GridDB Cloud クイックスタートガイド
Revision: 2.5.0-13372-ad2ab4f6
1 はじめに
本書では、初めてGridDB Cloudをお使いの方に製品の概要と簡単な使い方を説明します。具体的にはサービスの払い出し後に管理コンソール(以下、運用管理GUI)へログインするところから、GridDBへのデータ登録・確認を行う一連の手順を説明します。
まず、GridDB Cloudには、下記の2つのプランがあります。
- 専用環境プラン:「標準構成(3ノード)Standard」、「シングルノード構成(1ノード)Professional」 などの有料プラン
- 共用環境プラン:共用環境無料プラン、共用環境有料プラン
GridDB Cloudには大きく2通りの接続方法があります。専用環境プランではクライアントAPIとWeb APIの両方の接続方法が利用可能ですが、共用環境プランではWeb APIでのみ接続が可能です。
- クライアントAPI(専用環境プランのみ)
- クライアントAPIを使うアプリケーションは、Azureのプライベートネットワーク「VNet」に配置する必要があります。VNetを未作成の場合は事前に用意をお願いします。
- Azureのアカウントを保持していないなど、VNet環境を利用できない場合はWeb APIを利用してください。
- Web API(専用環境プラン/共用環境プラン共通)
1.1 本書の構成
各章の内容は次のとおりです。一部の章は、専用環境プランユーザ向けの説明となっています。
はじめに(専用環境プラン/共用環境プラン共通)
GridDB Cloudについて説明します。稼働状態の確認(専用環境プラン/共用環境プラン共通)
運用管理GUIへログインし、GridDBが正常稼働していることを確認する方法について説明します。VNetの接続設定(専用環境プランのみ)
アプリケーションが配置されるVNetと、GridDBが配置されるVNetを接続する方法について説明します。サンプルプログラムの実行(専用環境プランのみ)
GridDBにおいて、コンテナ作成やデータ登録を行うサンプルプログラムのビルド、および実行方法の例を紹介します。Web APIによるデータ登録(専用環境プラン/共用環境プラン共通)
GridDB WebAPIを用いたデータ登録方法について説明します。登録データの確認(専用環境プラン/共用環境プラン共通)
サンプルプログラムやWeb APIで登録されたデータをSQLで確認する方法について説明します。開発用ツールの取得(専用環境プラン/共用環境プラン共通)
アプリケーションからのデータ登録に必要なクライアントライブラリ等の取得方法について説明します。
1.2 GridDB Cloudとは
GridDB Cloudは、GridDBをクラウドサービスとして提供するサービスです。
GridDBは、ビッグデータやIoTシステムをターゲットにしたスケールアウト型時系列データベースです。詳細は、『GridDB 機能リファレンス』(GridDB_FeaturesReference.html)を参照してください。
GridDB Cloudでは、GridDBを単体で利用するのに比べ、下記のような利点があります。
- GridDB初期導入の時間の短縮
- 運用の手間の削減
- データや処理量が増えた時のリソース増強対応の簡易化
- クラウドネイティブなアプリとの連携の容易化
1.3 用語の説明
本書で用いられる用語の説明です。
| 用語 | 意味 |
|---|---|
| 運用管理GUI | GridDB Cloudを管理するWebアプリケーションです。 |
| Web API | GridDBにデータ登録を行うためのWeb APIです。AzureのVNet環境がない場合に利用します。 |
| ノード | GridDBでデータ管理を行うひとつのサーバプロセスを指します。 |
| クラスタ | 一体となってデータ管理を行う、1つ、もしくは複数のノードの集合を指します。 |
| コンテナ | ロウの集合を管理する入れ物です。コレクションと時系列コンテナの2種類が存在します。 |
| コレクション | 一般の型のキーを持つロウを管理するコンテナの一種です。 |
| 時系列コンテナ | 時刻型のキーを持つロウを管理するコンテナの一種です。時系列データを扱う専用の機能を持ちます。 |
| ロウ | GridDBで管理する1件分のデータを指します。 キーと複数の値からなるひとまとまりのデータです。 |
2 稼働状態の確認(専用環境プラン/共用環境プラン共通)
まずは運用管理GUIにログインし、クラスタの稼働状態を確認します。GridDB Cloudの設定内容はメールの添付ファイルにて送付しております。ファイルに記載されている運用管理GUIのログインURLにアクセスし、契約ID、ログインID、パスワードを入力してください。
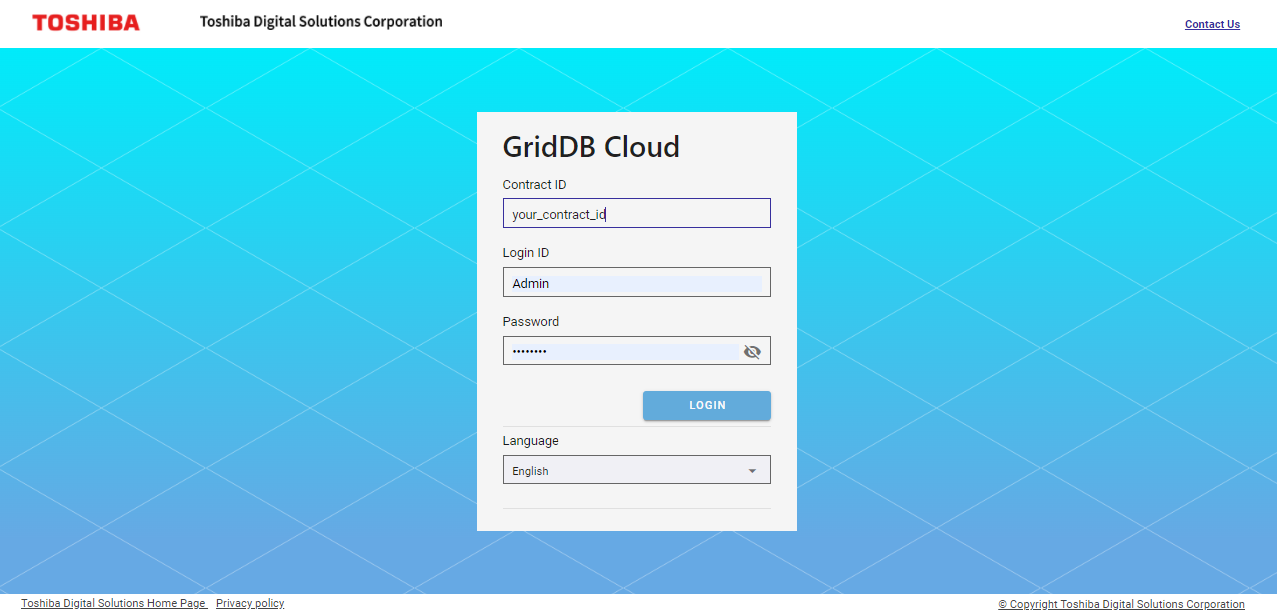
ログインに成功すると、下記のページが表示されます。
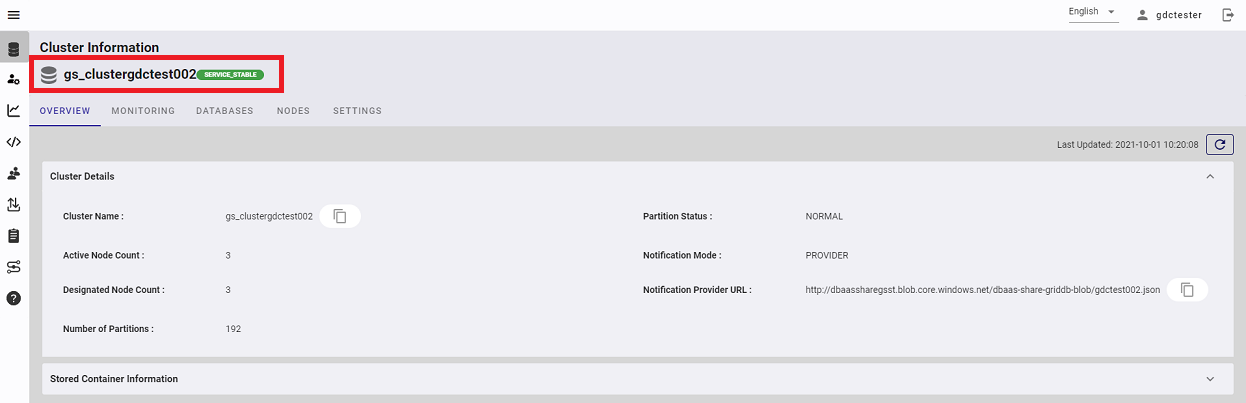
このページでは、クラスタの稼働状態を確認できます。
ページ左上にクラスタ名(この例では「gs_clustergdctest002」)が書いてあり、その横に稼働状態が書いてあります。この例では「SERVICE STABLE」となっており、これはクラスタが正常に稼働していることを表します。稼働状態の一例を下記に示します。
- SERVICE_UNSTABLE
- クラスタを構成する一部のノードが停止しているが、サービスは継続できる状態
- STOP
- すべてのノードが停止し、サービスが継続できない状態
稼働状態は上例以外にも存在します。詳細は『GridDB 機能リファレンス』(GridDB_FeaturesReference.html)を参照してください。
3 VNetの接続設定(専用環境プランのみ)
ここでは、アプリケーションからデータをGridDBに登録するのに必要となる接続設定について説明します。
3.1 概要
GridDB Cloudでは、アプリケーションを配置するVNetとGridDBが動作するVNetを、VNetピアリングを使って接続します。これはプライベートな通信を行うことができるAzureの機能です。VNetピアリング確立後は、プライベートIPアドレスを指定して通信できるようになります。VNetピアリングは従量課金のサービスですので、利用料金など詳細な仕様について知りたい場合は、Microsoftの公式ドキュメントを参照してください。
セキュリティ上の理由より、GridDBとの通信はVNetピアリングで行うことを推奨します。ただし、Azureのアカウントを保持していないなど、VNet環境を利用できない場合は、GridDB Web APIを使って通信します。その場合、本章の手順は不要です。「Web APIによるデータ登録」以降の手順を実施してください。
3.2 クラウドプロバイダの選択
VNetピアリングを確立するためには、左のナビゲーションメニューより「Network Access」を選択します。その後、「CREATE PEERING CONNECTION」ボタンを押します。
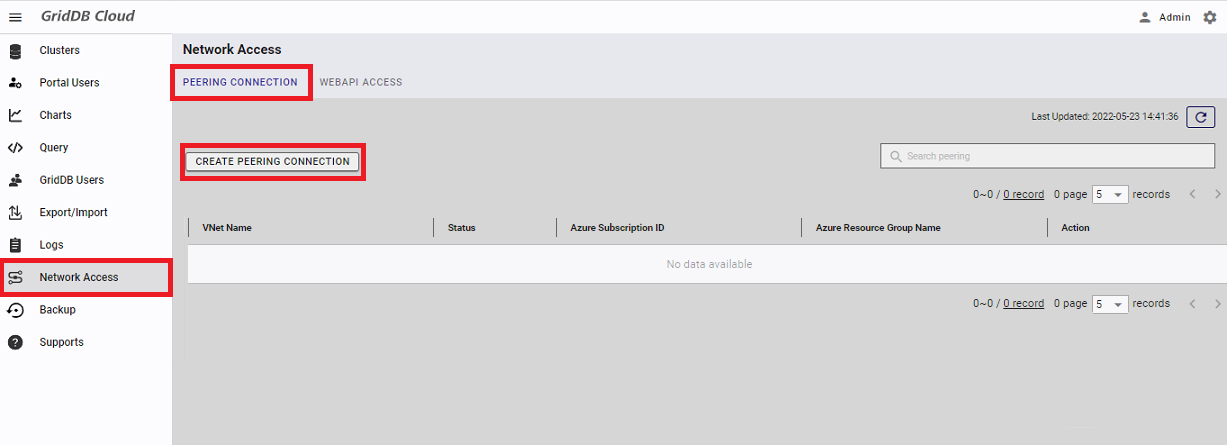
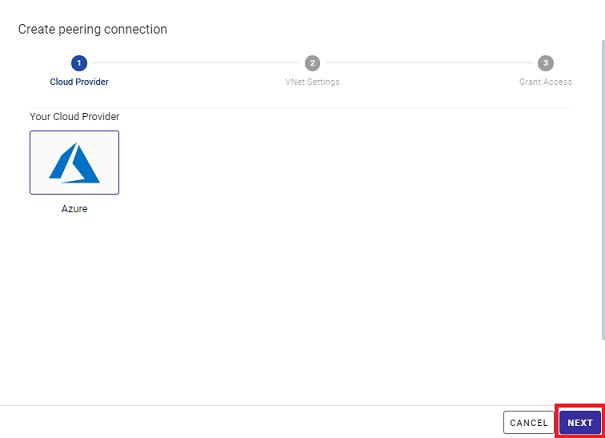
クラウドプロバイダを選ぶダイアログが表示されます。何も変更せず、「NEXT」ボタンを押してください。
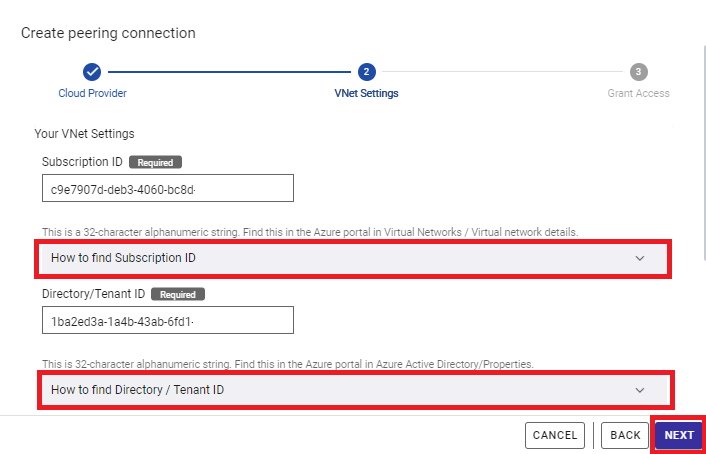
3.3 VNetの情報入力
VNet Settingsの画面が表示されます。ここではアプリケーションが配置されているVNetの情報を入力します。具体的には下記の情報を入力します。取得方法がわからない場合は、各項目の下にあるヒントをクリックして、取得方法を表示してください。
- サブスクリプションID
- テナントID
- リソースグループ名
- VNet名
すべて入力が終わったら、「NEXT」ボタンを押してください。
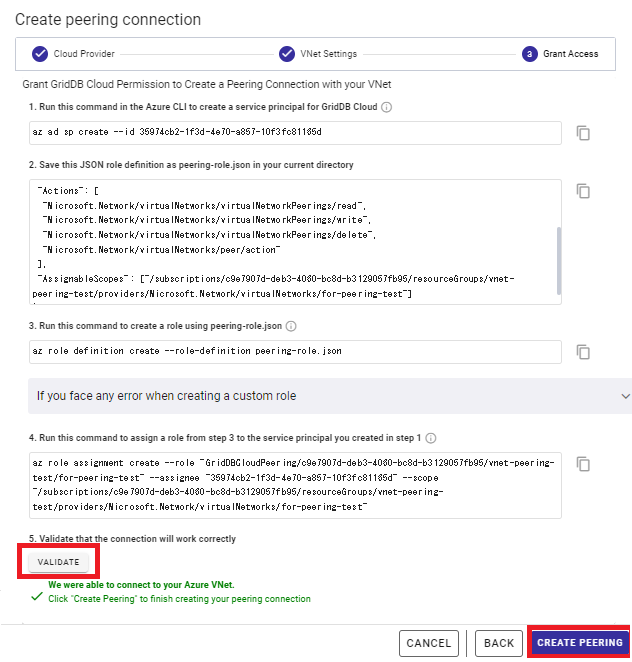
3.4 VNetピアリング確立
次に、VNetピアリングを確立するためのコマンドを実行します。コマンドは下記のいずれかの環境で実行可能です。
- Azureポータルから実行可能なAzure Cloud Shell
- ポータル右上にあるアイコンをクリックして開けば、ダイアログ上に表示されるコマンドを実行可能です。操作が単純なためこちらを推奨します
- Azure仮想マシン内で実行可能なAzure CLI
- Azure CLIが未インストールの場合はインストールが必要です。本ダイアログのコマンド実行前に、「az login」コマンドなどによるログイン処理が必要です
画面に表示されているコマンドを上記の環境で順に実行してください。前画面で入力した情報を元にコマンドを作成していますので、変更は不要です。なお、一部のコマンドにはAzureでの実行権限が必要です。詳しく知りたい場合は手順右側のツールチップにマウスカーソルを合わせ、内容を参照してください。
コマンドの実行が完了したら、「VALIDATE」ボタンを押して接続状態を確認してください。Azure側での情報反映に時間がかかる場合があるため、エラーが発生する場合は1分程度待機し、再度ボタンを押してください。接続が確認できたら、「CREATE PEERING」ボタンを押して、VNetピアリングを確立します。
コマンド実行が正常に完了しているにもかかわらず、「VALIDATE」ボタンや「CREATE PEERING」ボタンの操作でエラーが発生する場合は、サポート窓口までお問い合わせください。
3.5 VNetピアリングの状態確認
VNetピアリングの一覧画面では、接続状態を確認できます。先ほど作成したVNetピアリングの「Status」がConnectedとなっていることを確認してください。以降はGridDBのプライベートIPアドレスを使った通信が可能です。
なお、AzureポータルからVNetピアリングを削除した場合などは、「Status」がDisconnectedとなります。再度接続したい場合は、新たにVNetピアリングを確立してください。

3.6 注意事項
- GridDBとアプリケーションのネットワークアドレスが競合する場合はVNetピアリングを確立できません。競合する場合は、アプリケーションが配置されているVNetのネットワークアドレスを変更してください。
4 サンプルプログラムの実行(専用環境プランのみ)
ここでは、アプリケーションからGridDBにデータを登録する方法について説明します。データの登録には、前章で説明しているVNetピアリングの確立に成功していることが必要です。未確立の場合は本章の内容を実行する前に前章の内容を実行し、VNetピアリングを確立させてください。
4.1 サンプルプログラム作成
4.1.1 サンプルプログラム概要
GridDBでは様々な言語のクライアントAPIをサポートしています。本ガイドでは、そのうちJavaとC言語を例に説明します。
どの言語の例も、接続情報を引数で受け取り、下記の流れでデータ登録・表示を行います。登録するサンプルデータはJavaとC言語で同一です。
接続パラメータを設定
接続用インスタンスを作成
接続し、コンテナ(コンテナ名:point01)を作成
TIMESTAMP, BOOL, DOUBLEの3カラムで構成
ロウを登録
現在時刻, false, 100.0を登録
過去6時間以内に登録されたロウを表示
4.1.2 クライアントAPIのライブラリ取得
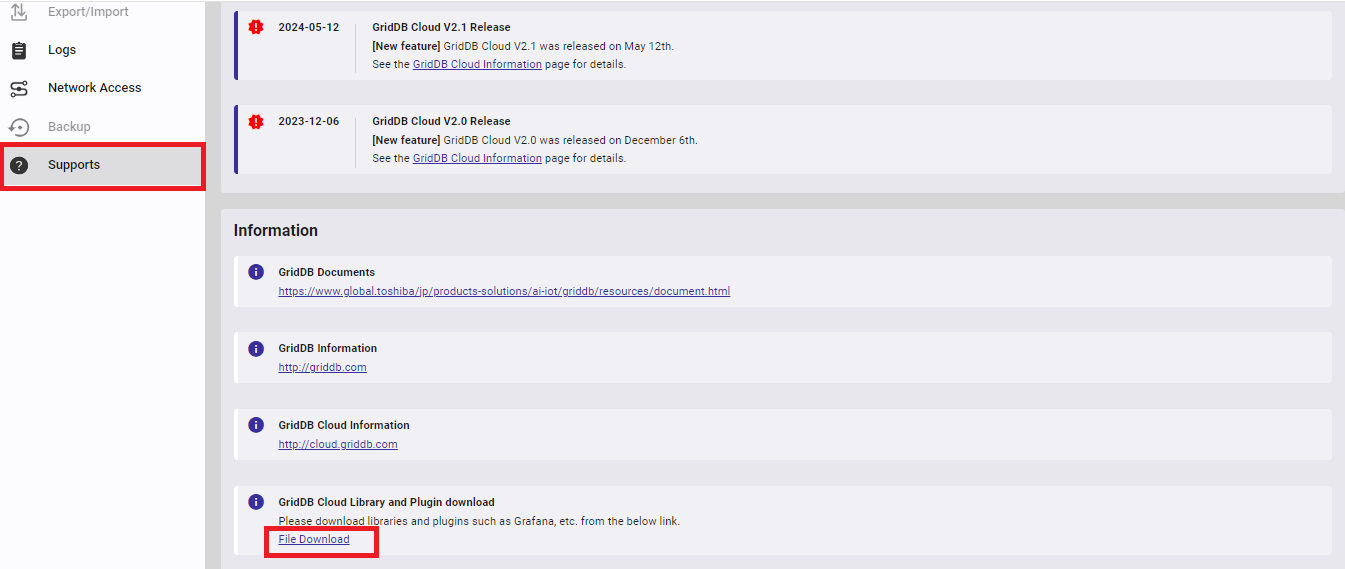
本ガイドで利用するクライアントAPIのライブラリはrpm形式で提供しています。rpmと、その他ツール一式の配布URLはSupportsページに記載しています。「File Download」のURLリンクからダウンロードを行ってください。
4.1.3 サンプルプログラム作成(Java)
サンプルプログラムが利用するJavaのクライアントAPIを、rpm経由でインストールします。
rpm -Uvh griddb-ee-java_lib-5.6.0-linux.x86_64.rpm
Verifying... ################################# [100%]
Preparing... ################################# [100%]
Updating / installing...
1:griddb-ee-java_lib-5.6.0-linux
################################# [100%]
下記のwarningが発生する場合がありますが、問題ないので手順を先に進めてください。
- warning: user gsadm does not exist - using root
- warning: group gridstore does not exist - using root
次にサンプルプログラムを作成します。下記をコピーし、cloud_sample.javaというファイル名で任意のディレクトリに保存してください。
import java.util.Date;
import java.util.Properties;
import com.toshiba.mwcloud.gs.GSException;
import com.toshiba.mwcloud.gs.GridStore;
import com.toshiba.mwcloud.gs.GridStoreFactory;
import com.toshiba.mwcloud.gs.RowKey;
import com.toshiba.mwcloud.gs.RowSet;
import com.toshiba.mwcloud.gs.TimeSeries;
import com.toshiba.mwcloud.gs.TimestampUtils;
import com.toshiba.mwcloud.gs.TimeUnit;
// Storage and extraction of a specific range of time-series data
public class cloud_sample {
static class Point {
@RowKey Date timestamp;
boolean active;
double voltage;
}
public static void main(String[] args) throws GSException {
// Acquiring a GridStore instance
Properties props = new Properties();
props.setProperty("notificationProvider", args[0]);
props.setProperty("clusterName", args[1]);
props.setProperty("user", args[2]);
props.setProperty("password", args[3]);
GridStore store = GridStoreFactory.getInstance().getGridStore(props);
// Creating a TimeSeries (Only obtain the specified TimeSeries if it already exists)
TimeSeries<Point> ts = store.putTimeSeries("point01", Point.class);
// Preparing time-series element data
Point point = new Point();
point.active = false;
point.voltage = 100;
// Store the time-series element (GridStore sets its timestamp)
ts.append(point);
// Extract the specified range of time-series elements: last six hours
Date now = TimestampUtils.current();
Date before = TimestampUtils.add(now, -6, TimeUnit.HOUR);
RowSet<Point> rs = ts.query(before, now).fetch();
while (rs.hasNext()) {
point = rs.next();
System.out.println(
"Time=" + TimestampUtils.format(point.timestamp) +
" Active=" + point.active +
" Voltage=" + point.voltage);
}
// Releasing resource
store.close();
}
}
rpm経由でインストールしたライブラリは/usr/share/javaに保存されているので、まずはパスを設定します。その後、サンプルプログラムをコンパイルします。
export CLASSPATH=${CLASSPATH}:/usr/share/java/gridstore.jar
javac cloud_sample.java
プログラムの作成は以上です。「接続情報の確認」以降の手順を実施し、プログラムの実行を行ってください。
4.1.4 サンプルプログラム作成(C言語)
サンプルプログラムが利用するC言語のクライアントAPIを、rpm経由でインストールします。
rpm -Uvh griddb-ee-c_lib-5.6.0-linux.x86_64.rpm
Verifying... ################################# [100%]
Preparing... ################################# [100%]
Updating / installing...
1:griddb-ee-c_lib-5.6.0-linux
################################# [100%]
下記のwarningが発生する場合がありますが、問題ないので手順を先に進めてください。
- warning: user gsadm does not exist - using root
- warning: group gridstore does not exist - using root
次にサンプルプログラムを作成します。下記をコピーし、cloud_sample.cというファイル名で任意のディレクトリに保存してください。
#include "gridstore.h"
#include <stdlib.h>
#include <stdio.h>
typedef struct {
GSTimestamp timestamp;
GSBool active;
double voltage;
} Point;
GS_STRUCT_BINDING(Point,
GS_STRUCT_BINDING_KEY(timestamp, GS_TYPE_TIMESTAMP)
GS_STRUCT_BINDING_ELEMENT(active, GS_TYPE_BOOL)
GS_STRUCT_BINDING_ELEMENT(voltage, GS_TYPE_DOUBLE));
// Storage and extraction of a specific range of time-series data
int sample(const char * addr, const char *clusterName,
const char *user, const char *password) {
GSGridStore *store;
GSTimeSeries *ts;
Point point;
GSTimestamp now;
GSTimestamp before;
GSQuery *query;
GSRowSet *rs;
GSResult ret = !GS_RESULT_OK;
const GSPropertyEntry props[] = {
{ "notificationProvider", addr },
{ "clusterName", clusterName },
{ "user", user },
{ "password", password } };
const size_t propCount = sizeof(props) / sizeof(*props);
// Acquiring a GridStore instance
gsGetGridStore(gsGetDefaultFactory(), props, propCount, &store);
// Creating a TimeSeries (Only obtain the specified TimeSeries if it already exists)
gsPutTimeSeries(store, "point01",
GS_GET_STRUCT_BINDING(Point), NULL, GS_FALSE, &ts);
// Preparing time-series element data
point.active = GS_FALSE;
point.voltage = 100;
// Store the time-series element (GridStore sets its timestamp)
gsAppendTimeSeriesRow(ts, &point, NULL);
// Extract the specified range of time-series elements: last six hours
now = gsCurrentTime();
before = gsAddTime(now, -6, GS_TIME_UNIT_HOUR);
gsQueryByTimeSeriesRange(ts, before, now, &query);
ret = gsFetch(query, GS_FALSE, &rs);
while (gsHasNextRow(rs)) {
GSChar timeStr[GS_TIME_STRING_SIZE_MAX];
ret = gsGetNextRow(rs, &point);
if (!GS_SUCCEEDED(ret)) break;
gsFormatTime(point.timestamp, timeStr, sizeof(timeStr));
printf("Time=%s", timeStr);
printf(" Active=%s", point.active ? "true" : "false");
printf(" Voltage=%.1lf\n", point.voltage);
}
// Releasing resource
gsCloseGridStore(&store, GS_TRUE);
return (GS_SUCCEEDED(ret) ? EXIT_SUCCESS : EXIT_FAILURE);
}
void main(int argc,char *argv[]){ sample(argv[1],argv[2],argv[3],argv[4]);}
次に、サンプルプログラムをコンパイルします。下記はCentOSの例です。
gcc cloud_sample.c -lgridstore
プログラムの作成は以上です。「接続情報の確認」以降の手順を実施し、プログラムの実行を行ってください。
4.1.5 その他のサンプルプログラム
GridDBでは各機能のサンプルプログラムを提供しています。詳細は『GridDB プログラミングガイド』(GridDB_ProgrammingGuide.html)を参照してください。
また、API仕様については下記のようなガイドがあります。必要に応じて参照してください。
- 『GridDB Java APIリファレンス』(GridDB_Java_API_Reference.html)
- 『GridDB C APIリファレンス』(GridDB_C_API_Reference.html)
- 『GridDB ODBCドライバ説明書』(GridDB_ODBC_Driver_UserGuide.html)
なお、注意事項に記載してあるように、GridDB Cloudの接続方式はプロバイダ方式のみをサポートしています。サンプルプログラム実行の際はご注意ください。
4.2 接続情報の確認
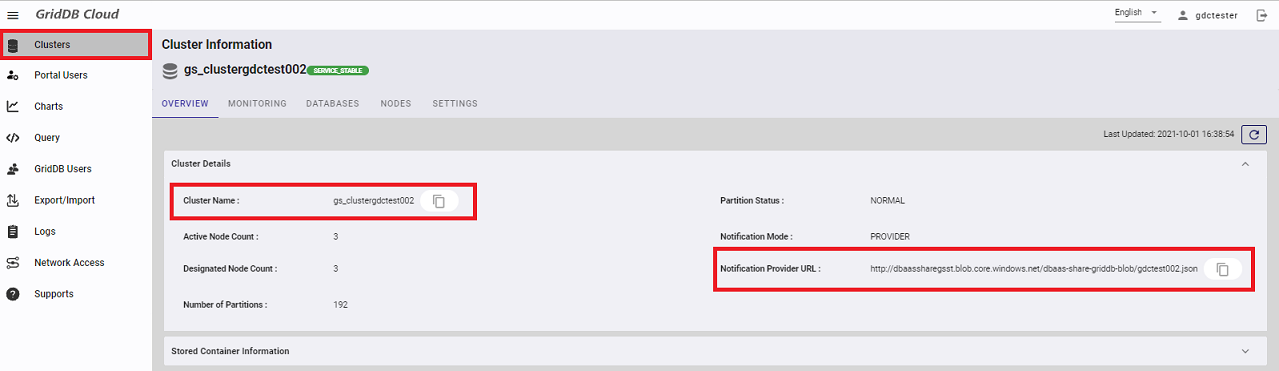
作成したプログラムを実行する前に、接続情報の確認と、データベースユーザの作成を行います。「Clusters」画面に遷移し、下記の情報をメモしてください。
- Cluster Name
- Notification provider URL
4.3 データベースユーザ作成
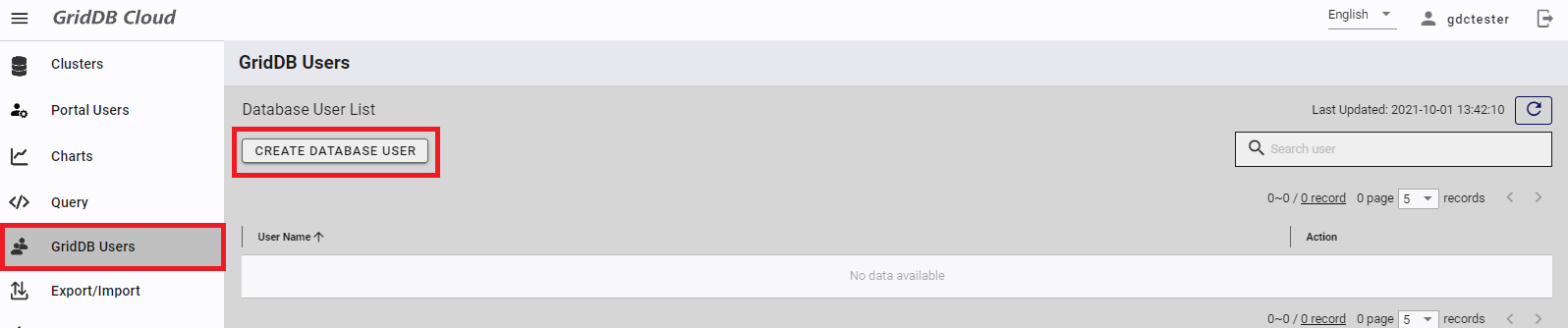
次にデータベースユーザを作成します。「GridDB Users」画面に遷移し、「CREATE DATABASE USER」ボタンを押してください。
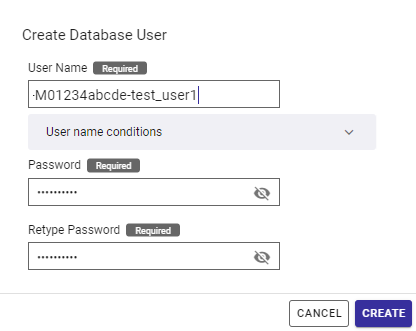
任意のユーザ名とパスワードを設定し、「CREATE」ボタンを押してください。本ガイドの例では、下記のように指定しています。
- User Name
- M01234abcde-test_user1
- Password
- test_user1
4.4 サンプルプログラム実行
前節までに確認した接続情報とデータベースユーザ名・パスワードを引数として渡し、サンプルプログラムを実行します。
<Javaの場合>
java cloud_sample <Notification Provider URL> <クラスタ名> <データベースユーザ名> <データベースユーザパスワード>
<C言語の場合>
./a.out <Notification Provider URL> <クラスタ名> <データベースユーザ名> <データベースユーザパスワード
下記のような登録結果が表示されれば成功です。
Time=2021-03-31T07:52:58.770Z Active=false Voltage=100.0
サンプルプログラムの実行については以上です。GridDBのプログラミング方法について詳しく知りたい場合は、その他のサンプルプログラムを参照してください。
4.5 注意事項
GridDBの接続方式は下記の3種類があります。
- マルチキャスト方式
- 固定リスト方式
- プロバイダ方式
GridDB Cloudでは、サンプルプログラムで指定したプロバイダ方式のみが有効です。プロバイダ方式はNotification Provider URLを接続先として指定する方式です。他の方式は利用できませんのでご注意ください。
方式の詳細は『GridDB 機能リファレンス』(GridDB_FeaturesReference.html)を参照してください。
5 WebAPIによるデータ登録(専用環境プラン/共用環境プラン共通)
ここでは、GridDB Web APIを用いたデータ登録方法について説明します。専用環境プランを契約していて、かつAzureのVNet環境を利用可能な場合は、クライアントAPIを利用する接続方法を推奨します。その場合、本章ではなくVNetの接続設定を参照してください。
5.1 接続前の準備
5.1.1 接続元の設定
初期設定では、WebAPIへのすべてのアクセスは拒否されています。本手順では接続許可するIPを設定し、WebAPIを使ったデータ登録を可能にします。
左のナビゲーションメニューより「Network Access」を選択します。「WEBAPI ACCESS」タブに遷移し、「ADD ALLOWED IP ADDRESS」ボタンをクリックします。
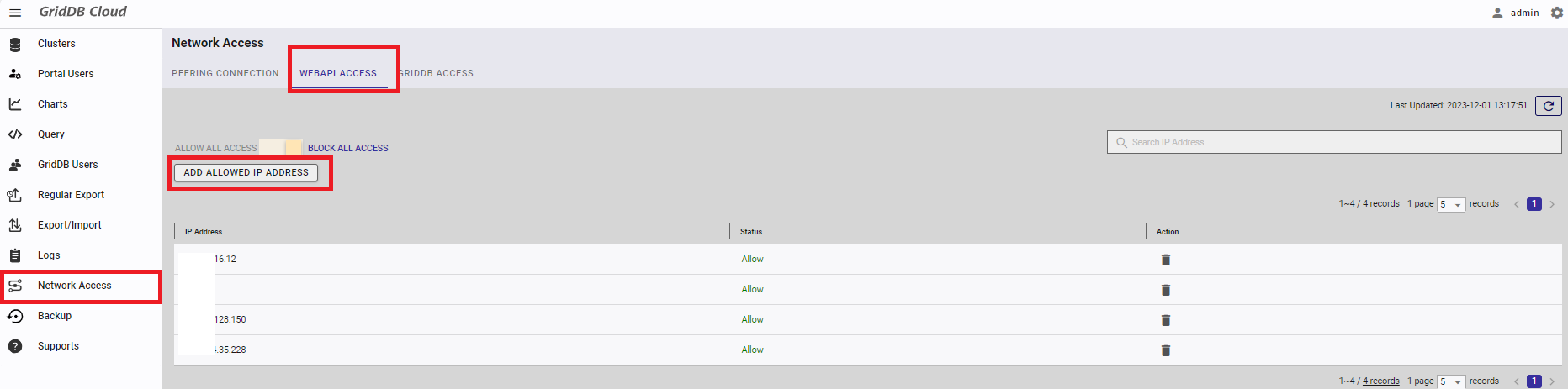
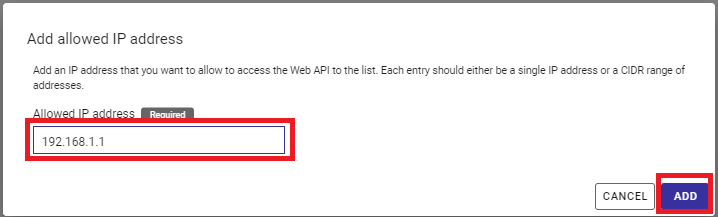
表示されたダイアログに、接続許可するIPアドレスを入力し、「ADD」ボタンを押します。登録されていないIPアドレスから接続した場合は、接続時に403(Forbidden)などのエラーが返ります。192.168.1.1のような単一指定や、192.168.1.0/24のような複数指定が可能です。
5.1.2 接続先の確認
Web APIのURLは契約時に送付されるメールに記載しています。また、運用管理GUIにログインしたときに表示される、クラスタの稼働状態の画面にも記載があります。
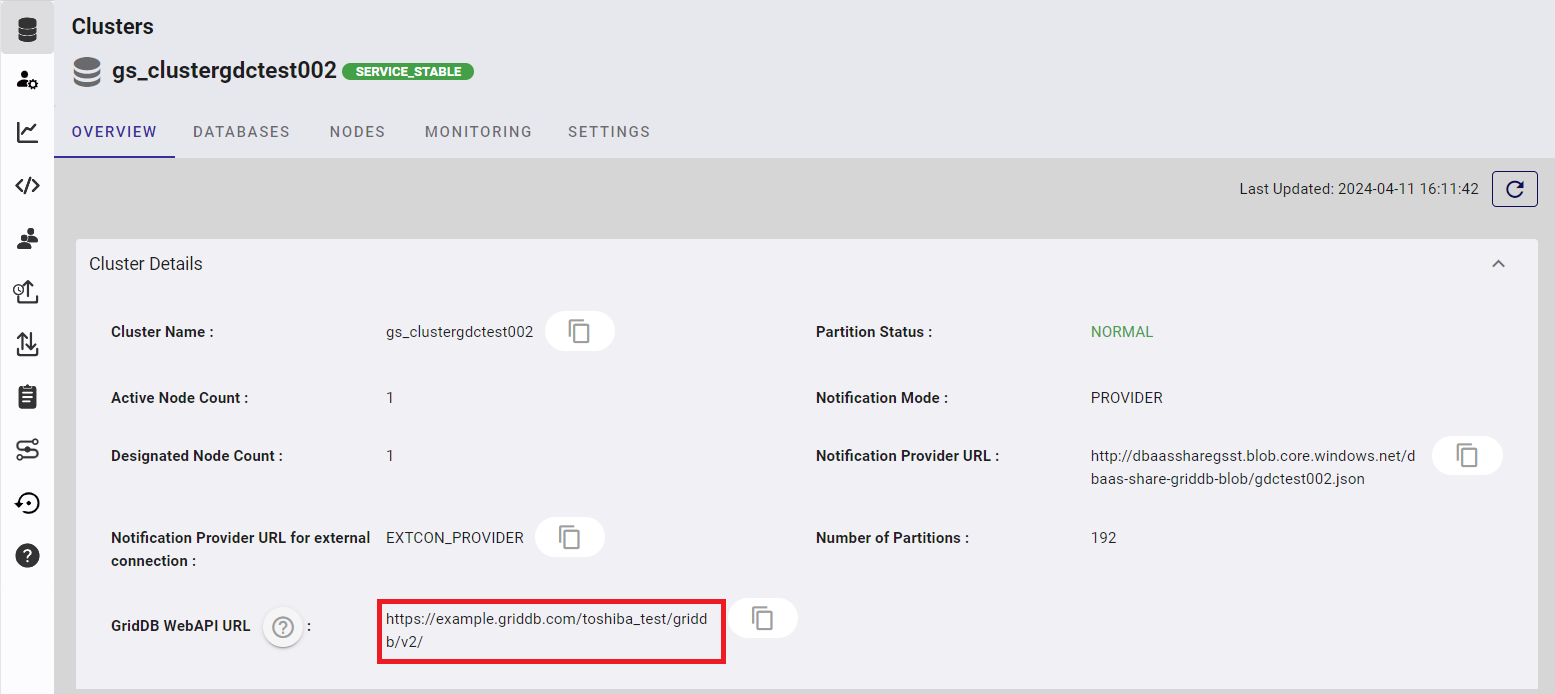
専用環境プランの形式:
https://{ベースURL}
専用環境プランの例:
https://example.griddb.com/toshiba_test/griddb/v2/
共用環境プランの形式:
https://{ベースURL}/{クラスタ名}/dbs/{データベース名}
共用環境プランの例:
https://example.griddb.com/toshiba_test/griddb/v2/gs_clustergdctest002/dbs/1a2b3c4d/
APIを利用するときは、ベースURLに加え、クラスタ名やデータベース名が必要です。これから確認をしていきます。共用環境プランの場合はクラスタ名とデータベース名がURLに含まれているので、これらを確認するための項は読み飛ばしても問題ありません。
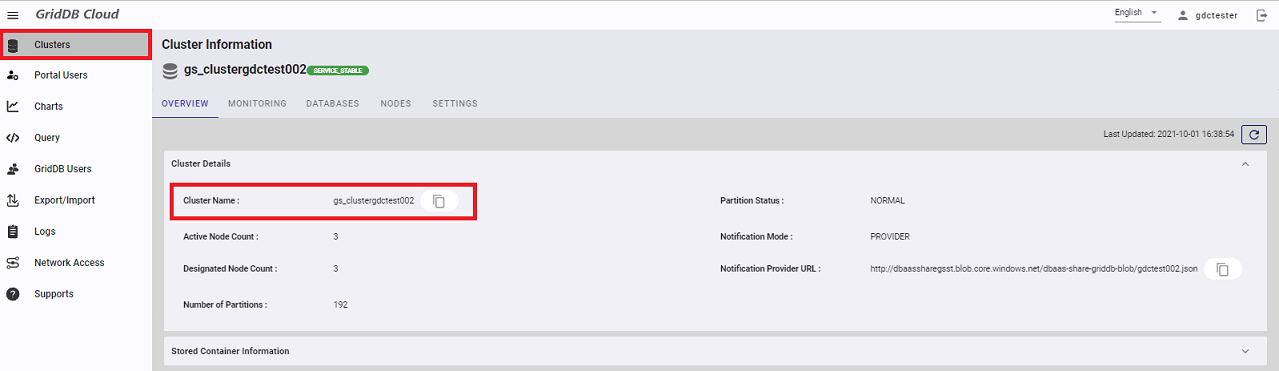
5.1.3 クラスタ名の確認
Web APIのURLに必要なクラスタ名を確認します。「Clusters」画面に遷移し、下記の情報をメモしてください。
- Cluster Name
5.1.4 データベース名の確認
Web APIのURLに必要なデータベース名を確認します。「Databases」画面に遷移し、表示されているデータベース名をメモしてください。
[注]: 専用環境プランでは、「public」が表示されます。共用環境プランでは、データベース名がランダムな英数字(例:1a2b3c4d)となっているデータベースが1つだけ利用できます。

5.1.5 データベースユーザ作成
次にデータベースユーザを作成します。「GridDB Users」画面に遷移し、「CREATE DATABASE USER」ボタンを押してください。
任意のユーザ名とパスワードを設定し、「CREATE」ボタンを押してください。本ガイドの例では、下記のように指定しています。
[注]: 共用環境プランでは、データベースユーザ名の先頭に契約ID(例:M01234abcde)が自動的に付与されます。
- User Name
- M01234abcde-test_user1
- Password
- test_user1
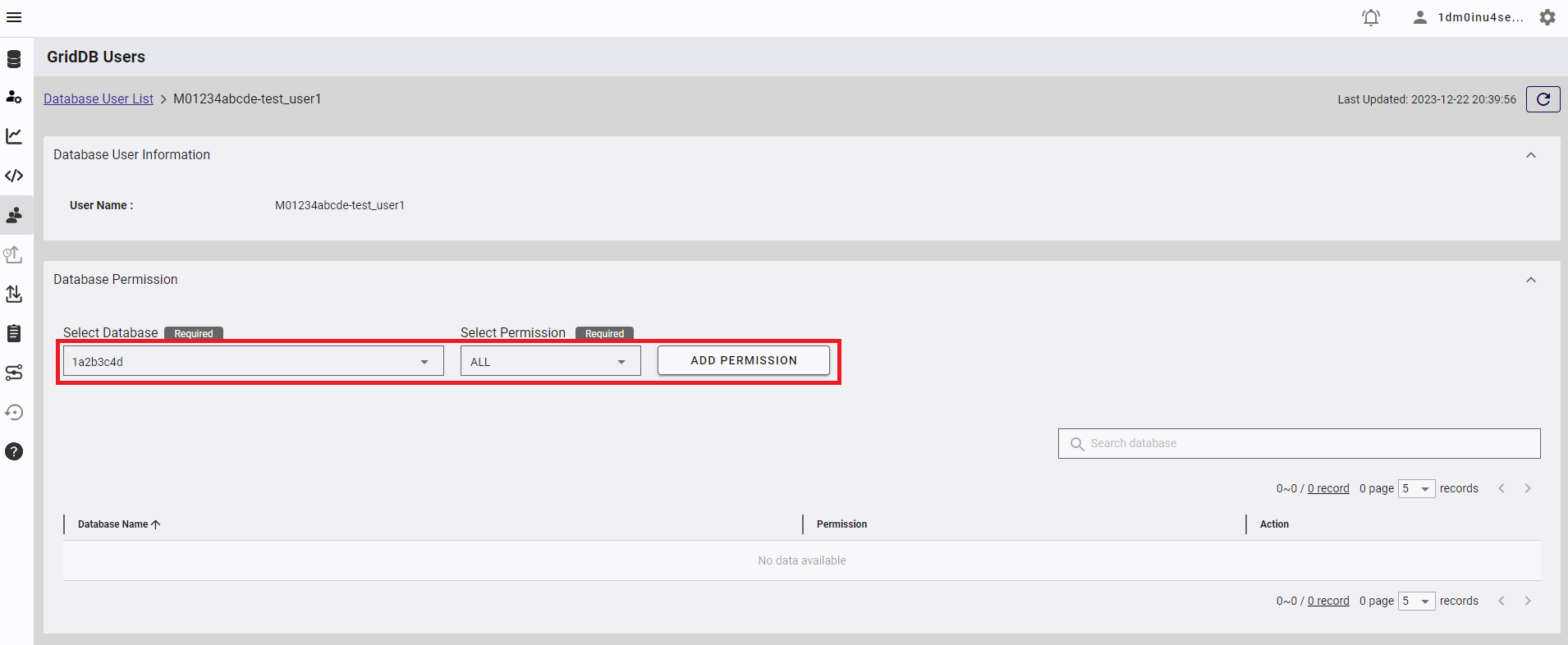
「public」データベース以外を利用する場合、作成したデータベースユーザに、データベースへの書き込み権限を付与する必要があります。まず、作成したデータベースユーザ名をクリックし、データベースユーザの設定画面を表示します。

権限を付与したいデータベースを選択し、「ALL」権限を選択し、「ADD PERMISSION」ボタンを押してください。
5.1.6 ヘッダの設定
Web APIへの接続には下記のヘッダが必須です。すべてのリクエストに付与してください。
| ヘッダ | 説明 | 必須 |
|---|---|---|
| Content-Type | application/json; charset=UTF-8 | ○ |
| Authorization | GridDBへアクセスするユーザとパスワードをBasic認証の形式で指定します。例えばM01234abcde-test_user1/test_user1の場合、ヘッダは「Basic TTAxMjM0YWJjZGUtdGVzdF91c2VyMTp0ZXN0X3VzZXIx」となります。 | ○ |
5.2 コンテナの作成
ここでは、TIMESTAMP型, BOOL型, DOUBLE型の3カラムで構成される時系列コンテナpoint01を作成します。
リクエスト送信先のURLは下記です。
POST https://{ベースURL}/{クラスタ名}/dbs/{データベース名}/containers
例:
POST https://example.griddb.com/toshiba_test/griddb/v2/gs_clustergdctest002/dbs/1a2b3c4d/containers
送信するリクエストボディは下記です。
{
"container_name" : "point01",
"container_type" : "TIME_SERIES",
"rowkey" : true,
"columns" : [
{"name": "timestamp", "type": "TIMESTAMP"},
{"name": "active", "type": "BOOL"},
{"name": "voltage", "type": "DOUBLE"}
]
}
HTTPレスポンスのステータスが201(Created)になっていれば成功です。
5.3 ロウの登録
次に、作成したコンテナpoint01にロウを登録します。
リクエスト送信先のURLは下記です。
PUT https://{ベースURL}/{クラスタ名}/dbs/{データベース名}/containers/{コンテナ名}/rows
例:
PUT https://example.griddb.com/toshiba_test/griddb/v2/gs_clustergdctest002/dbs/1a2b3c4d/containers/point01/rows
送信するリクエストボディは下記です。
[["2021-06-28T10:30:00.000Z", false, "100"]]
HTTPレスポンスのステータスが200(OK)になっていて、レスポンスボディが下記のようになっていれば成功です。
{
"count": 1
}
5.4 ロウの取得
次に、コンテナpoint01に登録したロウを取得します。
リクエスト送信先のURLは下記です。
POST https://{ベースURL}/{クラスタ名}/dbs/{データベース名}/containers/{コンテナ名}/rows
例:
POST https://example.griddb.com/toshiba_test/griddb/v2/gs_clustergdctest002/dbs/1a2b3c4d/containers/point01/rows
送信するリクエストボディは下記です。取得対象は最大100件で、2021年6月28日 4時30分以降のデータを取得するという条件になっています。
{
"limit" : 100,
"condition" : "timestamp >= TIMESTAMP('2021-06-28T04:30:00.000Z')"
}
HTTPレスポンスのステータスが200(OK)になっていて、レスポンスボディが下記のようになっていれば成功です。
{
"columns": [
{
"name": "timestamp",
"type": "TIMESTAMP"
},
{
"name": "active",
"type": "BOOL"
},
{
"name": "voltage",
"type": "DOUBLE"
}
],
"rows": [
[
"2021-06-28T10:30:00.000Z",
false,
100.0
]
],
"offset": 0,
"limit": 100,
"total": 1
}
WebAPIによるデータ登録・取得のチュートリアルは以上です。他のAPIについて知りたい場合はWeb APIリファレンスの各APIの節を参照ください。
6 登録データの確認(専用環境プラン/共用環境プラン共通)
ここでは、登録したデータをSQLで確認する方法について説明します。前章のサンプルプログラムやWeb APIによる登録データを確認するため、登録済みでない場合は登録をお願いします。
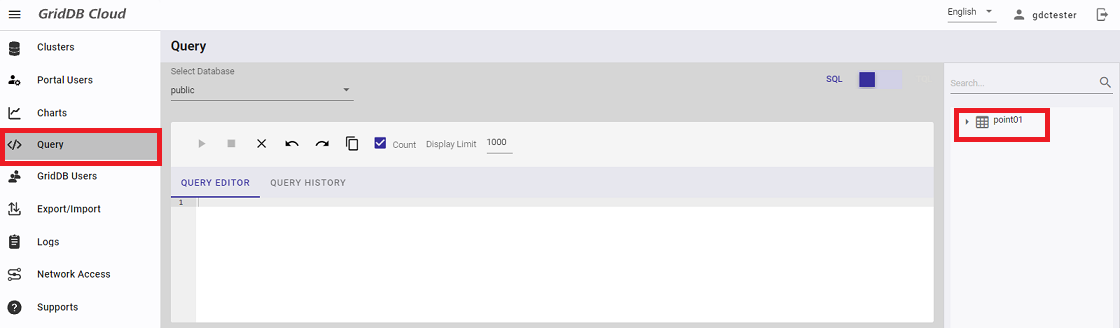
まず、「Query」画面を開きます。右側に作成したコンテナ「point01」があることを確認します。
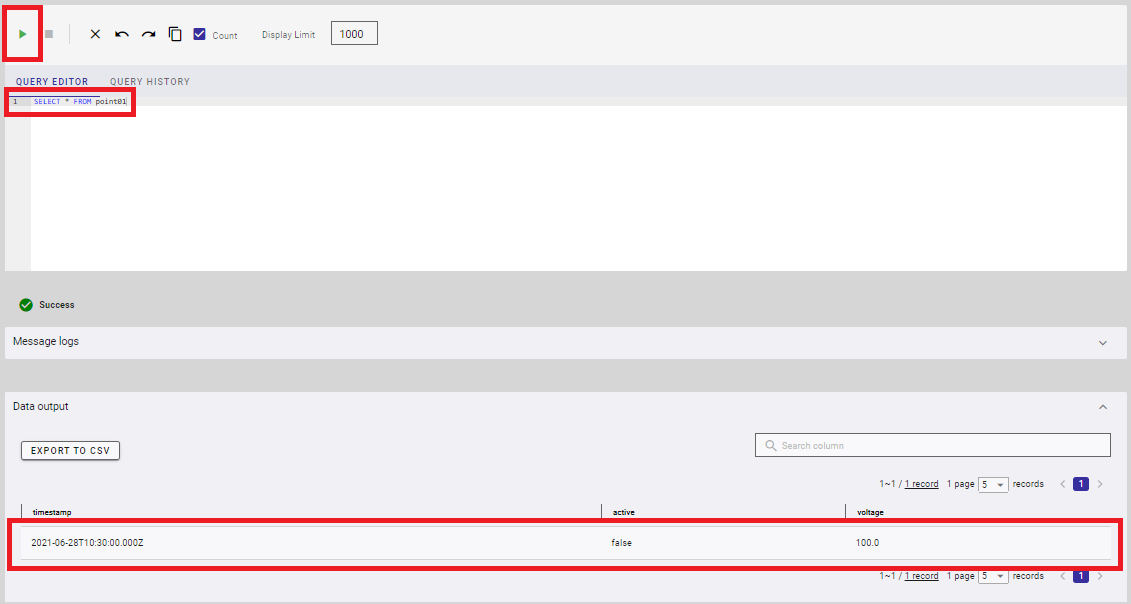
次に、point01のデータをすべて取得する下記のSQL文を入力し、実行ボタンを押します。エディタ部分に文字が入力できない場合は、F5キーを押して画面を更新してください。
SELECT * FROM point01
実行結果が下記のように表示されていれば成功です。
7 開発用ツールの取得(専用環境プラン/共用環境プラン共通)
ここでは、アプリケーションからのデータ登録に必要な開発ツールの取得方法について説明します。
クライアントAPIのrpmやデータ連携ツールのプラグインなど、ツール類の配布URLは、Supportsページに記載しています。「File Download」のURLリンクからダウンロードを行ってください。
専用環境プランと共用環境プランではファイルの構成が異なります。専用環境プランの構成を下記に示します。
| ディレクトリ名/ファイル名 | 概要 |
|---|---|
| embulk-output-plugin | データ連携ツール「Embulk」の出力プラグインです。 |
| fluent-plugin-griddb | データ連携ツール「FluentD」の出力プラグインです。 |
| grafana-input-plugin | データ可視化ツール「Grafana」の入力プラグインです。 |
| JDBC | JDBCドライバのモジュール一式です。 |
| logstash-output-plugin | データ連携ツール「Logstash」の出力プラグインです。 |
| ODBC | ODBCドライバのモジュール一式です。 |
| telegraf-output-plugin | データ連携ツール「Telegraf」の出力プラグインです。 |
| gdbConnectSample.zip | Azure Functionsと連携するためのサンプルプログラムです。 |
| griddb-ee-c_lib-5.6.0-linux.x86_64.rpm | C言語用クライアントAPIのrpmファイルです。 |
| griddb-ee-java_lib-5.6.0-linux.x86_64.rpm | Java用クライアントAPIのrpmファイルです。 |
| griddb-ee-webapi-5.6.0-linux.x86_64.rpm | GridDB WebAPIのrpmファイルです。 |
| griddbCloudDataExport.zip | GridDB Cloudが提供するデータ取り出しツールです |
共用環境プランの構成を下記に示します。
| ディレクトリ名/ファイル名 | 概要 |
|---|---|
| fluent-plugin-griddb | データ連携ツール「FluentD」の出力プラグインです。 |
| grafana-input-plugin | データ可視化ツール「Grafana」の入力プラグインです。 |
| logstash-output-plugin | データ連携ツール「Logstash」の出力プラグインです。 |
| telegraf-output-plugin | データ連携ツール「Telegraf」の出力プラグインです。 |
| griddbCloudDataExport.zip | GridDB Cloudが提供するデータ取り出しツールです |