GridData Lake Server管理者ガイド¶
本マニュアルは、GridData Lake Serverのインストール、設定及び運用方法について説明したものです。 製品のご使用前に必ずお読みください。
本書に記載されている外部URLについては2017年10月時点のものとなります。
GridData Lake Serverのソフトウェア構成は以下の通りです。
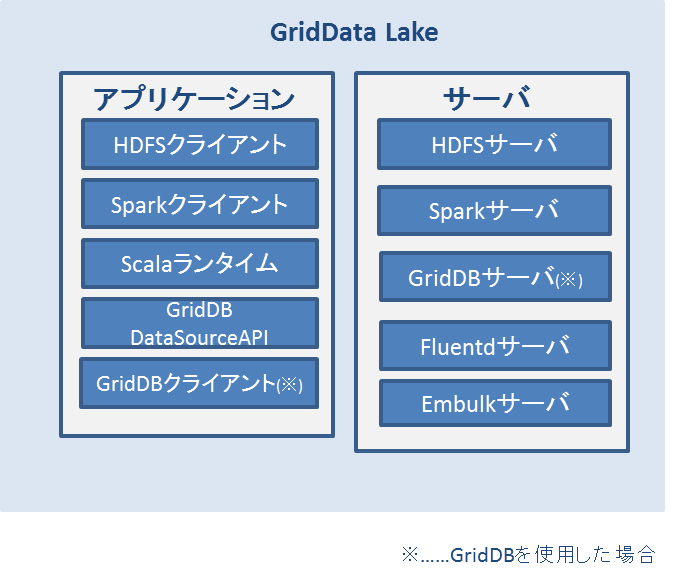
図のように、GridData Lake Serverは複数のアプリケーションおよびサーバで構成されています。 各アプリケーションとサーバの概要は以下の通りです。
| 名称 | 概要 |
|---|---|
| HDFSクライアント | HDFSのクライアントアプリケーション |
| Sparkクライアント | Sparkのクライアントアプリケーション |
| Scalaランタイム | Scalaの実行環境 |
| GridDB DataSourceAPI | Scala上でGridDBにアクセスするためのAPI |
| GridDBクライアント | GridDBのクライアントアプリケーション |
| HDFSサーバ | HDFSのサーバアプリケーション |
| Sparkサーバ | Sparkのサーバアプリケーション |
| GridDBサーバ | GridDBのサーバアプリケーション |
| Fluentdサーバ | Fluentdのデータを受け取るサーバアプリケーション |
| Embulkサーバ | Embulkのデータを受け取るサーバアプリケーション |
データの収集にはEmbulkサーバおよびSparkサーバを、蓄積にはApache HadoopによるHDFS、またはGridDBを使用します。 データの分析にはApache Spark(Spark)を使用し、このとき必要に応じScalaのランタイム環境やGridDB DataSourceAPIを使用します。
GridData Lake Serverは、Apache HadoopおよびSparkをベースとし、 データの収集や蓄積を行う際の利便性の向上のため、各種アプリケーションを追加と設定の追加・修正を行ったものです。