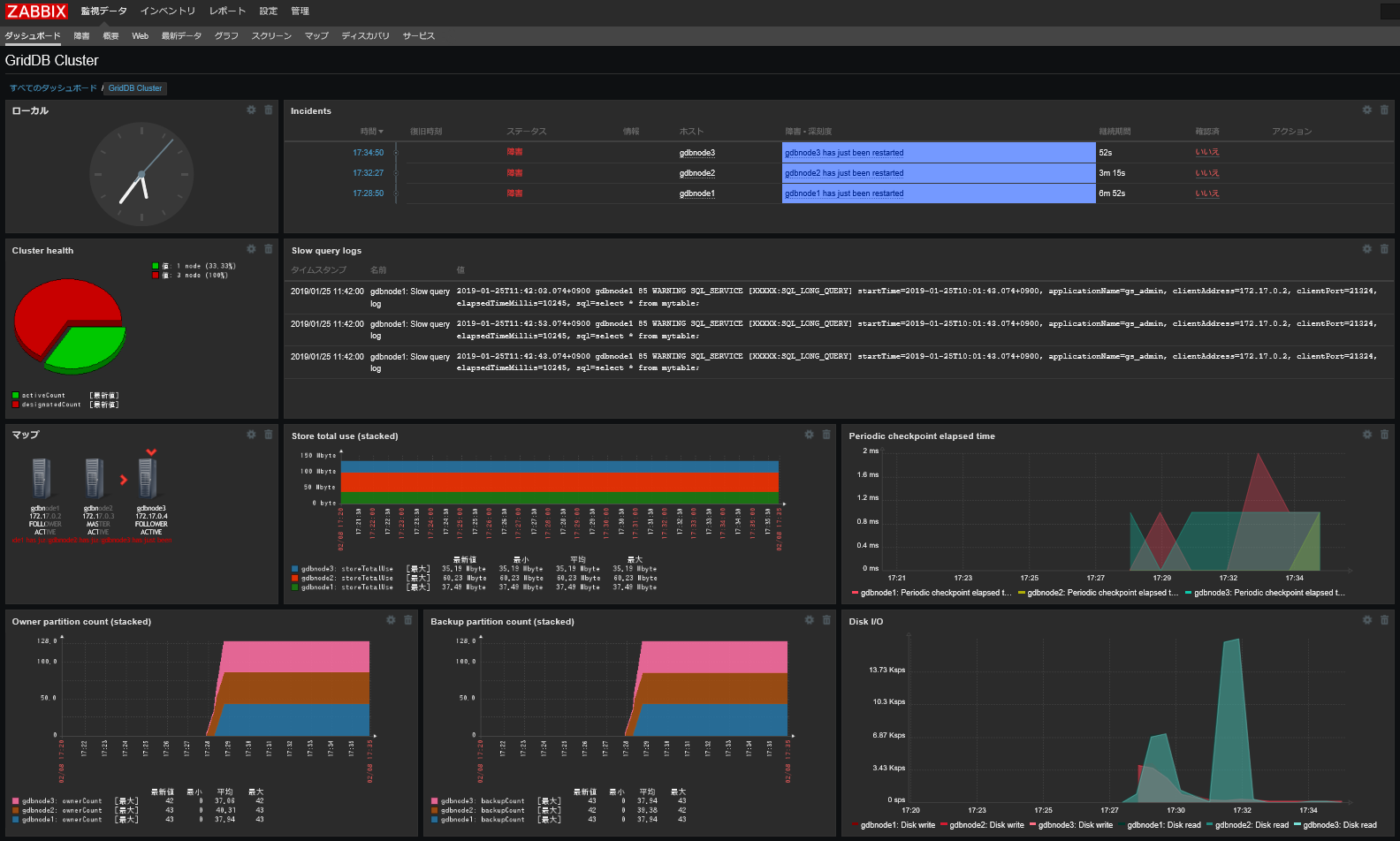
Zabbix用の監視テンプレートについては、『GridDB 監視テンプレート for Zabbix 説明書』(GridDB_ZabbixTemplateGuide.html)をご参照ください。
3.9 バックアップ設計
3.9.1 バックアップの目的
ハードウェアの多重障害やアプリケーションの誤動作によるデータ破壊に備えるために、バックアップを採取します。
ハードウェア多重障害によるデータ破壊の場合
GridDBでは、レプリケーション機能によってデータの複製を他のノードに分散して保持しています。そのため、レプリカ数未満のノードでデータ破壊が発生した場合は、自動的に他のノードの複製からデータが復元されるため、バックアップからのリカバリは不要です。
レプリカ数以上のノードでデータ破壊が同時に発生した場合には、データが消失してしまうため、バックアップからのリカバリが必要になります。
なお、データ破壊以外の多重障害の場合は、障害が発生したノードを復帰すればデータは復元されるので、バックアップからのリカバリは不要です。
例) ノード5台、レプリカ数2の場合

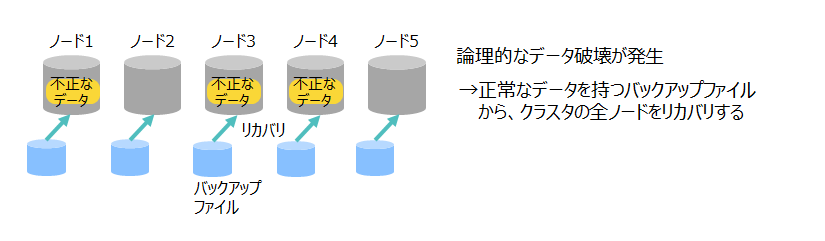
複数のノードで発生したデータ破壊の場合
アプリケーションの誤動作の場合
アプリケーションの誤動作やユーザのデータ登録ミスなどによって、誤ったデータが登録されてしまい復元できない場合には、バックアップからのリカバリが必要になります。 この場合は、クラスタの全ノードに対してバックアップからリストアします。
アプリケーションの誤動作の場合
3.9.2 設計のポイント
一般的に、バックアップ・リストア要件は、システムのサービスレベルより定義します。検討項目は以下です。
- 対象となる課題(災害、ハードウェア故障、オペレーションミスなど)
- システム継続に必須なデータ範囲(全コンテナ、一部コンテナ、直近データなど)
- 目標の復旧時点(障害発生前のどの時点のデータが必要か)
- 復旧までの目標時間
- バックアップを実行可能な時間帯と条件(クラスタ停止可能かなど)
- バックアップの頻度
- バックアップの世代数
- バックアップの保管場所(オンサイト、別メディアなど)
GridDBでは、以下のバックアップ・リストア方式を提供します。上記で定義した要件を満たす方式を選択してください。
| バックアップ方式 | 復旧時点 | 特徴 (○:メリット、×:デメリット) |
|---|---|---|
| クラスタ管理によるレプリカ自動作成 | 障害直前時点 | ○:クラスタ設定でレプリカ数を指定すれば、クラスタがノード間で自動的にレプリカを作成、管理します。 ×:レプリカ数以上HWが同時破損した場合、もしくは人的ミスが発生した場合には対応できません。 |
| gs_exportツールによるデータのエクスポート | データのエクスポート時点 ※コンテナごと |
○:必要なデータのみバックアップでき、バックアップサイズを小さくすることができます。 ×:エクスポートツールを実行するため、運用中のクラスタに負荷をかける可能性があります。 ×:データの復旧には、データの再インポートが必要です。 ×:エクスポートはコンテナごとに処理するため、コンテナごとに復旧時点が異なる可能性があります。 |
| オフラインバックアップ | クラスタ停止時点 | ○:ノード間で復旧時点が異なることはありません。 ×:バックアップファイル作成完了までクラスタ停止が必要です。 |
| ノードによるオンラインバックアップ(フル+差分・増分) | バックアップ採取時点 ※ノードごと |
○:GridDBバックアップコマンドを利用して、オンラインでバックアップが取得できます。 ×:バックアップの取得完了のタイミングにより、ノード間で復旧時点が異なることがあります。 |
| ノードによるオンラインバックアップ(自動ログ) | 障害直前時点 | ○:GridDBバックアップコマンドを利用して、オンラインでバックアップが取得できます。また、障害直前時点まで復旧が可能です。 ×:トランザクションログから最新状態にリカバリするため、リカバリ時間が長くなることがあります。 |
| ファイルシステムレベルのオンラインバックアップ(クラスタスナップショット) | クラスタスナップショット取得時点 | ○:OSのスナップショットやストレージのスナップショットと連携してバックアップを行うことでバックアップの実行時間を短くすることが可能です。 ○:クラスタ全体で一貫性を取ります。ノード間で復旧時点が同じになります。 ×:バックアップ取得開始直前から完了までの間、リバランス処理(障害に備えたデータの再配)の停止、チェックポイント処理の停止が必要です。 |
バックアップ方式の選択の目安は以下になります。
| バックアップの要件や用途 | バックアップ方式 |
|---|---|
| レプリカ数以上のHW同時破損もしくは人的ミスによるデータ損失を許容できる場合 | クラスタ管理によるレプリカ自動作成 |
| バックアップすべきデータを選択できる場合 | gs_exportツールによるデータのエクスポート |
| バックアップ実行時に、システム停止可能な場合 | オフラインバックアップ |
| バックアップ実行時に、システム停止できない場合(クラスタとしての一貫性は不要な場合) | ノードによるオンラインバックアップ |
| バックアップ実行時に、システム停止できず、クラスタとしての一貫性を保持したい場合 データベースファイルが巨大で、時間内にオンラインバックアップが終わらない場合 |
ファイルシステムレベルのオンラインバックアップ(クラスタスナップショット) |
3.9.3 バックアップ・リストアの方法
各バックアップ方法について、バックアップやリストアにかかる時間やメリット・デメリットを説明します。操作の詳細は『GridDB 機能リファレンス』(GridDB_FeaturesReference.html)を参照ください。
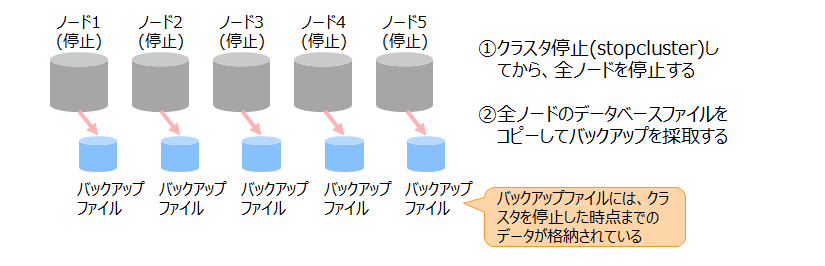
3.9.3.1 オフラインバックアップ
オフラインでバックアップを採取します。
クラスタと全ノードを停止して、OSのコマンドやストレージのスナップショットによってデータベースファイルをコピーします。全ノードでのコピー完了後に、ノードとクラスタを起動します。
| メリット | - クラスタを停止してからバックアップを採取するので、ノード間で復旧時点が同じになります。 - ノードを停止して採取したバックアップなので、リストアが高速です。 |
| デメリット | - クラスタ・ノードの停止が必要なので、サービスの稼動を停止できないシステムでは利用できません。 |
| バックアップ時間 | データベースファイルのコピー時間 |
| 復旧時点 | クラスタ停止時点 |
| リカバリ時間 | バックアップファイルコピー時間 |
3.9.3.2 オンラインバックアップ
クラスタ稼動中に、オンラインで各ノードのバックアップを採取します。
オンラインバックアップは、バックアップファイルの作成方法で大きく2つの方法があります。
ノードによるオンラインバックアップ
- バックアップコマンドを用いてGridDBノードでバックアップファイルを作成する方法
クラスタスナップショットによるファイルシステムレベルのオンラインバックアップ
- クラスタスナップショット復元情報ファイル作成コマンドと、OSのスナップショットやストレージのスナップショットと連携してファイルシステムレベルでクラスタとしての一貫性保持したバックアップファイルを作成する方法
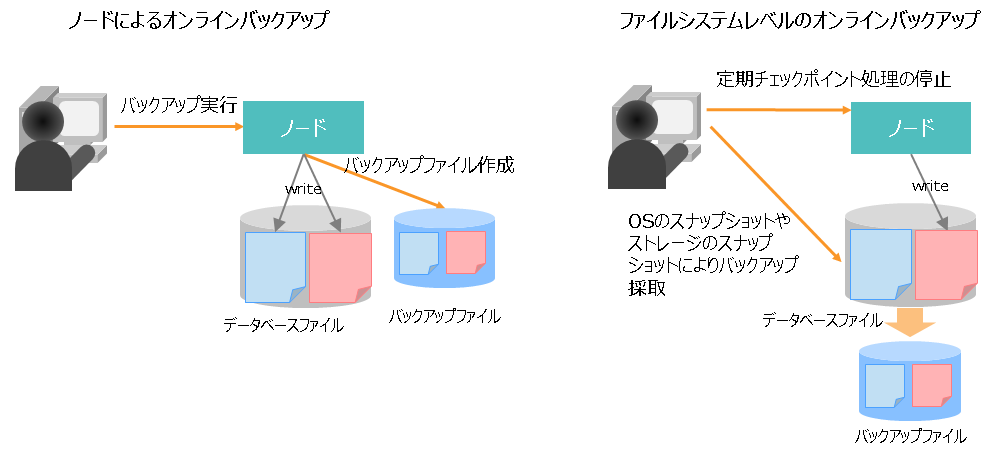
2つの方法の大きな違いは、次の点になります。
| 方法 | 復旧時点 |
|---|---|
| ノードによるオンラインバックアップ | ノードごとのバックアップ採取完了時点 →ノードごとにバックアップするデータ量が異なるので、完了時点が大きくずれる場合がある。復元後の同期処理が発生する可能性がある。 |
| クラスタスナップショットによるファイルシステムレベルのオンラインバックアップ | クラスタスナップショット取得時点 →クラスタを構成する各ノードの復旧時点を同じにすることができるので、復元後の同期処理が不要で、素早く安定状態になる。 |
3.9.3.3 ノードによるオンラインバックアップ
ノードによってオンラインバックアップを採取する方法を説明します。
※この方法でノードごとにバックアップを取得した場合、クラスタとしての一貫性は保持されません。クラスタとしての一貫性を保持する必要がある場合は、「クラスタスナップショットによるファイルシステムレベルのオンラインバックアップ」を参照してください。
3.9.3.3.1 フルバックアップ
データベース全体をバックアップします。
ノード単位でバックアップコマンドを用いてフルバックアップを指示すると、ノードがデータベースファイルのすべてのデータをコピーしてバックアップファイルを作成します。
| メリット | - 差分・増分バックアップよりもリストアが高速です。( リカバリ時間:フル < 差分 < 増分 ) - クラスタを稼動中にバックアップを採取できます。 |
| デメリット | - データベースファイルのすべてのデータをコピーするため、バックアップに時間がかかります。( バックアップ時間:増分 < 差分 < フル ) - 複数世代のバックアップを保管する場合、データベースファイルのサイズ×世代数のディスク容量が必要になります。 - 復旧時点はノードごとのバックアップ採取完了時点になるので、ノード間での復旧時点に差ができる場合があります。 |
| バックアップ時間 | ノードがバックアップファイルを作成する時間(データベースファイルのサイズに依存する) |
| 復旧時点 | ノードごとのバックアップ採取完了時点。 |
| リカバリ時間 | バックアップファイルコピー時間 |
3.9.3.3.2 差分バックアップ
基点となるフルバックアップ(ベースライン)を採取した後、ベースラインからの更新分のみをバックアップします。
ノード単位でバックアップコマンドを用いて差分バックアップを指示すると、ノードがベースラインからの更新データのみをコピーしてバックアップファイルを作成します。
| メリット | - フルバックアップよりはバックアップが高速です。( バックアップ時間:増分 < 差分 < フル ) - 増分バックアップよりもリカバリが高速です。( リカバリ時間:フル < 差分 < 増分 ) - クラスタを稼動中にバックアップを採取できます。 |
| デメリット | - 増分バックアップよりはバックアップに時間がかかります。 - 復旧時点はノードごとのバックアップ採取完了時点になるので、ノード間での復旧時点に差ができる場合があります。 |
| バックアップ時間 | ノードがバックアップファイルを作成する時間(ベースライン以降の更新データ量に依存する) |
| 復旧時点 | ノードごとのバックアップ採取完了時点 |
| リカバリ時間 | バックアップファイルコピー時間 差分のあるブロックのリカバリ時間 |
3.9.3.3.3 増分バックアップ
基点となるフルバックアップ(ベースライン)を採取した後、前回バックアップ時点からの更新分のみをバックアップします。前回バックアップ時点は、ベースライン、差分、増分のいずれかのバックアップを実行した時点を指します。
ノード単位でバックアップコマンドを用いて増分バックアップを指示すると、ノードが前回バックアップ時点からの更新データのみをコピーしてバックアップファイルを作成します。
| メリット | - フルバックアップや差分バックアップよりもバックアップが高速です。( バックアップ時間:増分 < 差分 < フル ) - クラスタを稼動中にバックアップを採取できます。 |
| デメリット | - ベースラインまたは差分バックアップ以降の増分バックアップをすべてリストアする必要があるため、フルバックアップや差分バックアップよりはリストアに時間がかかります。( リカバリ時間:フル < 差分 < 増分 ) - 復旧時点はノードごとのバックアップ採取完了時点になるので、ノード間での復旧時点に差ができる場合があります。 |
| バックアップ時間 | ノードがバックアップファイルを作成する時間(前回バックアップ時点以降の更新データ量に依存する) |
| 復旧時点 | ノードごとのバックアップ採取完了時点 |
| リカバリ時間 | バックアップファイルコピー時間 差分、増分ブロックリカバリ時間 |
3.9.3.3.4 自動ログバックアップ
基点となるフルバックアップ(ベースライン)を採取した後、トランザクションログをバックアップディレクトリに収集します。
| メリット | - 最新のトランザクションログがバックアップファイルに反映されるので、障害直前の状態までリストアすることができます。 |
| デメリット | - 通常運用中に自動的にトランザクションログをコピーするので、運用に多少の負荷がかかります。 - リストアに時間がかかります。 |
| バックアップ時間 | なし(ベースラインの作成後は自動的にログをコピーするので、バックアップを実行する必要はありません) |
| 復旧時点 | 障害直前の時点 |
| リカバリ時間 | バックアップファイルコピー時間 トランザクションログに格納された更新ログのリカバリ時間 |
3.9.3.4 クラスタスナップショットによるファイルシステムレベルのオンラインバックアップ
クラスタスナップショットによるファイルシステムレベルのオンラインバックアップについて説明します。
クラスタスナップショット復元情報ファイル作成コマンドと、LVMスナップショットやストレージのスナップショット機能を用いてクラスタ全体の一貫性を保持したオンラインバックアップを実行できます。 バックアップに要する時間を大幅に短縮できるほか、クラスタの全ノードで復旧時点をそろえることができます。
クラスタとしての一貫性を保持したい場合、およびデータベースファイルが巨大な場合に、利用を検討してください。
| メリット | - LVMやストレージのスナップショット機能を利用して、巨大なデータベースファイルを高速に処理することができます。 - クラスタとしての一貫性を保持してバックアップできるので、復元後にクラスタを構成したときに同期処理が不要で素早く安定状態になります。 |
| デメリット | - LVMやストレージのスナップショット機能が必要です。 - バックアップ取得開始直前から完了までの間、リバランス処理(障害に備えたデータの再配)の停止、チェックポイント処理の停止が必要です。 |
| バックアップ時間 | データベースファイルのスナップショット/コピーファイルを作成する時間 |
| 復旧時点 | クラスタスナップショット取得時点 |
| リカバリ時間 | バックアップファイルコピー時間 |
3.10 サイト間データベースレプリケーション
3.10.1 サイト間データベースレプリケーションの目的
GridDBは、サイト間データベースレプリケーション機能を用いることで、障害発生時のディザスタリカバリや、リードレプリカとして複数サイトを横断したデータベース利用が可能となります。構成としてはコールドスタンバイ方式とホットスタンバイ方式のいずれかが選択できます。
コールドスタンバイ方式は、待機系のデータベースは非稼働状態で運用して、障害発生時に切り替える方式です。これらは障害復旧時間に余裕があるディザスタリカバリに適しています。詳細は『リージョン間ディザスタリカバリ設定ガイド』(GridDB_Disaster_Recovery_Guide.html)を参照ください。
もう一つはホットスタンバイ方式を用いた実現です。コールドスタンバイ方式と比較して、障害復旧時間を短縮できることに加え、待機系リードレプリカとして運用することも可能です。サイト間データベースレプリケーションは主に以下の機能を用いて実現できます。これら機能の詳細に関しては『GridDB 機能リファレンス』(GridDB_FeaturesReference.html)を参照ください。
自動アーカイブ機能
- トランザクションログを自動的に指定フォルダに複製する機能です。
スタンバイモード機能
- クラスタをリードオンリーとして稼働させる機能です。
トランザクションログ適用機能
- 指定したトランザクションログをサーバに適用する機能です。
3.10.2 設計のポイント
サイト間データベースレプリケーションの実現のための検討項目は主に以下のものがあげられます。
- 対象となる課題(災害、ハードウェア故障、オペレーションミスなど)
- システム継続に必須なデータ範囲(全コンテナ、一部コンテナ、直近データなど)
- 復旧までの目標時間(RPO)
- 復旧目標時点(RTO)
- 単位時間あたりのデータ更新量
- 拠点間のネットワーク帯域
- チェックポイント間隔(トランザクションログ生成単位)
- バックアップ、自動アーカイブの保管場所(容量、性能)
- バックアップ機能との併用可能性
- 拠点間クラスタ状態監視(クラスタ間フェイルオーバ実施判定)
- 運用コスト
以下に、GridDBにおける3つの可用性構成についてのメリット、デメリットを示します。
| 可用性構成 | 復旧時点 | 拠点障害耐性 | 特徴 (○:メリット、×:デメリット) |
|---|---|---|---|
| 1. 単一クラスタ方式 | 障害直前時点 | なし | ○:拠点内ノード障害のレプリカ数分の可用性を保証します。 ×:レプリカ数以上の同時障害が発生した場合はサービス継続ができません。 ×:拠点全体障害時もサービス継続できません。 |
| 2.コールドスタンバイ方式 | プライマリクラスタのフルバックアップ生成時点 | あり | ○:拠点障害発生時にスタンバイ側で、プライマリのフルバックアップ時生成時点までの状態で復旧することができます。 ×:データ規模に比例してサービス再開までの時間を要します。 ×:障害復旧時点が長くなる傾向があります。 ×プライマリ稼働中はスタンバイへのアクセスはできません。 |
| ホットスタンバイ方式 | スタンバイへの転送済トランザクションログ | あり | ○:トランザクションログ単位での復旧が可能となります。 ○:プライマリ稼働中もスタンバイがリードオンリークラスタとしての利用できます ×:定常的にトランザクションログ転送が必要になりますので、ネットワーク帯域など事前設計およびチューニングが必要となります。 |
選択の目安をまとめると以下になります。
| 要件や用途 | 方式 |
|---|---|
| 単一拠点であり、レプリカ数以上の同時ノード障害や、拠点全体のノード障害が許容できる | 1.単一クラスタ方式 |
| 拠点障害対応(ディザスタリカバリ)が必要で、拠点障害発生時の障害復旧時間や障害復旧時点は1日単位レベルを許容する。待機系のリードレプリカ運用は不要 | 2.サイト間データベースレプリケーション(コールドスタンバイ方式) |
| 拠点障害対応(ディザスタリカバリ)が必要で、拠点障害発生時の害復旧時間や障害復旧時点は短時間が求められ、待機系をリードレプリカ運用を行いたい | 3.サイト間データベースレプリケーション(ホットスタンバイ方式) |
3.10.3 サイト間データベースレプリケーション(ホットスタンバイ方式)の注意点
各機能の詳細および運用手順は『GridDB 機能リファレンス』(GridDB_FeaturesReference.html)を参照ください。以下はホットスタンバイ方式を用いた運用を行うにあたって、特に性能やリソース面で注意すべき点を示します。
「トランザクションログファイル」を用いてレプリケーションを行います。トランザクションログファイルはチェックポイント実行単位で生成されますので、定周期で実行されるチェックポイント間隔の設定を運用開始前に決定してください。
トランザクションログファイルをプライマリからスタンバイへ定期的に転送する必要があります。事前に転送するサイズとネットワーク帯域的に十分かどうかを検証しておく必要があります。
自動アーカイブ機能ではトランザクションログファイルを、指定したアーカイブフォルダに出力しますが、これらはサーバや管理ツールによって自動的に削除されることはありません。運用側で適宜圧縮もしくは削除するなどを行ってください。
自動アーカイブ機能では通常のトランザクションログファイルを重複出力することになります。通常処理の更新操作においても若干のオーバヘッドがありますので、事前に更新性能が十分であるか確認してください。
3.11 監査ログ設計
3.11.1 監査ログの目的
データベース監査を実施するには、従来のイベントログでは以下の理由により不十分となります。
イベントログは操作対象となった接続先のIPアドレスや、操作対象のデータベース/テーブルが何かなどが表示されません。
フォーマットが統一されておらず、可読性が低いことから、機械的な分析を行うことも困難となります。
監査ログファイルの生成個数に上限があるため、大量のイベントログが記録される場合、監査漏れが発生する可能性があります。
GridDBは「監査ログ機能」を有効とすることで上記問題に対応可能となり、主に以下の観点からデータベース監査を実施することができます。
不正な接続検知および対策
- 特定不明な接続要求や、一定期間に連続で発生した接続要求があった場合、監査ログを分析して、接続要求先のIPアドレスなどの情報を特定します。この情報を用いて速やかにアクセス制限など適切な処置を行うことができます。
不正な操作検知および対策
- 監査対象のデータに対して不正な操作が実施された場合に、監査ログを分析して該当操作を行ったユーザおよびその接続情報や操作内容を 特定し、影響範囲などを確認します。不正操作により異常が発生した場合は、そのエラーログも併せて特定します。
データ改竄検知および対策
- 監査対象のデータに対して不正なアクセスおよびデータ改ざんなど不正な操作が行われていないことを、監査ログを用いて証明します。
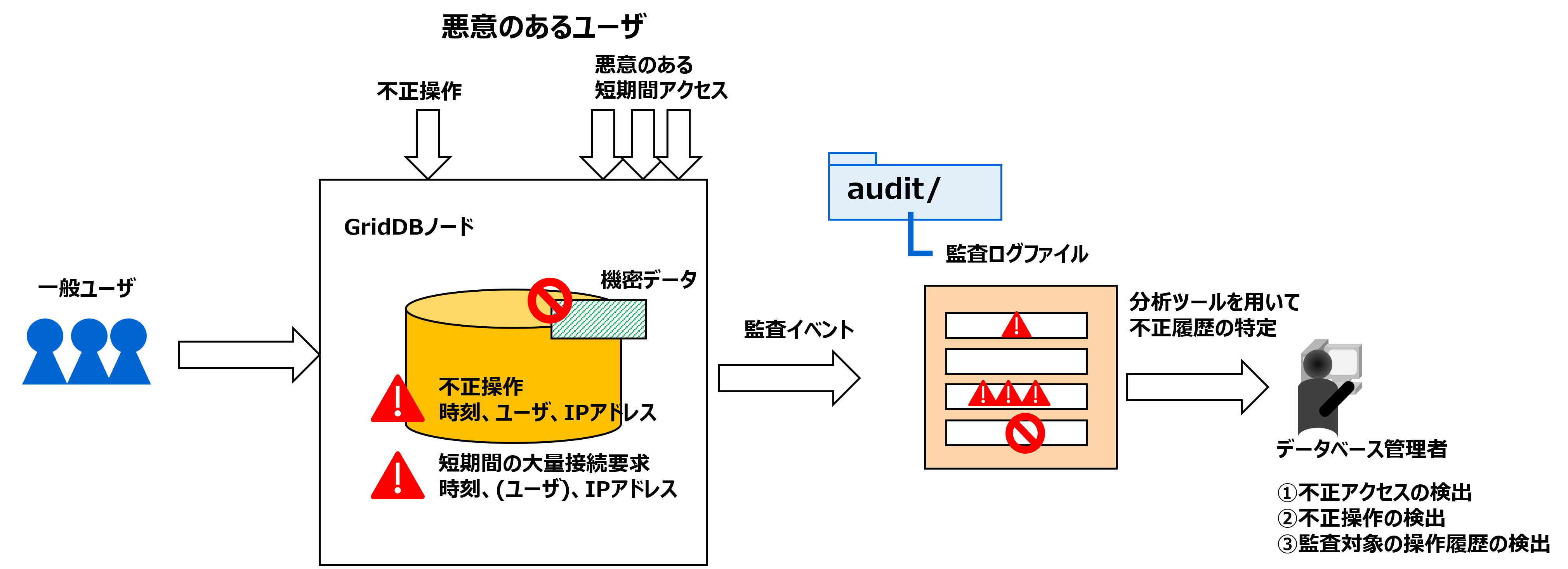
3.11.2 機能概要
監査ログは、データベースに対するアクセス、操作、エラーに対する履歴を記録するログです。具体的には以下の3つのイベントが監査ログとして記録されます。
- アクセスログ
- 接続、切断、ログイン認証の履歴を記録したもの
- 操作ログ
- クライアント要求に対する操作履歴を記録したもの
- エラーログ
- クライアント要求に対する操作で発生したエラー履歴を記録したもの
監査ログはノード定義ファイルで監査ログ機能を有効(auditLogs=true)とした場合に有効となります。この際、監査ログファイルの出力先となるディレクトリパス(auditLogsPath)を指定することが可能で、以下のファイル名で監査ログファイルが生成されます。
gs_audit-%Y%m%d-n.log (nは同一日時における生成順序)
監査ログはイベントログと異なり、ノード定義ファイルで監査ログを有効にしない限り、監査ログファイルおよびディレクトリは生成されません。
監査ログファイルは以下のタイミングで切り替わります。ファイルサイズの閾値はノード定義ファイル(auditMessageLimitSize)で変更可能となります。
- 日付が変わって一番最初にログが書かれるとき
- ノードを再起動したとき
- 1ファイルサイズが既定値(デフォルト10MB)を超えたとき
監査ログの出力形式は以下のように、各監査項目が空白を区切り文字としたCSV形式となります。
(日付時刻) (ホスト名) (スレッド番号) (出力レベル) (カテゴリ) [(エラー・トレース番号):(エラー・トレース番号名)] (ユーザ名) (管理者権限) (データベース名) (アプリケーション名) (接続元IPアドレス:接続元ポート番号) (接続先IPアドレス:接続先ポート番号) (操作クラス) (要求種別) (操作内容) (操作対象) (操作識別子) (操作情報詳細)
以下に監査ログの出力サンプルを示します。なお、以降のサンプルは表示を見やすくするため途中に適宜改行が含まれています。
2023-03-24T17:26:26.359+09:00 TDSL1234 14268 ERROR AUDIT_DDL
[280003:SQL_DDL_TABLE_ALREADY_EXISTS] user1 admin db1 (null)
192.0.2.1:63482 203.0.113.1:20001 SQL CREATE_TABLE
"create table table1(a integer);"
e71c8b74-8752-4726-987d-ebd0e8da8d4:1
"'tableName'=['table1']
Execute SQL failed (reason=CREATE TABLE failed
(reason=Specified create table 'table1' already exists)
on executing statement..."
監査ログ機能を用いる場合は、一般的に監査ログの出力数に比例して性能的なオーバヘッド(ファイル書き込みコスト)が発生します。よって、運用ごとに監査対象となる操作を選定することを検討してください。
監査対象となる操作は、操作内容に基づいて以下の「操作カテゴリ」にカテゴライズされます。出力レベルの設定はイベントログと同様になりますが、監査ログの場合は以下のような意味合いとなります。
INFO : 操作ログ、エラーログを監査ログとして記録します。(※1)
ERROR : エラーログを監査ログとして記録します。
CRITICAL: エラーログも含め、監査ログは記録されません。(※2)
(※1 AUDIT_CONNECTの場合のみアクセスログとなります。) (※2 監査ログとしてCRITICALレベルで出力される項目はありません。)
| 操作カテゴリ | パラメータの意味と制限値 | デフォルト出力レベル |
|---|---|---|
| AUDIT_CONNECT | 接続(接続、切断、認証)に関する監査ログの出力レベル | INFO |
| AUDIT_SQL_READ | SQL(SELECT)に関する監査ログの出力レベル | CRITICAL |
| AUDIT_SQL_WRITE | SQL(DML)に関する監査ログの出力レベル | CRITICAL |
| AUDIT_DDL | SQL(DDL)に関する監査ログの出力レベル | CRITICAL |
| AUDIT_DCL | SQL(DCL)に関する監査ログの出力レベル | CRITICAL |
| AUDIT_NOSQL_READ | NoSQL(参照系)に関する監査ログの出力レベル | CRITICAL |
| AUDIT_NOSQL_WRITE | NoSQL(更新系)に関する監査ログの出力レベル | CRITICAL |
| AUDIT_SYSTEM | 運用コマンド(STAT以外)に関する監査ログの出力レベル | CRITICAL |
| AUDIT_STAT | 運用コマンド(STAT)に関する監査ログの出力レベル | CRITICAL |
デフォルトの出力レベルはアクセスログ(AUDIT_CONNECT)のみINFOでそれ以外はCRITICAL(監査対象外)となっています。よって、起動ファイルで監査ログを有効とした場合は、アクセスログのみ記録されます。運用開始前に監査目的に応じて適切に監査対象とする操作カテゴリを設定する必要があります。
データベース管理者は、監査対象となる操作カテゴリをノード定義ファイルもしくはオンラインで設定することもできます。設定状況はイベントログと同様にgs_logconfコマンドで確認できますがこの場合は永続化されませんので、再起動時に元の操作カテゴリに戻ります。よって、できる限り運用開始前に監査カテゴリを決定しておくことが推奨されます。
ノード起動ファイルで設定する監査ログ関連の設定項目は以下となります。
| 監査カテゴリ | 初期値 | パラメータの意味と制限値 | 変更 |
|---|---|---|---|
| /trace/auditLogs | false | 監査ログを設定する場合はtrueを設定します。 | 起動 |
| /trace/auditLogsPath | "" | 監査ログファイルの配置先ディレクトリ(ディレクトリ名=audit)です。 起動時に該当パスにディレクトリ(audit)が存在しなければ設定に基づき監査用ディレクトリおよび監査ログファイルが生成されます。 auditLogs=true、かつ、この項目未設定の場合はGridDBホームディレクトリに生成されます。 |
起動 |
| /trace/auditFileLimit | 10MB | 同一日時における1つの監査ログファイルのサイズ上限値です。 指定されたサイズを超えると自動的に新たな監査ログファイルが生成され切り替わります。 その際にファイル名の連番部分が+1となります。 |
起動 |
| /trace/auditMessageLimit | 1024 | 1つの監査ログレコードの文字列サイズ上限値です。 指定されたサイズを超えた場合、指定サイズ以降をカットした情報が監査ログとして記録されます。 |
起動 |
3.11.3 監査ログ設計
監査ログを用いた運用手順を以下に示します。
3.11.3.1 監査ログファイルの配置先の検討
監査ログファイルの出力先(auditLogsPath)を以下の観点から決定します。
[容量]
監査ログ機能を有効にした場合、監査対象の操作数に応じてファイルサイズが大きくなりますので、ディスク容量を十分に確保することが必要となります。
監査ログファイルサイズは、基本的には以下で見積もることが可能です。
- (1つの監査ログのメッセージサイズ)×(監査対象となった操作数)
監査ログ保存先のストレージ空き容量を定常監視して、必要に応じて監査ログファイルをアーカイブしたり、監査期限を過ぎた監査ログファイルを削除する、といった運用が必要となります(GridDBサーバ機能として、監査ログファイルを自動的にアーカイブ、削除する機能はありません。)
[ストレージ性能]
監査ログ機能を有効にした場合、監査対象の操作数に応じてファイル書き込みのオーバヘッドが増加します。よって監査ログを用いる場合、監査ログファイルを性能が高いストレージに配置することが推奨されます。
[セキュリティ]
監査ログの保存先となるディレクトリパスは、監査要件と照らし合わせ、セキュリティが担保された場所に設定する必要があります。GridDBはデータベース管理者権限(gsadm)で指定したディレクトリに対して書き込み、読み込み、実行を行いますので、gsadmへのアクセス権限を適切に行ってください。また、監査ログファイルは、所有者がgsadmとなり、他ユーザからの書き込み、読み込みが不可となります。
3.11.3.2 監査対象操作カテゴリの設定
データベース監査を実施する事前準備として、監査対象となる操作カテゴリおよび出力レベルを決定します。出力レベルの指定は監査ログと同様の指定になりますが、監査ログ対象指定から外す場合はCRITICAL指定となる点にご注意ください。
- アクセスログの取得:AUDIT_CONNECT=INFO
- 操作ログの取得:該当操作カテゴリ=INFO
- エラーログの取得:該当操作カテゴリ=ERROR
- エラーログも取得しない:該当操作カテゴリ=CRITICAL
監査対象カテゴリの典型的な設定方針を幾つか示します。このうち、「アクセスログ」は監査上重要項目になりますので、監査ログ機能を有効とした場合、デフォルトでアクセスログが監査対象となります。操作ログ、エラーログに関しては監査案件ごとに必要となる場合にその記述をノード定義ファイルに加えます。
アクセスログを記録したい。
- 監査ログ(auditLogs=true)を有効にするとデフォルトでアクセスログが出力されます。
データベースに対するアクセスログのみを記録し、それ以外はエラーログのみ記録したい。
- AUDIT_CONNECTをINFOに設定し、それ以外をERRORに設定します。
SQL関連の操作ログを記録し、それ以外はエラーログのみ記録したい。
- AUDIT_SQL_READ, AUDIT_SQL_WRITE, AUDIT_DDL, AUDIT_DCLをINFOに設定し、それ以外をERRORに設定します。
更新系の操作ログを記録して、参照系の操作ログは記録しない。ただし、エラーログは全て記録したい。
- AUDIT_SQL_WRITE, AUDIT_NOSQL_WRITEをINFOに設定し、それ以外をERRORに設定します。
- ERRORに設定したカテゴリは操作ログは記録されず、エラーログのみ記録されます。
NoSQL系操作は監査対象から外したい
- AUDIT_NOSQL_READ, AUDIT_NOSQL_WRITEをCRITICALに設定します。この場合、操作ログだけでなくエラーが発生しても監査ログに出力は残りません。
全ての操作を監査対象として記録したい。
- AUDIT_CONNECT, AUDIT_SQL_READ, AUDIT_SQL_WRITE, AUDIT_DDL,AUDIT_DCL,AUDIT_NOSQL_READ, AUDIT_NOSQL_WRITE,AUDIT_STAT,AUDIT_SYSTEMを全てINFOに設定します。
3.11.3.3 監査ログ構成
監査ログを用いた場合のシステム構成を以下に示します。
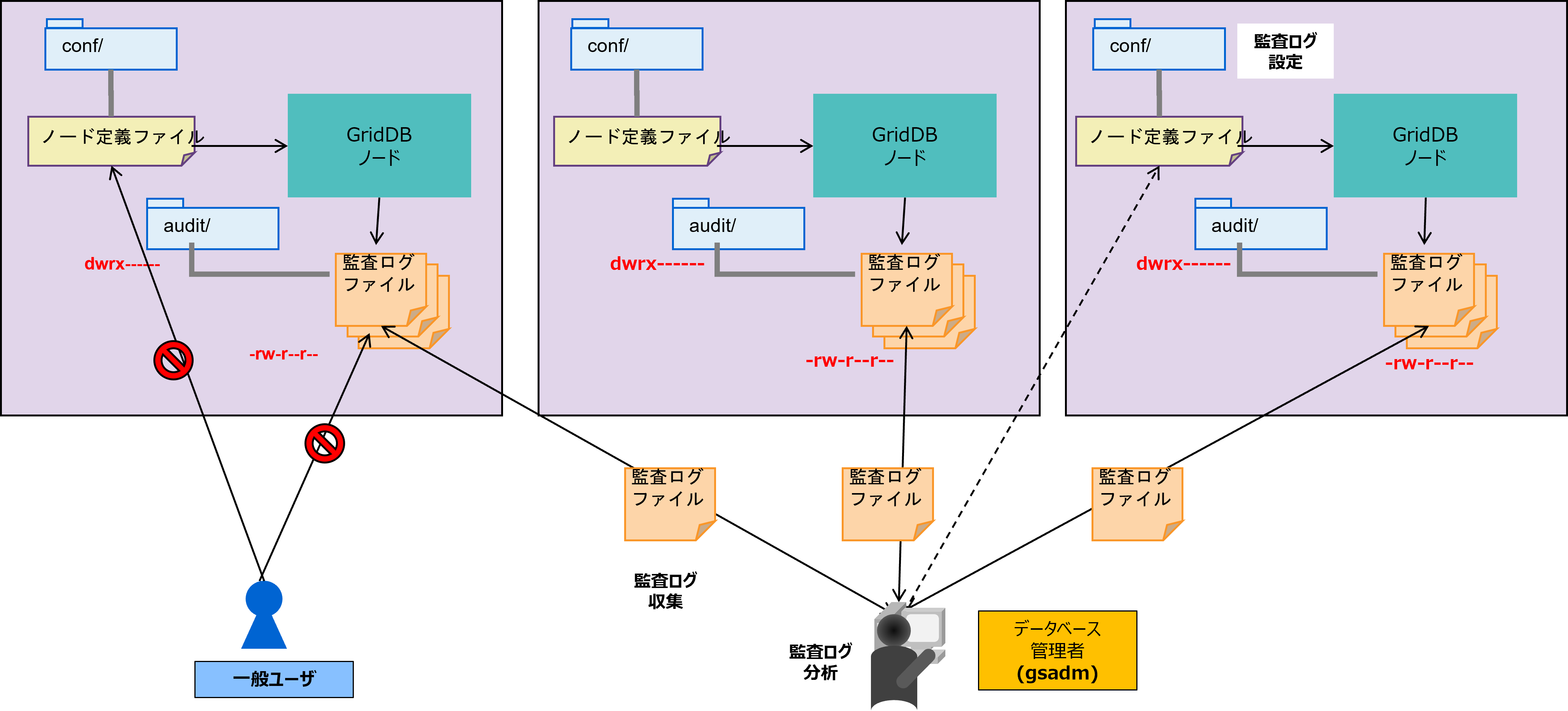
監査ログはクライアントと直接接続があったノードに対して出力されます。つまり、監査ログはノード単位で記録されるので、以下の対応が必要となります。
- 事前に全ノードの監査ログに関する設定項目は全て揃えておきます。
- 監査対象の操作カテゴリをオンライン変更する場合は全てのノードに適用します。また、オンライン変更する場合は永続化されませんので、次に再起動するタイミングでノード起動ファイルを更新します。
- 監査ログ分析を行う場合は、各ノードの監査ログ情報を収集し、横断して分析します。
3.11.3.4 監査ログの分析手順
監査ログの出力項目は、アクセスログ、操作ログ、イベントログともに出力フォーマットが共通となります。監査ログ出力項目の詳細は以下になります。必須項目以外で、対応する項目が無い場合は(null)の文字列が出力されます。
| 監査項目 | 内容 | サンプル | データ型 | 必須項目 |
|---|---|---|---|---|
| 日時 | 形式は:yyyy-mm-ddThh:mm:ss.ms+tz | 2023-03-24T17:26:26.359+09:00 | 時刻型 | 〇 |
| ホスト名 | 呼出し元ホスト名 | tdsl1234 | 文字列型 | 〇 |
| スレッド番号 | システムから取得したスレッドID。 | 2345 | 数値型 | 〇 |
| 出力レベル | INFO/ERROR/CRITICALのいずれか。 | INFO | 文字列型 | 〇 |
| 操作カテゴリ | 監査対象となる操作カテゴリ。 | AUDIT_CONNECT | 文字列型 | 〇 |
| エラー/トレース情報 | [エラー/トレースコード番号:エラー/トレースコード名] | [280003:SQL_DDL_TABLE_ALREADY_EXISTS] | 文字列型 | 〇 |
| ユーザ名 | ログインユーザ名。 | user1 | 文字列型 | × |
| 管理者権限 | ADMIN/USERのいずれか。 | ADMIN | 文字列型 | × |
| データベース名 | 指定なしの場合はPUBLIC、指定した場合はそのデータベース名。 | db1 | 文字列型 | × |
| アプリケーション名 | クライアントで設定した場合のみ。 | app1 | 文字列型 | × |
| 接続元IPアドレス | 接続元(クライアント側)のIPアドレスとポート番号。 IPアドレスはIPv4形式の文字列型、ポート番号は数値型で、":"で分割 |
192.0.2.1:63482 | 文字列型 | × |
| 接続先IPアドレス | 接続先(サーバ側)のIPアドレスとポート番号。 IPアドレスはIPv4形式の文字列型、ポート番号は数値型で、":"で分割 |
203.0.113.1:20001 | 文字列型 | × |
| 操作クラス | カテゴリ "AUDIT_XXX" から、"AUDIT_" を除いた文字列と同じ | CONNECT | 文字列型 | × |
| 要求種別 | SQL/NOSQL/SYSTEMのいずれか | SQL | 文字列型 | × |
| 操作内容 | 要求種別がSQLの場合はSELECT/DML/DDL/DCLのいずれか、NoSQLの場合はAPIに対応するコマンド名、管理コマンドの場合はコマンド名 | SELECT | 文字列型 | × |
| 操作対象 | 要求種別がSQLの場合はSQL名、NoSQLの場合は対象コンテナもしくは索引名、管理コマンドの場合はコマンド名 | SELECT * from table1 | 文字列型 | × |
| 操作識別子 | ステートメント識別子(内部情報)。 32文字から構成されるUUIDを8/4/4/4/12文字単位"-"で分割し、末尾に":"と任意の識別数字を加えたもの |
6a4ccd7a-818a-45e8-88c7-1ebda78d1959:1 | 文字列型 | × |
| 操作情報詳細 | 監査ログの詳細情報。 エラー時にはメッセージ。 必要に応じて以下のキーバリュー形式で情報が付与される。 'キー名' = ['バリュー値1', 'バリュー値2',...] |
"'tableName'=['table1'] Execute SQL failed (reason=CREATE TABLE failed ..." | × |
SQLに対する操作対象のテーブル名は解析内容によっては対象が複数個数になることがあります。これらは、操作情報詳細'tableName'=['テーブル名1', 'テーブル名2'...]の項目が追加されます。
以下に幾つかのサンプルを示します・
(サンプル1) 以下の方針の監査を行います。
| ログ種別 | 方針 |
|---|---|
| アクセスログ | 取得する。 |
| 操作ログ | SQLでの参照系のみ取得する。それ以外は取得しない。 |
| エラーログ | NoSQL系操作は監査対象としない。それ以外は取得する。 |
[監査条件の設定]
ノード定義ファイルにおいて、監査対象のカテゴリを以下のように設定します。操作ログを取得したい場合はINFO, エラーログを取得したい場合はERROR, エラーログも監査対象としない場合はCRITICALを設定することになります。
"auditLogs" : true,
...
"auditConnect" : "LEVEL_INFO",
"auditSqlRead : "LEVEL_INFO",
"auditSqlWrite" : "LEVEL_ERROR",
"auditDdl" : "LEVEL_ERROR",
"auditDcl" : "LEVEL_ERROR",
"auditNosqlRead" : "LEVEL_CRITICAL",
"auditNoslWrite" : "LEVEL_CRITICAL",
"auditSystem" : "LEVEL_ERROR",
"auditStat" : "LEVEL_ERROR"
[ログの確認]
監査対象となる操作を行うクライアント環境は以下の通りとします。
〇ユーザ1
| 項目 | 値 |
|---|---|
| API | JAVA |
| ユーザ名 | user1 |
| データベース名 | public(デフォルト) |
| アプリケーション名 | 指定なし |
| クライアントIPアドレス | 192.0.2.1:43482 |
| 接続先サーバIPアドレス | 203.0.113.1:30001 |
はじめに、JDBCを用いて、db1に対して接続処理(connect)を行います。
Connection con = DriverManager.getConnection(url, user, password);
この場合、監査対象であるAUDIT_CONNECT=INFOに従い、以下の監査ログが出力されます。ユーザ名(user1)、IPアドレス(192.0.2.1:63482)、対象のデータベース(db1)などの情報が記録されていることが分かります。
023-03-27T17:16:13.507+09:00 TDSL1234 1848 INFO AUDIT_CONNECT
[10917:TXN_AUDIT_CALLED]
user1 user db1 app1
192.0.2.1:63482 203.0.113.1:50001
SQL CONNECT
"" 0000-00-00-00-000000:0 ""
次に、存在するテーブルtable1, table2に対する結合処理を行う以下の参照系SQLを実行します。
SELECT * FROM table1 A, table2 B WHERE A.col1 = B.col2
この場合、以下の監査ログ(操作ログ)が記録されます。アクセスログと同様の接続情報に加え、実行したSQLのSQL文字列(SELECT * FROM table1 A, ...)、SQL種別(SELECT), 操作識別子(282d7b10-...)およびアクセス対象となるテーブル名のリスト(table1, table2)が監査ログとして記録されますので、それら操作ログを分析します。
2023-03-24T17:06:53.848+09:00 TDSL1234 16812 INFO AUDIT_SQL_READ [200909:SQL_EXECUTION_INFO]
user1 user db1 app1
192.0.2.1:63482 203.0.113.1:50001
SQL SELECT "SELECT * FROM table1 A, table2 B WHERE A.col1 = B.col2"
282d7b10-f7f0-4dd8-bef-25eb30e5c2f4:5
"'tableName'=['table1','table2']"
監査対象外の監査ログが記録されないことを確認するために、INSERT構文を用いた以下のSQLを発行します。このSQLは更新系になりますが、AUDIT_SQL_WRITE=ERRORにより監査対象ではありませんので、監査ログには記録されません。
次に、エラーログの確認のため、以下のようなテーブル名のカラム名指定が誤ったSQLを実行します。
SELECT notFoundColumn FROM table1
この場合、以下のエラーログが出力されます。
2023-03-24T17:24:23.278+09:00 TDSL1234 25464 ERROR AUDIT_SQL_READ
[240008:SQL_COMPILE_COLUMN_NOT_FOUND]
user1 user db1 app1
192.0.2.1:63482 203.0.113.1:50001 SQL
SELECT "SELECT notFoundColumn FROM table1"
282d7b10-f7f0-4dd8-bef-25eb30e5c2f4:6
"'tableName'=['table1']
Column not found (name=notFoundColumn) on executing statement..."
操作ログの情報に加え、発生したエラーコード(240008:SQL_COMPILE_COLUMN_NOT_FOUND)、エラーメッセージ(Column not found...)などが記録されますので、それらを分析します。
次に、INSERT文でスキーマ不一致となる以下のSQLを実行してエラーを発生させます。
INSERT INTO table1 VALUES(1,2)
この場合、AUDIT_SQL_WRITE=ERRORに従い、操作ログは記録されませんでしたが、エラーログは記録されていることが確認できます。
2023-03-24T17:35:20.883+09:00 TDSL1234 19388 ERROR AUDIT_SQL_WRITE
[240014:SQL_COMPILE_MISMATCH_SCHEMA]
user1 user db1 app1
172.24.52.239:61004 172.24.52.239:20001
SQL INSERT
"INSERT INTO table1 VALUES(1,2)" 1f4472da-30a2-43f8-9167-7728ebc79f91:2
"'tableName'=['table1']
Specified column list count is unmatch with target table, expected=1, actual=2 on executing statement..."
最後に、コネクションをクローズした場合、AUDIT_CONNECT=INFOに従い、以下のアクセスログが記録されます。
2023-03-24T17:46:15.723+09:00 TDSL1234 1848 INFO AUDIT_CONNECT
[10917:TXN_AUDIT_CALLED] user1 user db1 app1
192.0.2.1:63482 203.0.113.1:50001
SQL DISCONNECT "" 0000-00-00-00-000000:0 ""
(サンプル2)
以下の条件で監査を行います。
| ログ種別 | 方針 |
|---|---|
| アクセスログ | 取得する。 |
| 操作ログ | NoSQL操作と監査コマンドのみ取得する。それ以外は取得しない。 |
| エラーログ | SQL系操作は監査対象としない。それ以外は取得する。 |
[監査条件の設定]
ノード定義ファイルにおいて、監査対象のカテゴリを以下のように設定します。
"auditLogs" : true,
...
"auditConnect" : "LEVEL_INFO",
"auditSqlRead : "LEVEL_CRITICAL",
"auditSqlWrite" : "LEVEL_CRITICAL",
"auditDdl" : "LEVEL_CRITICAL",
"auditDcl" : "LEVEL_CRITICAL",
"auditNosqlRead" : "LEVEL_INFO",
"auditNoslWrite" : "LEVEL_INFO",
"auditSystem" : "LEVEL_INFO",
"auditStat" : "LEVEL_INFO"
[ログの確認]
クライアント環境は以下の通りとします。
〇ユーザ1
| 項目 | 値 |
|---|---|
| API | JAVA |
| ユーザ名 | user1 |
| データベース名 | public(デフォルト) |
| アプリケーション名 | 指定なし |
| クライアントIPアドレス | 192.0.2.1:43482 |
| 接続先サーバIPアドレス | 203.0.113.1:30001 |
〇ユーザ2
| 項目 | 値 |
|---|---|
| API | 管理コマンド |
| ユーザ名 | admin |
| データベース名 | なし |
| アプリケーション名 | 指定なし |
| クライアントIPアドレス | 192.0.2.1:23482 |
| 接続先サーバIPアドレス | 203.0.113.1:10040 |
最初に、ユーザ1がJavaAPIを用いて、db1に対して接続処理(connect)を行います。
GridStore store = GridStoreFactory.getInstance().getGridStore(props);
この場合、AUDIT_CONNECT=INFOに従い以下の監査ログが出力されます。ユーザ名(user1)、IPアドレス(192.0.2.1:43482)、対象のデータベース(db1)などの情報が記録されていることが分かります。
023-03-27T17:16:13.507+09:00 TDSL1234 1848 INFO AUDIT_CONNECT
[10917:TXN_AUDIT_CALLED]
user1 user1 public (null)
192.0.2.1:43482 203.0.113.1:30001
NOSQL CONNECT "" 0000-00-00-00-000000:0 ""
次に、存在するコンテナ(col01)に対してロウを登録するためのputを実行します。
col01.put(person);
この場合、以下の監査ログが記録されます。アクセスログと同様の接続に関する情報に加え、実行したNoSQLのコマンド名(PUT_ROW), 対象となるコンテナ名(col01), 操作識別子(14a0b664-...)などが監査ログとして記録されますので、それら操作ログを分析します。
2023-03-27T14:37:19.146+09:00 TDSL1234 21096 INFO AUDIT_NOSQL_WRITE
[10917:TXN_AUDIT_CALLED]
user1 user1 public (null)
192.0.2.1:43482 203.0.113.1:30001
NOSQL PUT_ROW "col01" 14a0b664-6592-4fe-a829-d231afdb267b:4 ""
次に、監査操作の対象外である、INSERT文を用いた以下のSQLを発行します。
INSERT INTO col01 values(1,2,3);
AUDIT_SQL_WRITE=ERRORによりSQLは操作ログの監査対象ではありませんので、監査ログには記録されません。エラーログのみ記録されます。
次に、以下のようなスキーマが不一致となるようなコレクションに対するスキーマ変更操作を行い、NoSQL系のエラーを発生させます。
Collection<String, Person> col02 = store.putCollection("animal", Person.class);
この場合、以下のエラーログが出力されます。
2023-03-27T14:38:59.820+09:00 TDSL1234 28316 ERROR AUDIT_NOSQL_WRITE
[60149:DS_DS_SCHEMA_CHANGE_INVALID]
user1 user public (null)
192.0.2.1:43482 203.0.113.1:30001
NOSQL PUT_CONTAINER ""
b95ab5a6-4212-437e-8b53-bc9087b3bd1:1
"RowKey of new schema does not match RowKey of current schema"
操作ログの情報に加え、発生したエラーコード(60149:DS_DS_SCHEMA_CHANGE_INVALID)、エラーメッセージ(CRowKey of new schema does not...)などが記録されますので、それらエラーログを分析します。
JavaAPIコネクションを切断した場合、AUDIT_CONNECT=INFOに従い、以下のアクセスログが記録されます。
2023-03-27T17:46:15.723+09:00 TDSL1234 1848 INFO AUDIT_CONNECT
[10917:TXN_AUDIT_CALLED]
user1 user public (null)
192.0.2.1:43482 203.0.113.1:30001
NOSQL DISCONNECT "
" 0000-00-00-00-000000:0 ""
最後に管理コマンドの操作ログを確認します。データベース管理者であるユーザ2が、管理コマンドであるgs_leavecluster(ノード切り離しコマンド)を実行した場合、以下のような監査ログが記録されます。管理ユーザ名(admin),ユーザのIPアドレス(192.0.2.1:23482), 接続先サーバIPアドレス(203.0.113.1:10040), 実行コマンド名(GS_LEAVE_CLUSTER)などが記録されます。
2023-03-27T14:51:58.129+09:00 TDSL1234 24712 INFO AUDIT_SYSTEM [50903:SC_WEB_API_CALLED]
admin admin (null) (null)
192.0.2.1:23482 203.0.113.1:10040
SYSTEM GS_LEAVE_CLUSTER "/node/leave force=true" (null) ""
4 構築
本章では、GridDBのインストールや環境設定方法、アンインストールの方法について説明します。
4.1 GridDBのメディア・RPMの構成
GridDBのインストールメディアには、以下のディレクトリ構成でファイルが格納されています。
RHEL/ RHEL,CentOS用RPMパッケージ
Ubuntu/ Ubuntu Server用debパッケージ
Windows/ Windows用C-API, JDBC, ODBC
misc/ データベースファイル移行ツール, サンプルなど
Fixlist.pdf モジュールの修正履歴
Readme.txt Readme
パッケージには以下の種類があります。
| 分類 | パッケージ名 | ファイル名 | 内容 |
|---|---|---|---|
| サーバ | griddb-ee-server | ・griddb-ee-server-X.X.X-linux.x86_64.rpm ・griddb-ee-server_X.X.X_amd64.deb |
ノードモジュールと運用ツールの一部が含まれます。 |
| クライアント (運用ツール) |
griddb-ee-client | ・griddb-ee-client-X.X.X-linux.x86_64.rpm ・griddb-ee-client_X.X.X_amd64.deb |
さまざまな運用ツールが含まれます。 |
| Web UI | griddb-ee-webui | ・griddb-ee-webui-X.X.X-linux.x86_64.rpm ・griddb-ee-webui_X.X.X_amd64.deb |
統合運用管理GUI(gs_admin)が含まれます。 |
| Javaライブラリ | griddb-ee-java-lib | ・griddb-ee-java-lib-X.X.X-linux.x86_64.rpm ・griddb-ee-java-lib_X.X.X_amd64.deb |
Javaのライブラリ、JDBCドライバが含まれます。 |
| Cライブラリ | griddb-ee-c-lib | ・griddb-ee-c-lib-X.X.X-linux.x86_64.rpm ・griddb-ee-c-lib_X.X.X_amd64.deb |
Cのヘッダファイルとライブラリが含まれます。 |
| Web API | griddb-ee-webapi | ・griddb-ee-webapi-X.X.X-linux.x86_64.rpm ・griddb-ee-webapi_X.X.X_amd64.deb |
Web APIアプリケーションが含まれます。 |
| Pythonライブラリ | griddb-ee-python-lib | ・griddb-ee-python-lib-X.X.X-linux.x86_64.rpm ・griddb-ee-python-lib_X.X.X_amd64.deb |
Pythonライブラリが含まれます。 |
| Node.jsライブラリ | griddb-ee-nodejs-lib | ・griddb-ee-nodejs-lib-X.X.X-linux.x86_64.rpm ・griddb-ee-nodejs-lib_X.X.X_amd64.deb |
Node.jsライブラリが含まれます。 |
| Goライブラリ | griddb-ee-go-lib | ・griddb-ee-go-lib-X.X.X-linux.x86_64.rpm ・griddb-ee-go-lib_X.X.X_amd64.deb |
Goライブラリが含まれます。 |
※: X.X.XはGridDBのバージョン
4.2 インストール
4.2.1 インストール前の環境確認
GridDBのハードウェア要件・ソフトウェア要件を満たしていることを確認します。要件については「リリースノート」をご参照ください。
ハードウェア要件の確認
物理メモリのサイズ、および、ディスクのサイズが、ハードウェア要件を満たしていることを確認します。
物理メモリサイズの確認方法
$ grep MemTotal /proc/meminfoディスク容量の確認方法
$ df -h
ソフトウェア要件の確認
オペレーティングシステムの種類やバージョンが要件を満たしていることを確認します。
RHEL、CentOSの確認方法
$ cat /etc/redhat-releaseUbuntu Serverの確認方法
$ cat /etc/lsb-release
Python 3.6以降がインストール済みであることを確認します。
- Pythonバージョンの確認方法
$ python3 --version[注意]
- Pythonが未インストールの場合、パッケージのインストールに失敗します。
4.2.2 ノードの時刻同期
クラスタを構成するノードにおいては、OSの時刻に差がないことが前提です。ノード間でOSの時刻に乖離がある状態で運用することは推奨されません。GridDBではノード間での時刻合わせは行っていません。
各ノードのOSの時刻が乖離していると、以下のような問題が発生する可能性があります。
- SQLやTQLでノードの現時刻を用いるNOW()関数が、実行するノードによって時刻の差が出る
- サーバの現時刻を付与して時系列コンテナにロウを登録する操作(TimeSeries#append)を実行する場合、別のノード上にあるコンテナにほぼ同時に登録要求したにも関わらず、それぞれのロウに付与される時刻に乖離が発生する
- 各ノードのトレースファイルに記録される時刻がノード間で異なり、障害発生時のトレース分析に支障が出る
- レプリカのオーナノードとバックアップノードで期限解放のタイミングが異なる(バックアップノードの時刻がオーナノードの時刻より進んでいると、オーナではまだ期限解放されていないデータがバックアップで先に解放されてしまう)
複数ノードのクラスタ構成の場合は、NTPを使用した時刻同期を推奨します。NTPではslewモードを使用してください。
[注意]
- クラスタ稼働後に、OSの時刻を手動で変更したり古い時刻に巻き戻したりすると、データの不整合やエラーが発生する可能性がありますので行わないでください。
4.2.3 インストールするパッケージの選択
実行するモジュールやマシンの用途によって、インストールが必須なパッケージが異なります。
| 用途 | インストール必須のパッケージ |
|---|---|
| GridDBノードを実行する場合 | サーバ :griddb-ee-server クライアント(運用ツール) :griddb-ee-client Javaライブラリ :griddb-ee-java-lib |
| 運用ツールを実行する場合 | クライアント(運用ツール) :griddb-ee-client Javaライブラリ :griddb-ee-java-lib |
| アプリケーションを開発する場合 | 開発するアプリケーションのプログラミング言語に対応するライブラリ |
[メモ]
- 「インストール必須のパッケージ」以外のパッケージを一緒にインストールしても問題ありません。
- 全パッケージをひとつのマシンにインストールしても問題ありません。
例えば、以下のマシン構成を構築する場合、それぞれインストールするパッケージは以下の通りです。
| マシン | 利用用途 | インストールするパッケージ |
|---|---|---|
| A. GridDBノードを稼働するサーバマシン | GridDBノードを稼働します。運用ツールも実行します。 | griddb-ee-server griddb-ee-client griddb-ee-java-lib |
| B. リモートで運用ツールを実行するマシン | リモートからGridDBノードやクラスタに対して運用ツールを実行します。 | griddb-ee-client griddb-ee-java-lib |
| C. アプリケーション開発マシン | Cのアプリケーションを開発します。 | griddb-ee-c-lib |
[メモ]
- 上記の例ではマシンを別にしていますが、ひとつのマシンをすべての用途に使うことも可能です。
4.2.4 インストールの手順
インストールするパッケージに応じて、インストールの手順は以下のようになります。
| 実行No. | 実行内容 | 実行が必要な場合 |
|---|---|---|
| 1 | パッケージのインストール | 共通 |
| 2 | OSユーザの設定 | サーバパッケージ(griddb-ee-server) または クライアントパッケージ(griddb-ee-client)をインストールしたマシンの場合 |
| 3 | ネットワークの環境設定 | サーバパッケージ(griddb-ee-server)をインストールしたマシンの場合 |
| 4 | ノードの環境設定 | サーバパッケージ(griddb-ee-server)をインストールしたマシンの場合 |
| 5 | 運用ツールの環境設定 | クライアントパッケージ(griddb-ee-client)をインストールしたマシンの場合 |
| 6 | ライブラリの環境設定 | ライブラリパッケージをインストールしたマシンの場合 |
例えば、次のような用途別のマシンの場合はそれぞれ以下のインストール手順になります。
4.2.5 パッケージのインストール
GridDBを利用するマシンに対して、必要なパッケージをインストールします。
[CentOS実行例]
$ cd <CD-ROMまたはDVD-ROMのマウントパス>/RHEL/rpm
$ sudo rpm -ivh griddb-ee-server-X.X.X-linux.x86_64.rpm
準備中... ########################################### [100%]
User gsadm and group gridstore have been registered.
GridDB uses new user and group.
1:griddb-ee-server ########################################### [100%]
$
$ sudo rpm -ivh griddb-ee-client-X.X.X-linux.x86_64.rpm
準備中... ########################################### [100%]
User and group has already been registered correctly.
GridDB uses existing user and group.
1:griddb-ee-client ########################################### [100%]
$
$ sudo rpm -ivh griddb-ee-java-lib-X.X.X-linux.x86_64.rpm
準備中... ########################################### [100%]
1:griddb-ee-java-lib ########################################### [100%]
$
$ sudo rpm -ivh griddb-ee-c-lib-X.X.X-linux.x86_64.rpm
準備中... ########################################### [100%]
1:griddb-ee-c-lib ########################################### [100%]
$
:
:
:
[メモ]
- Ubuntu Serverでは、dpkgでパッケージをインストールします。
$ sudo dpkg -i griddb-ee-server_X.X.X_amd64.deb
[注意]
- Pythonライブラリ、Node.jsライブラリ、Goライブラリのパッケージをインストールするときには、必ず先にCライブラリのパッケージをインストールしてください。
- Web APIのパッケージをインストールするときには、必ずJavaライブラリのパッケージを併せてインストールしてください。
サーバパッケージ(griddb-ee-server)、またはクライアントパッケージ(griddb-ee-client)をインストールすると、以下の設定を自動的に行います。
GridDBユーザとグループの作成
GridDBノードを実行するOSユーザgsadm、グループgridstoreを作成します。
ユーザ 所属グループ ホームディレクトリ gsadm gridstore /var/lib/gridstore ユーザgsadmの.bash_profileファイルには、以下の環境変数を定義します。
環境変数 値 意味 GS_HOME /var/lib/gridstore GridDBホームディレクトリ GS_LOG /var/lib/gridstore/log ノードのイベントログファイルの出力ディレクトリ 同名のユーザ・グループが存在する場合は、変更は行いません。
GridDBホームディレクトリの作成
- ユーザgsadmのホームディレクトリとして、/var/lib/gridstoreを作成します。
サービスの登録(サーバパッケージのみ)
- GridDBノードをOSのサービスに登録します。
- サービス名はgridstoreです。サービスは、OSのランレベル3,4,5で自動起動するように設定します。
4.2.6 OSユーザの設定
サーバパッケージ(griddb-ee-server)、またはクライアントパッケージ(griddb-ee-client)をインストールしたマシンには、本設定を行う必要があります。
サーバパッケージまたはクライアントパッケージをインストールすると、OSユーザgsadmが作成されます。 gsadmにはパスワードが設定されていないので、パスワードを設定してください。
[実行例]
$ sudo passwd gsadm
次に、利用可能なプロセス数とオープン可能なファイル数の上限値を変更し、リソースを多く使えるようにしてください。/etc/security/limits.confに設定してください。
[limits.confの設定例]
gsadm soft nproc 16384
gsadm hard nproc 16384
gsadm soft nofile 65536
gsadm hard nofile 65536
gsadmで再ログインすると、設定が反映されます。ulimit -aで設定内容をご確認ください。
4.2.7 ネットワークの環境設定
サーバパッケージ(griddb-ee-server)をインストールしたマシンには、本設定を行う必要があります。
GridDBノードを稼動するためには、ホスト名とIPアドレスが対応付けられている必要があります。
まず、ホスト名とIPアドレスの対応付けを確認します。ホストとIPアドレスの設定を確認する「hostname -i」コマンドを実行してください。以下のようにマシンのIPアドレスが表示される場合は設定済みですので、本節のネットワーク設定の作業は不要です。
- [実行例]
$ hostname -i 192.168.11.10
以下のようなメッセージやループバックアドレス127.0.0.1が表示される場合は、設定が行われていません。以下の1から3の手順を実施してください。
- [実行例]
または$ hostname -i hostname: 名前に対応するアドレスがありません$ hostname -i 127.0.0.1
ネットワークの設定手順
- OSで設定されているホスト名とIPアドレスを確認する
ホスト名を確認します
[実行例]
$ hostname GS_HOSTIPアドレスを確認します
[実行例]
$ ip route | grep eth0 | cut -f 12 -d " " | tr -d "\n" 192.168.11.10
- ホスト名とIPアドレスの対応付けを設定する
1で確認したホスト名とIPアドレスを、rootユーザで/etc/hostsファイルに追加します。
[ファイルの記述例]
192.168.11.10 GS_HOST
- 設定されたことを確認する
ホストとIPアドレスの設定を確認する「hostname -i」コマンドを実行してください。2で追加したIPアドレスが表示されることを確認してください。
[実行例]
$ hostname -i 192.168.11.10
4.2.8 ノードの環境設定
ノードを稼働するマシンには、本節の設定を行う必要があります。それ以外のマシンの場合は、設定は不要です。
定義ファイルの設定を行います。ノードを稼働するマシンの1台で環境設定した後、定義ファイルを他のマシンに配布します。
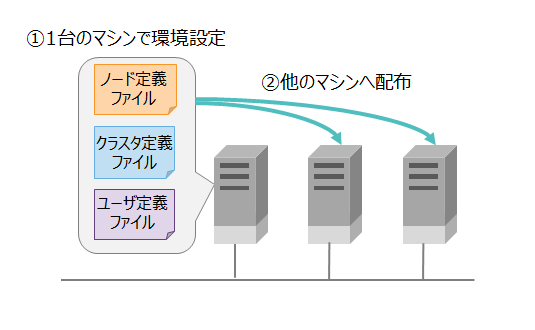
4.2.8.1 パラメータ設定
ノードの定義ファイルには、ノード定義ファイル"gs_node.json"とクラスタ定義ファイル"gs_cluster.json"の2種類があります。
クラスタ名
- クラスタ名の設定は必須です。
その他のパラメータ
- 物理設計の内容に応じて、変更します。
4.2.8.2 管理ユーザの設定
管理ユーザは、運用コマンドの実行や、管理者権限のみ許可されている操作を実行する際に用います。
インストールによって、次の管理ユーザがデフォルトで作成されます。
| 管理ユーザ | パスワード |
|---|---|
| admin | admin |
| system | manager |
セキュリティ上の安全のため、デフォルトの管理ユーザのパスワードを変更してください。管理ユーザのパスワードの変更は、gs_passwdコマンドを使用します。
[実行例]
# su - gsadm
$ gs_passwd admin
Password:(パスワードを入力します)
Retype password:(パスワードを再入力します)
新規に管理ユーザを作成する場合は、gs_adduserを使用します。管理ユーザ名は"gs#"で始まる必要があります。gs#以降は1文字以上のASCII英数字ならびにアンダースコア「_」を使用可能です。文字数の上限は64文字です。
[実行例]
# su - gsadm
$ gs_adduser gs#newuser
Password:(パスワードを入力します)
Retype password:(パスワードを再入力します)
管理ユーザの情報は、ユーザ定義ファイル(/var/lib/gridstore/conf/password)に保存されます。
[メモ]
- ユーザ定義ファイルは、クラスタを構成する全ノードで同じ内容でなければなりません。ひとつのノード上で管理ユーザの追加/削除やパスワードの変更を行った場合は、他のノードにも反映する必要があります。
4.2.8.3 サービスの設定
サービスによってノードは自動起動します。
起動と同時にクラスタ構成も行う場合は、サービスの設定が必要になります。詳細は『GridDB 運用ツールリファレンス』(GridDB_OperationToolsReference.html)を参照ください。
4.2.8.4 定義ファイルの配布
ノードを稼働するマシンの1台で環境設定した後、定義ファイルを他のマシンに配布します。
4.2.9 運用ツールの環境設定
利用する運用ツールの環境設定を行います。各ツールの設定方法の詳細は、『GridDB 運用ツールリファレンス』(GridDB_OperationToolsReference.html)を参照ください。
4.2.10 ライブラリの環境設定
4.2.10.1 Pythonライブラリ
Pythonライブラリを利用するには、下記コマンドにより、Pythonパッケージ(griddb_python)をインストールします。gsadmユーザで実行します。
$ pip install /usr/griddb/lib/python
- pipをあらかじめインストールしておく必要があります。
4.2.10.2 Node.jsライブラリ
Node.jsライブラリを利用するには、下記のようにライブラリを各種パスに含める必要があります。
$ export LIBRARY_PATH=${LIBRARY_PATH}:/usr/griddb/lib
$ export NODE_PATH=/usr/griddb/lib/nodejs
$ export LD_LIBRARY_PATH=${LD_LIBRARY_PATH}:/usr/griddb/lib/nodejs
- glibc 2.14以上をあらかじめインストールしておく必要があります。
4.2.10.3 Goライブラリ
Goライブラリを利用するには、下記のようにライブラリを各種パスに含め、ビルドする必要があります。
$ export LIBRARY_PATH=${LIBRARY_PATH}:/usr/griddb/lib
$ export GOPATH=$GOPATH:/usr/griddb/lib/go
$ export LD_LIBRARY_PATH=${LD_LIBRARY_PATH}:/usr/griddb/lib/go
$ go install griddb/go_client
- gcc, gcc-c++をあらかじめインストールしておく必要があります。
4.2.10.4 Windows上でアプリケーション開発を行う場合
4.2.10.4.1 JDBCを利用したアプリケーション開発
Windows上でGridDBにアクセスするアプリケーションやBIツールなどと連携した開発をJava言語のライブラリを用いて行うには、JDBCドライバを用います。
GridDBのインストールメディアにJDBCドライバのファイルが格納されています。インストールメディアの\Windows\JDBCフォルダ下のjarファイルを、アプリケーションの参照するフォルダにコピーしてご利用ください。
4.2.10.4.2 ODBCを利用したアプリケーション開発
Windows上でGridDBにアクセスするアプリケーションやBIツールなどと連携した開発をC言語のライブラリを用いて行うには、ODBCドライバを用います。『GridDB ODBCドライバ説明書』(GridDB_ODBC_Driver_UserGuide.html)を参照してインストール・環境設定してください。
4.3 アンインストール
GridDBが不要となった場合には、インストールされているパッケージをアンインストールします。以下の手順でアンインストールを実行してください。
- インストールされているパッケージを確認する
- アンインストールする
[CentOS実行例]
// インストールされているパッケージを確認する
$ sudo rpm -qa | grep griddb
griddb-ee-server-X.X.X-linux.x86_64
griddb-ee-client-X.X.X-linux.x86_64
griddb-ee-java-lib-X.X.X-linux.x86_64
griddb-ee-c-lib-X.X.X-linux.x86_64
// アンインストールする
$ sudo rpm -e griddb-ee-server
$ sudo rpm -e griddb-ee-client
$ sudo rpm -e griddb-ee-java-lib
$ sudo rpm -e griddb-ee-c-lib
[CentOS実行例]
- Ubuntu Serverでは、dpkgでパッケージをアンインストールします。
$ sudo dpkg -r griddb-ee-server
[注意]
定義ファイルやデータファイルなど、GridDBホームディレクトリ下のファイルはアンインストールされません。(Ubuntu Serverの場合、ディレクトリが削除できない等の警告が出力される場合がありますが問題ありません。)不要な場合は手動で削除してください。
5 運用
5.1 障害発生時の対応
GridDBを用いたシステムの構築時やシステムの使用時に問題が発生した場合は、どのような問題がどのような状況で発生したかを、実行した動作やエラーコードなどから確認します。状況確認後、対策を検討/実行します。
5.1.1 ノードの場合の対応
ノードのイベントログファイルには、ノード内部で発生した例外などのイベントに関するメッセージやシステム稼働情報を記録します。
ノードの動作に問題がある場合には、ノードのイベントログを参照して、エラーや警告のメッセージが出力されていないか確認してください。クラスタは複数のノードで動作しているので、すべてのノードのイベントログでメッセージの有無を確認する必要があります。
ノードのイベントログを確認する方法
ノードを稼動しているマシンにログインして、イベントログファイルを直接確認する
コマンドgs_logsを利用して、リモートでノードのイベントログを確認する(ノード稼動中のみ)
- 例) ノード(172.0.10.1)に対して、エラーのイベントログを確認する
$ gs_logs -u admin/admin -s 172.0.10.1 ERROR 2017-11-17T19:34:46.895+0900 HOSTNAME 10933 ERROR SQL_SERVICE [10010:TXN_PARTITION_STATE_UNMATCH] (required={ON}, actual=STOP) <VVZk3btebewYF・・・
- 例) ノード(172.0.10.1)に対して、エラーのイベントログを確認する
イベントログの出力形式
1行にひとつのイベントの情報を出力します。
(日付時刻) (ホスト名) (スレッド番号) (ログレベル) (カテゴリ) [(エラーコード)] (メッセージ) <(base64詳細情報: サポートサービスにて問題点分析用の詳細情報)>例
2019-03-20T04:01:50.423+0900 RHEL73-1 13057 INFO CLUSTER_OPERATION [40906:CS_NORMAL_OPERATION] Recovery checkpoint is completed, start all services
対応方法
- エラーが発生していた場合は「エラーコード」を『GridDB エラーコード』(GridDB_ErrorCodes.html)で参照して、原因や対応方法を確認します。
イベントログファイルの出力
出力先ディレクトリ log ファイル名 gridstore-%Y%m%d-n.log ファイルの切替 ・ノードを起動した時
・日付が変わって初めてログを出力する時
・ファイルのサイズが1MBを超えた時ファイルの上限数 30
(30ファイルを超えると古いファイルから削除します)出力先ディレクトリとファイルの上限数は、ノード定義ファイル(gs_node.json)で設定変更できます。
パラメータ 初期値 内容 起動後の変更 /system/eventLogPath log イベントログファイルの出力先ディレクトリ 可(ノード再起動) /trace/fileCount 30 イベントログファイルの上限数 可(ノード再起動)
5.1.2 アプリケーションの場合の対応
クライアントAPI(NoSQL/NewSQLインタフェース)を利用したアプリケーションの実行でエラーが発生した場合は、クライアントAPIが出力するエラーコードとエラーメッセージを確認します。
クライアントAPIごとに、エラーコードやエラーメッセージの取得方法は異なります。各リファレンスをご参照ください。
エラーコードの番号を『GridDB エラーコード』(GridDB_ErrorCodes.html)で参照してエラーの原因を確認し、対策を実施してください。
エラーの原因がアプリケーションではなくノード側の場合は、エラーが発生した時刻のノードのイベントログを確認することで、エラー発生時のノードの状況を確認します。
例) Java APIの場合
GSException#getErrorMessage()で、以下のエラー情報を取得できます。
[エラーコード:エラー記号] エラーメッセージ (補足情報)不正なコンテナ名を指定した場合
[145007:JC_ILLEGAL_SYMBOL_CHARACTER] Illegal character found (character="#", containerName="#Sample", index=0)
5.1.3 運用ツールの場合の対応
運用ツールでエラーが発生した場合は、運用ツールのログファイルを参照して、発生したエラーの内容を確認します。
主な運用ツールのログファイルの出力先は以下の通りです。
| 運用ツール | 出力先 | 出力先の指定方法 |
|---|---|---|
| 運用コマンド(gs_joinclusterなど) | /var/lib/gridstore/log | gsadmユーザの環境変数GS_LOG |
| 統合運用管理GUI(gs_admin) | /var/lib/gridstore/admin/log | ログ設定ファイル(WASのディレクトリ/webapps/gs_admin/WEB-INF/classes/logback.xml) |
| シェルコマンドgs_sh | /var/lib/gridstore/log | ログ設定ファイル(/usr/griddb/prop/gs_sh_logback.xml) パラメータlogPath |
| エクスポート/インポートツール | /var/lib/gridstore/log | プロパティファイル(/var/lib/gridstore/expimp/conf/gs_expimp.properties) パラメータlogPath |
例) gs_startnodeコマンドのログファイル ファイル名:gs_startnode.log
2014-10-20 15:25:16,876 [25444] [INFO] <module>(56) /usr/bin/gs_startnode start.
2014-10-20 15:25:17,889 [25444] [INFO] <module>(156) wait for starting node. (node=127.0.0.1:10040 waitTime=0)
2014-10-20 15:25:18,905 [25444] [INFO] <module>(192) /usr/bin/gs_startnode end.
[メモ]
- 運用ツールの情報と併せてサーバのイベントログ情報も確認することをお勧めします。
5.2 構成管理
5.2.1 ノードの増設
5.2.1.1 設計のポイント
システム初期稼働時は低コストの最小台数でスタートし、データが増加してリソースが不足した時はノードを増設してスケールアウトすることができます。
システムのデータ容量の増加を見積もり、ノード増設のタイミングを計画します。
システム稼働中に以下のようなリソース不足の状態になった場合には、スケールアウトを検討してください。
メモリ容量の不足
- スワップ処理の回数が増加した場合
ディスク容量の不足
- ディスク容量-ファイルサイズが少なくなった場合
5.2.1.2 増設の手順
ノードの増設は、クラスタが停止できる場合には停止して行うことを推奨します。稼働中にオンラインで増設することもできます。
- 新マシンにGridDBの環境を構築する
- 増設する新マシンに、現クラスタと同じバージョンのGridDBをインストールします。
- 現クラスタのノードから、次の3つのファイルをコピーします。
- ノード定義ファイル(conf/gs_node.json)
- クラスタ定義ファイル(conf/gs_cluster.json)
- ユーザ定義ファイル(conf/password)
- アプリケーションや運用ツールの設定、クラスタ構成のスクリプトを修正する
アプリケーション(クラスタ構成方式が、固定リスト方式、または、プロバイダ方式の場合)
- 増設するノードのIPアドレスを、アドレス一覧に追加する。
ノードをクラスタに参加させるコマンドでは、ノードの構成台数を指定します。増設する場合には、この数を変更しておく必要があります。
- ユーザ作成のスクリプトで、運用コマンドgs_joinclusterを使用しているもの
- シェルコマンドgs_shの設定
- setclusterコマンド
- サービス
- 起動設定ファイル/etc/sysconfig/gridstore/gridstore.confのMIN_NODE_NUMの数を変更する
- 統合運用管理GUI(gs_admin)
- リポジトリ画面でノード構成を変更する
- ノードを増設する
クラスタ停止して行う場合
- クラスタを停止します。
- 新マシンも含めて、ノードの参加を実行します。
クラスタ稼働中に行う場合
- クラスタの状態がSTABLEであることを確認します。
- ノード増設コマンドgs_appendclusterを実行します。
5.2.2 パラメータの変更
ノード定義ファイル(gs_node.json)やクラスタ定義ファイル(gs_cluster.json)でノードやクラスタの動作を設定します。ノードを起動した後やクラスタ稼働中にパラメータを変更できるかどうかは次の3つのパターンがあります。
| 変更可否 | 内容 |
|---|---|
| 変更不可 | ノードを一度起動した後は、設定値を変更することはできません。変更する場合は、データベースを初期化する必要があります。 |
| 変更可(再起動) | 定義ファイルの設定値を変更し、ノードを再起動すると設定値が反映されます。 |
| 変更可(オンライン) | ノード・クラスタ稼働中にオンラインでパラメータを変更できます。変更にはコマンドgs_paramconfを用います。ただし、オンラインで変更した内容は永続化されないので、定義ファイルの内容を手動で書き換える必要があります。書き換えない場合は、再起動によって元の設定値に戻ります。 |
オンラインのパラメータ変更手順
- パラメータ変更コマンドgs_paramconfで変更を実施する
- [実行例]
$ gs_paramconf -u admin/admin --set storeMemoryLimit 2048MB
- パラメータが変更されたことを確認する
- [実行例]
$ gs_paramconf -u admin/admin --show storeMemoryLimit "2048MB"
- 変更したパラメータを定義ファイルに手動で書き換える。
[メモ]
- オンラインでパラメータの変更を行った場合は、必ず定義ファイルの内容も手動で書き換えてください。書き換えない場合は、ノードを再起動すると元の設定値に戻ります。
5.3 データ移行
5.3.1 新しいマシンへのデータ移行の方法
マシンのリプレースなどのために、現在稼動しているクラスタと同じ設定の新しいクラスタを構築するための方法を説明します。
このようなケースでは、ノードを停止してデータベースファイルを物理的にコピーするだけでデータ移行できます。
- 新マシンにGridDBをインストールします。
- 現在稼動しているノードと同じバージョン・エディションのRPMを用いてインストールします。
- 定義ファイルをコピーします。
- 現在稼動しているノードから、クラスタ定義ファイル、ノード定義ファイル、ユーザ定義ファイルの3つのファイルをコピーして配置します。
- 現在稼動しているクラスタを停止します。
- クラスタ停止コマンドgs_stopclusterを用いて、クラスタを停止します。
- ノード停止コマンドgs_stopnodeを用いて、各ノードを停止します。
- データベースファイルをコピーします。
- ノード定義ファイルの/dataStore/dataPath,および/dataStore/transactionLogPathに記載されているディレクトリ下のデータを、すべて新マシンにコピーします。
- 新マシンでクラスタを稼動します。
5.3.2 DB互換性が無い場合のデータ移行の方法
GridDBのバージョンアップなどでDB互換性が無い場合には、データをエクスポート・インポートしてデータ移行する必要があります。
エクスポート・インポートは、データ容量やディスクI/Oの性能によって時間がかかる場合があります。
- クラスタ上の全データをエクスポートします。
- gs_export -u admin/admin --all -acl
GridDBをバージョンアップインストールします。
全データをインポートします。
- gs_import -u admin/admin --all --acl
[メモ]
- GridDB V4から、V5へバージョンアップする場合、データベースファイル変換ツールを利用することができます。詳細は、『GridDB 運用ツールリファレンス』(GridDB_OperationToolsReference.html)をご参照ください。