GridDB ETL 自動集計ガイド
Revision: 5.5.0-902
1 はじめに
1.1 本書の構成
本書では、GridDBの蓄積データに対するETLツールを用いた自動集計について説明します。各章の内容は次のとおりです。
はじめに
本書の構成及び用語について説明します。ETLツールを用いた自動集計について
ETLツールを用いた自動集計について説明します。ASTERIA Warpについて
ASTERIA Warpについて説明します。ASTERIA Warpを用いたGridDBの集計手順
ASTERIA WarpでGridDBのデータを集計して、集計結果をGridDBに出力する例を紹介します。GridDBとASTERIA Warpのデータ型のマッピング
GridDBとASTERIA Warpのデータ型のマッピングを表に示します。Talend Open Studioについて
Talend Open Studioについて説明します。Talend Open Studioを用いたGridDBの集計手順
Talend Open StudioでGridDBのデータを集計して、集計結果をGridDBに出力する例を紹介します。GridDBとTalend Open Studioのデータ型のマッピング
GridDBとTalend Open Studioのデータ型のマッピングを表に示します。
1.2 用語の説明
本書で用いられる用語の説明です。
| 用語 | 意味 |
|---|---|
| ETL | Extract(抽出)、Transform(変換)、Load(格納)の頭文字を取った用語で、一般的にデータ統合・加工を行うプロセスの総称です。 |
| Talend Open Studio | Talend株式会社が提供しているETLツールです。詳細はTalend株式会社の公式ページを参照してください。 |
| ASTERIA Warp | アステリア株式会社が提供しているETLツールです。詳細はアステリア株式会社の公式ページを参照してください。 |
| 自動集計 | データの最大や最小、平均などの集計処理を自動で行うことを表します。 |
| バッチ更新 | INSERTやUPDATE、DELETEなどデータ更新を行うSQL文を一度に複数、データベースに送って処理する機能です。 |
2 ETLツールを用いた自動集計について
2.1 利用シーン
IoTの活用が広がる中で、時間とともに時系列データは大量に発生し、データベースに蓄積されます。
時系列データを参照、利用する際には、軽く扱いやすくするために、一定時間間隔での最大、最小、平均などの集計を行う場合が多くあります。しかし、大量の時系列データに対する集計演算は重く、結果取得までの待ち時間が長くなる傾向になります。
そこで、収集された大量の時系列データから、あらかじめバックグラウンドで自動的に集計演算を行い集計結果を蓄積する、自動集計が一般的に用いられます。これにより、ユーザは計算済みの集計結果にアクセスできるため、処理時間を短くできます。
本ガイドでは、この自動集計をGridDBとETLツールを用いて、実現する方法を説明します。
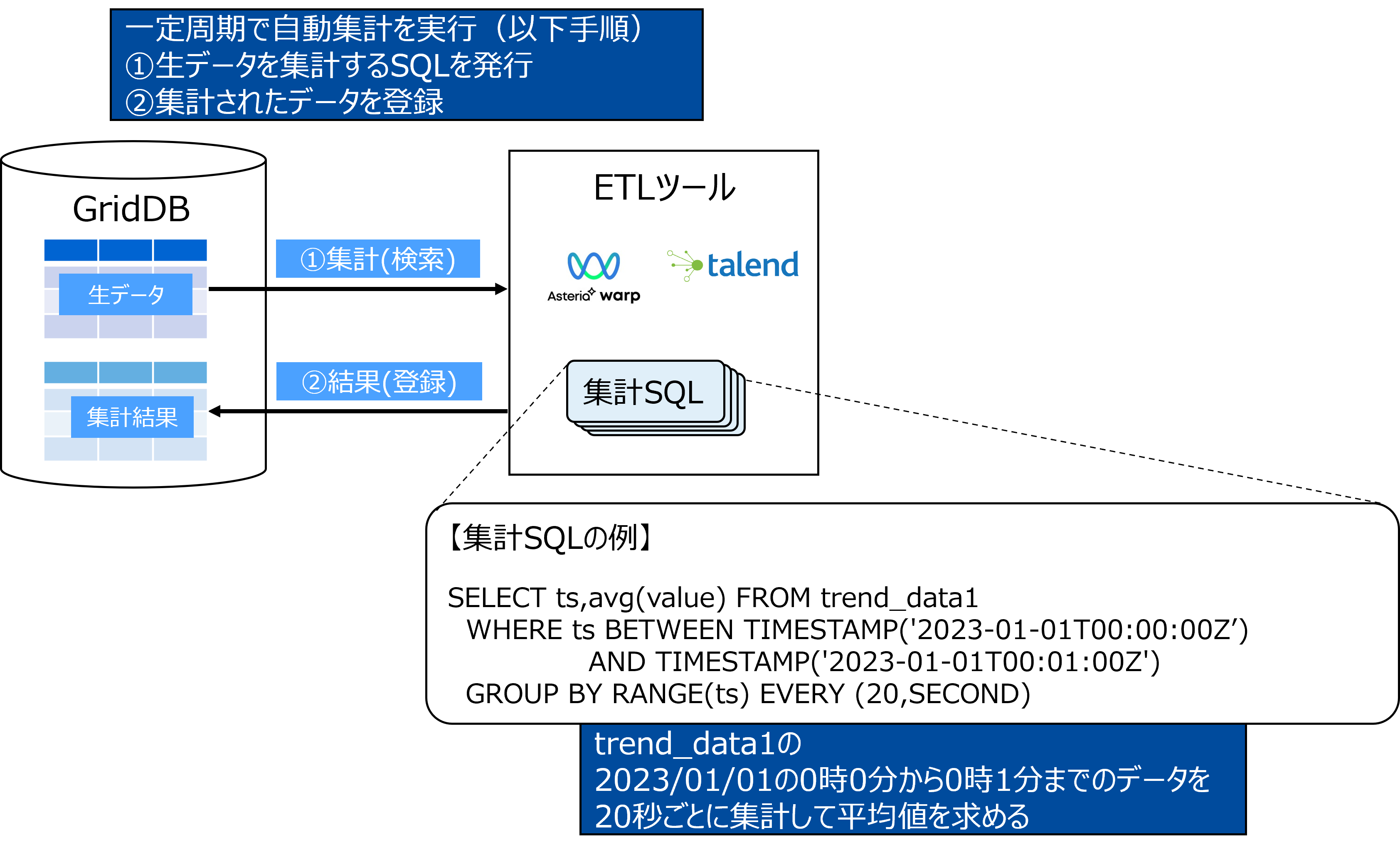
2.2 処理概要
本ガイドでは、あらかじめ集計対象のコンテナと出力先のコンテナを作成し、作成した集計対象のコンテナに対して、時系列データを登録します。登録した時系列データに対して集計を行い、出力先のコンテナに登録を行います。
- 事前準備
事前準備としてGridDBのインストールとGridDBのJDBCドライバの入手を行います。
GridDBのインストールについては『GridDB クイックスタートガイド』(GridDB_QuickStartGuide.html)を参照してください。
またGridDBのJDBCドライバはGridDBをインストールした環境から入手してください。
GridDBのJDBCドライバの場所のみ抜粋
/usr/griddb-ee-X.X.X/ インストールディレクトリ
lib/
gridstore-jdbc-X.X.X.jar
処理の流れについて説明します。
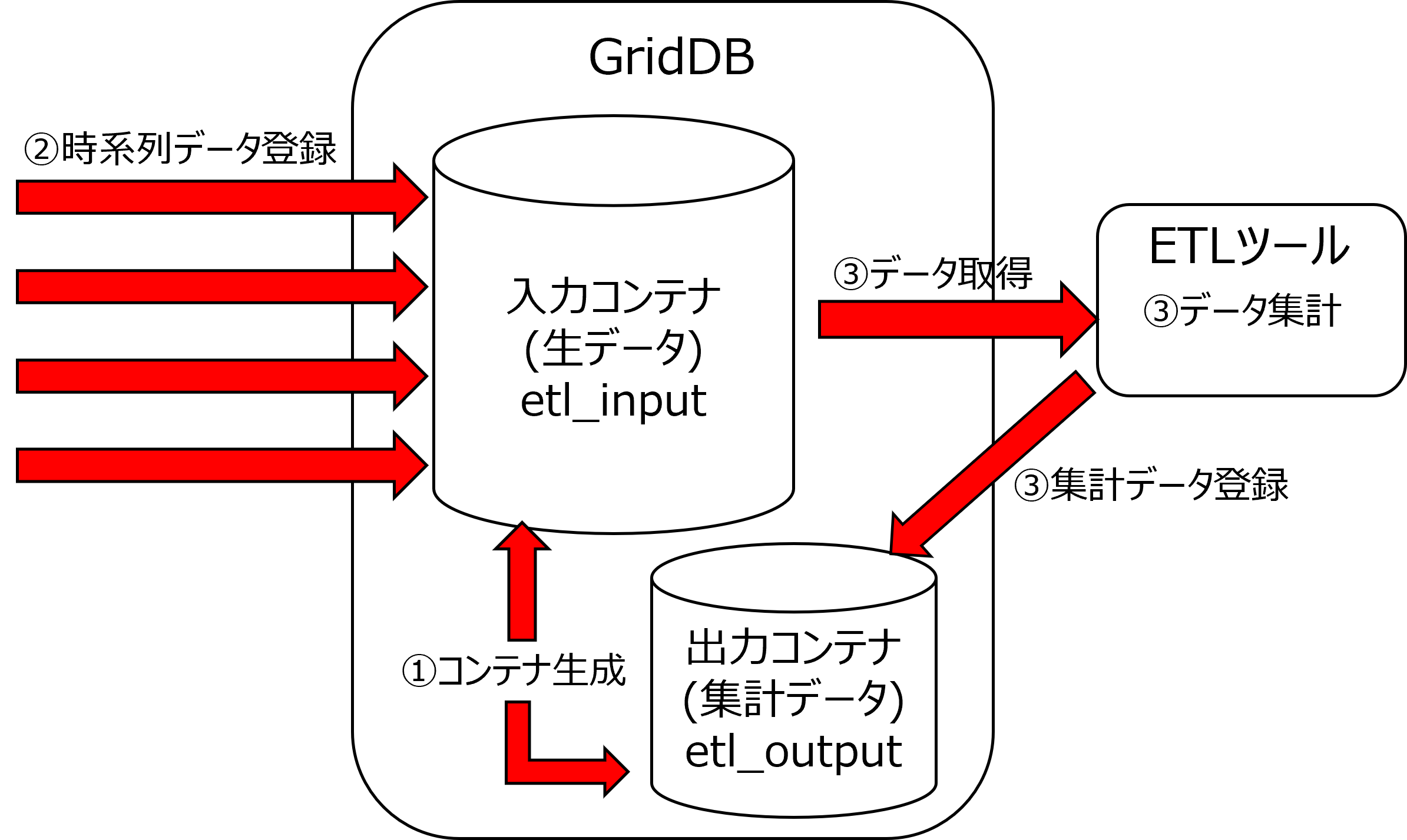
生データの登録先である入力コンテナをetl_input、集計データの登録先である出力コンテナをetl_outputとします。
①コンテナ生成
入力コンテナを作成します。
CREATE TABLE etl_input (
ts TIMESTAMP PRIMARY KEY,
value DOUBLE
) PARTITION BY RANGE (ts) EVERY (30, DAY);
一定期間でデータを自動削除する場合はGridDBの期限解放を設定します。入力コンテナに期限解放を設定します。
CREATE TABLE etl_input (
ts TIMESTAMP PRIMARY KEY,
value DOUBLE
) USING TIMESERIES WITH (
expiration_type='PARTITION',
expiration_time=90,
expiration_time_unit='DAY'
) PARTITION BY RANGE (ts) EVERY (30, DAY);
出力コンテナを作成します。
CREATE TABLE etl_output (
ts TIMESTAMP PRIMARY KEY,
value DOUBLE
) PARTITION BY RANGE (ts) EVERY (30, DAY);
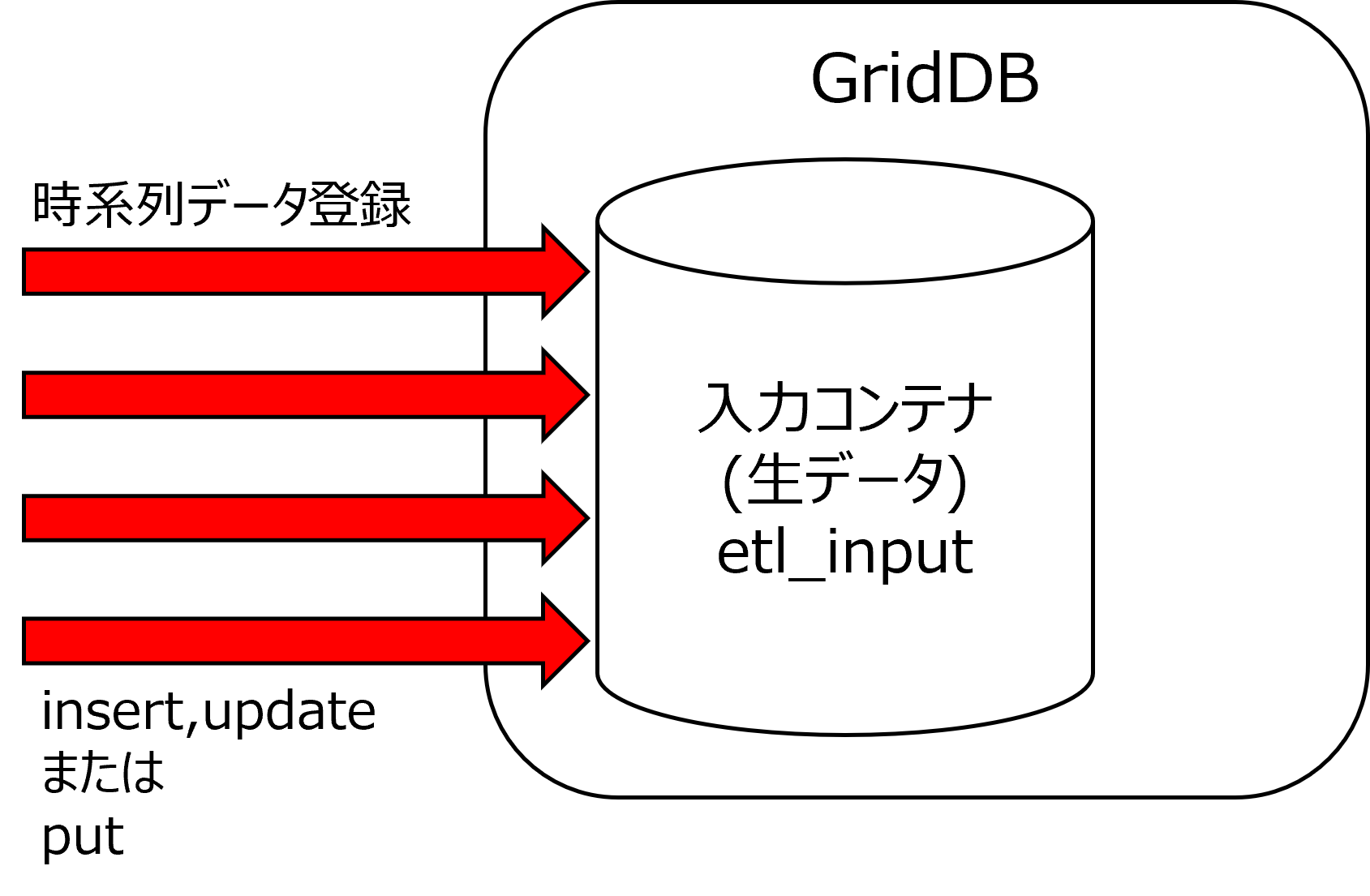
②時系列データ登録
集計対象のコンテナに時系列データを登録します。
③データ取得と集計、集計結果の登録
登録した時系列データを取得して集計を行います。
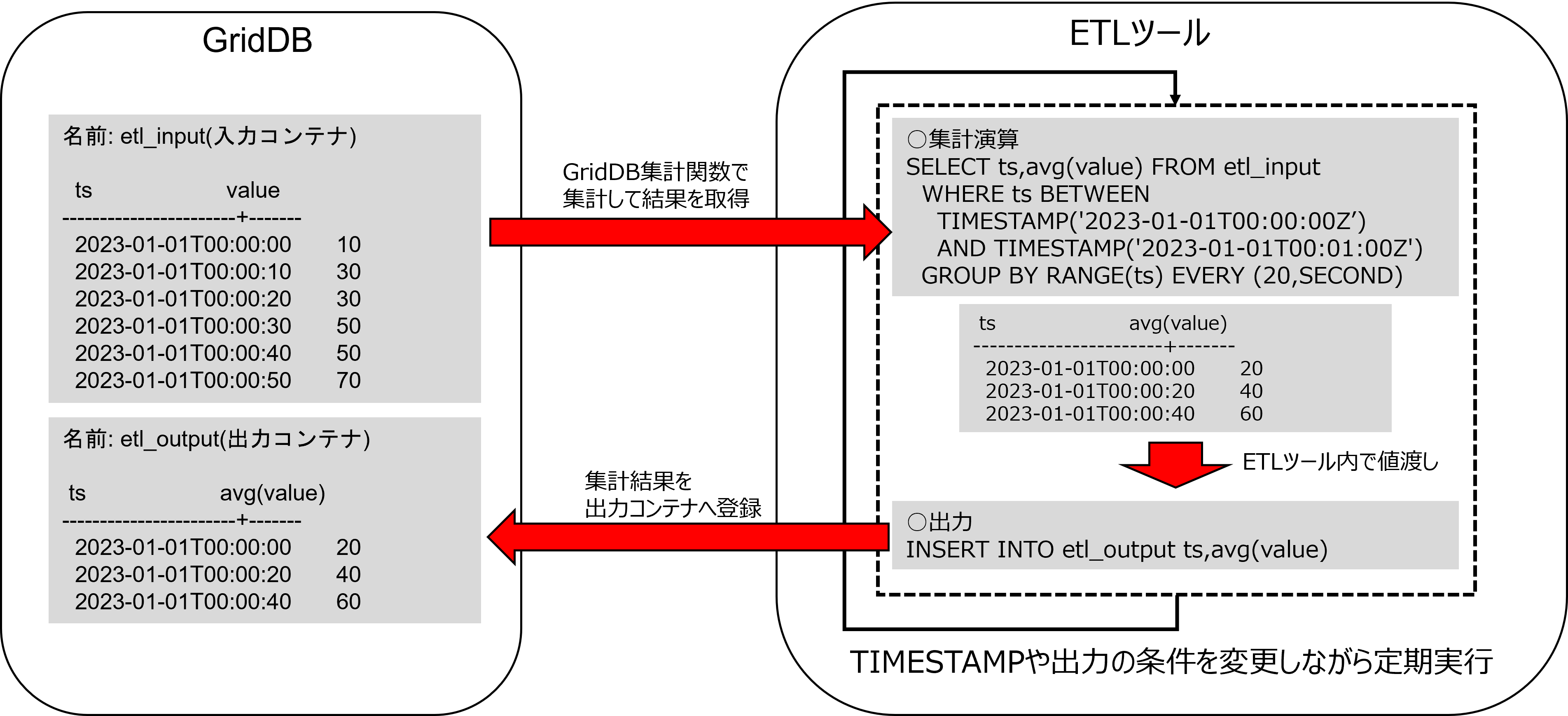
一定期間に対する集計を行う際は、GROUP BY RANGEと集計演算を組み合わせて、集計を行います。
例を以下に示します。
(1) 一定時間間隔の最大値を取得する例
名前: etl_input
ts value
-----------------------+-------
2023-01-01T00:00:00 10
2023-01-01T00:00:10 30
2023-01-01T00:00:20 30
2023-01-01T00:00:30 50
2023-01-01T00:00:40 50
2023-01-01T00:00:50 70
○集計演算
SELECT ts,max(value) FROM etl_input
WHERE ts BETWEEN TIMESTAMP('2023-01-01T00:00:00Z') AND TIMESTAMP('2023-01-01T00:01:00Z')
GROUP BY RANGE(ts) EVERY (20,SECOND)
ts value
-----------------------+-------
2023-01-01T00:00:00 30
2023-01-01T00:00:20 50
2023-01-01T00:00:40 70
(2) 一定時間間隔の最小値を取得する例
名前: etl_input
ts value
-----------------------+-------
2023-01-01T00:00:00 10
2023-01-01T00:00:10 30
2023-01-01T00:00:20 30
2023-01-01T00:00:30 50
2023-01-01T00:00:40 50
2023-01-01T00:00:50 70
○集計演算
SELECT ts,min(value) FROM etl_input
WHERE ts BETWEEN TIMESTAMP('2023-01-01T00:00:00Z') AND TIMESTAMP('2023-01-01T00:01:00Z')
GROUP BY RANGE(ts) EVERY (20,SECOND)
ts value
-----------------------+-------
2023-01-01T00:00:00 10
2023-01-01T00:00:20 30
2023-01-01T00:00:40 50
(3) 一定時間間隔の平均値を取得する例
名前: etl_input
ts value
-----------------------+-------
2023-01-01T00:00:00 10
2023-01-01T00:00:10 30
2023-01-01T00:00:20 30
2023-01-01T00:00:30 50
2023-01-01T00:00:40 50
2023-01-01T00:00:50 70
○集計演算
SELECT ts,avg(value) FROM etl_input
WHERE ts BETWEEN TIMESTAMP('2023-01-01T00:00:00Z') AND TIMESTAMP('2023-01-01T00:01:00Z')
GROUP BY RANGE(ts) EVERY (20,SECOND)
ts value
-----------------------+-------
2023-01-01T00:00:00 20
2023-01-01T00:00:20 40
2023-01-01T00:00:40 60
その他の集計関数は『GridDB SQLリファレンス』(GridDB_SQL_Reference.html)を参照してください。
集計した結果を出力コンテナに登録します。
INSERT INTO myTable1 ts,value;
上記のデータ取得と集計、集計結果の登録を定期的に実行することで、自動集計を実現します。
定期実行については、各ETLツール(ASTERIA Warp、Talend)で提供されている機能を利用します。
3 ASTERIA Warpについて
本項では、ASTERIA Warp Enterprise 5.0(以降、ASTERIA Warp)での集計方法について説明します。
ASTERIA Warpとは、アステリア株式会社が提供しているETLツールです。
指定したデータソースからデータウェアハウスを構築して、データの分析を行うツールで、専門的な知識がなくてもノーコードで設計開発を行い、様々なシステムやサービスと連携して、業務の自動化・効率化やデータの活用を実現するデータ連携ツールです。詳細はアステリア株式会社の公式ページを参照してください。
ASTERIA Warpを用いた集計処理はフローデザイナーとフローサービスで実現します。
- フローデザイナー
フローデザイナーは、データの抽出・変換・配信などの一連の処理手順をグラフィカルにあらわすフローを作成・保存・実行するGUIベースの統合設計環境ツールです。フローデザイナーでフローを作成し、フローサービスに登録して、実行するというのが基本的な設計手順になります。
ASTERIA Warpではこのフローと呼ばれる全体の処理を作成して、集計処理を実現します。
- フローサービス
フローサービスは、フローデザイナーで作成したフローを実行するプラットフォームです。フローデザイナーで作成したフローはフローサービスに保存・登録され、外部からのトリガーまたは設定したスケジュールによって起動・実行されます。
作成したフローをこのフローサービスで操作して、スケジュール実行・定期実行を設定します。
4 ASTERIA Warpを用いたGridDBの集計手順
ASTERIA Warpを用いたGridDBの集計手順について説明します。
ASTERIA Warp用いたGridDBの集計手順では、GridDBのコンテナ、JDBCドライバとASTERIA Warpの各コンポーネントを用います。
ASTERIA WarpとGridDBをそれぞれ準備します。
以下の流れで自動集計を行います。
- 環境構築
- フローサービスとフローデザイナーの接続
- GridDB JDBCドライバのインポートとコネクション作成
- フロー作成
- コンポーネント作成と配置
- フローサービスでスケジュール設定
4.1 環境構築
フローサービスとフローデザイナーをインストールします。
インストール方法はASTERIA Warpインストール手順を参照してください。
4.2 フローサービスとフローデザイナーの接続
フローサービスとフローデザイナーをそれぞれ起動します。
フローデザイナーの画面を開きます。
「ファイル」「サーバを追加」を選択して、「ログイン」画面を開きます。
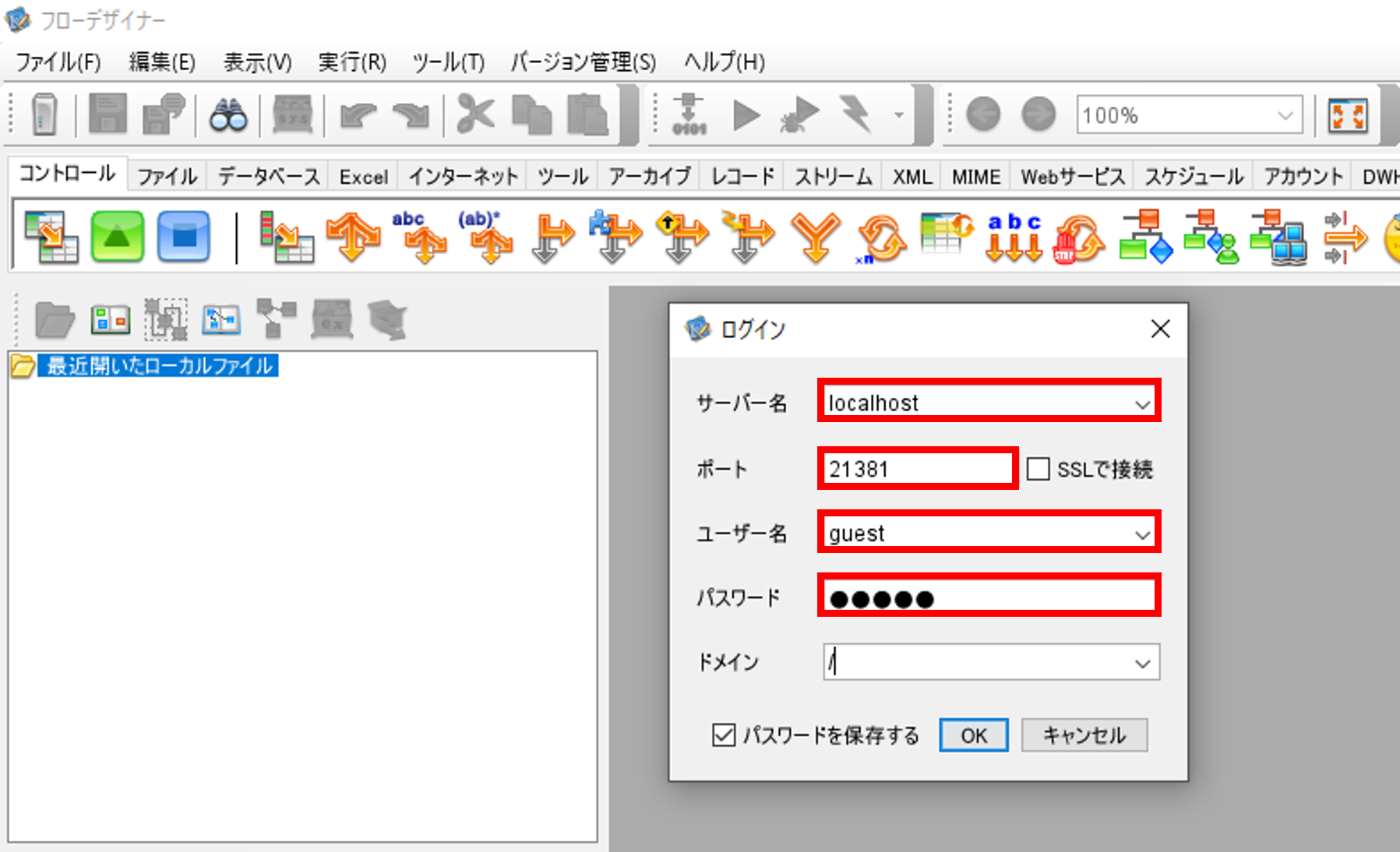
「サーバー名」に接続先のフローサービスのIPもしくはホスト名、「ポート」にフローサービスのポート番号を入力します。
「ユーザ名」「パスワード」にインストールの際に作成したユーザのユーザとパスワードを入力します。
4.3 GridDBドライバのインポートとコネクション作成
フローデザイナーを開いて、GridDBのJDBCドライバをASTERIA Warpの環境にインポートします。
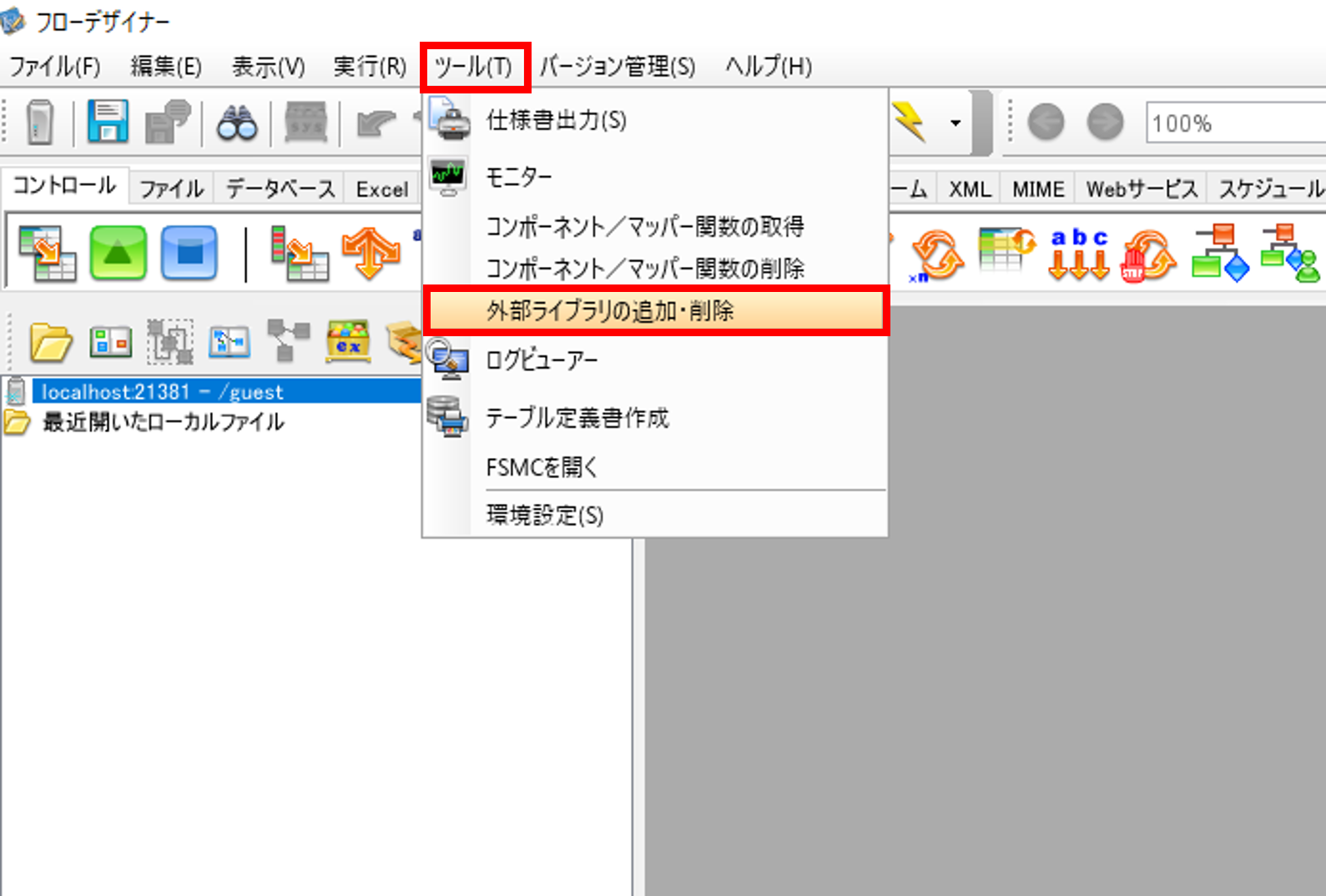
「ツール」から「外部ライブラリの追加・削除」を選択します。
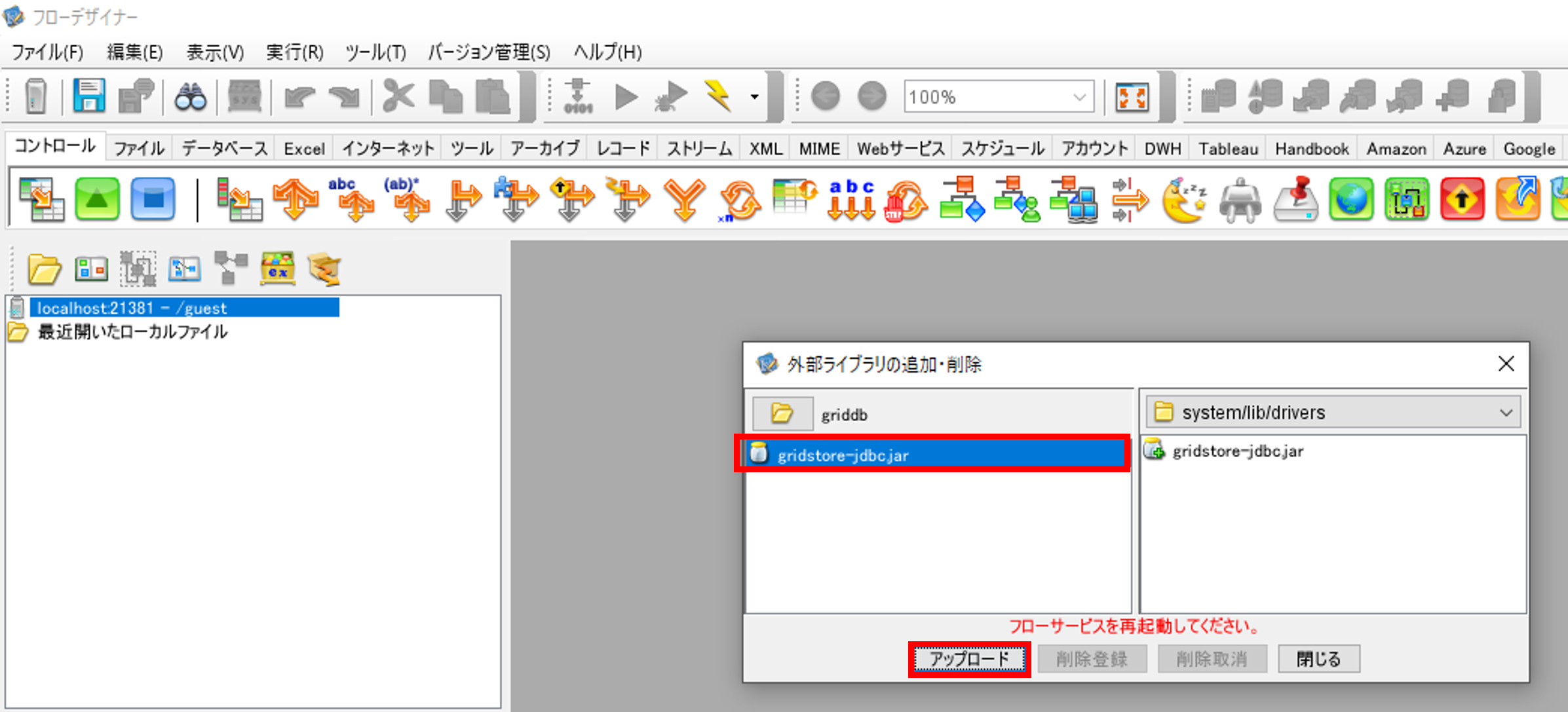
GridDBのJDBCドライバ(griddb-jdbc.jar)を選択して、「アップロード」を押して、外部ライブラリに追加します。一旦、フローデザイナーを閉じます。

フローサービスを停止します。

フローサービスを再度起動します。

フローサービスにログインして画面を開きます。
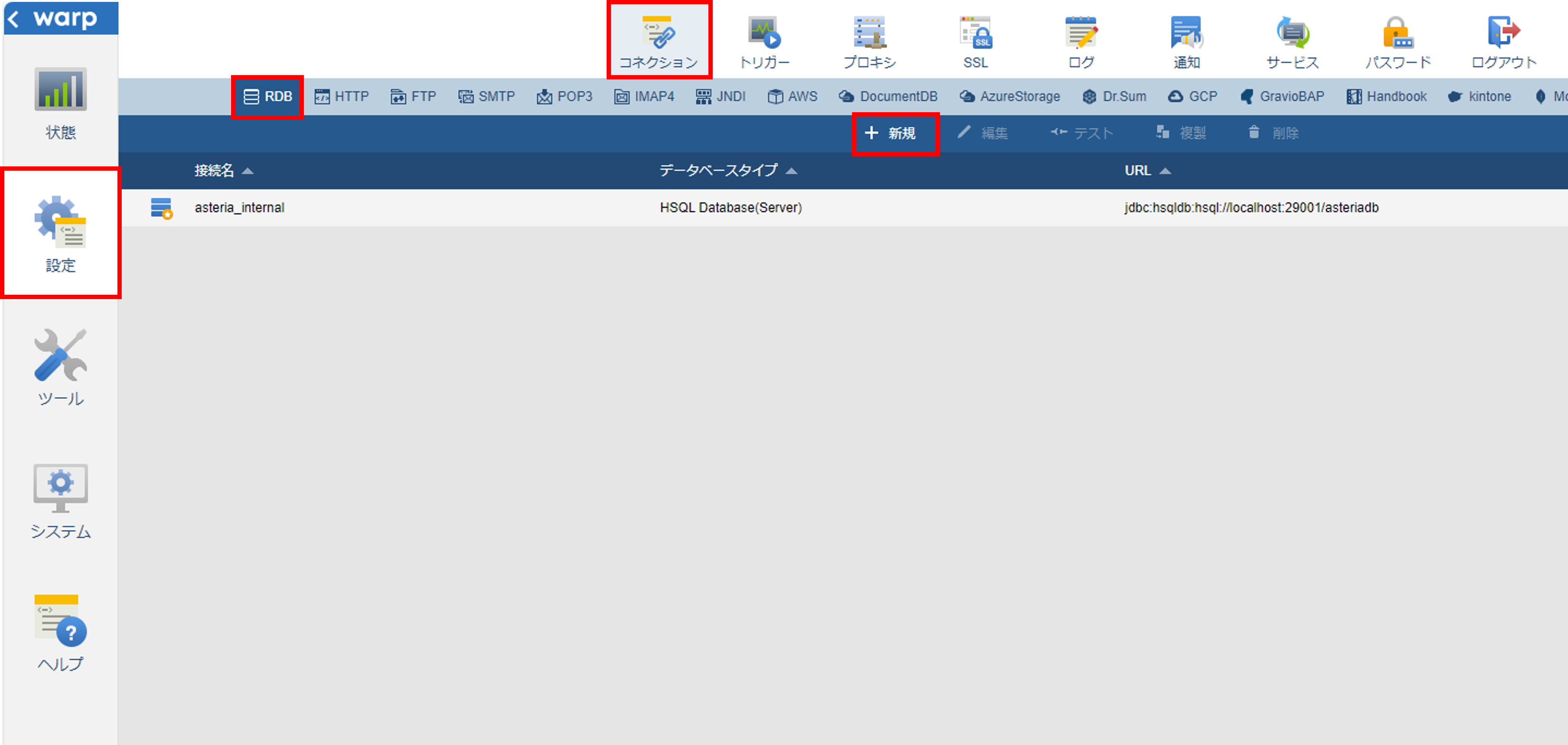
フローサービス画面で「設定」「コネクション」「RDB」を選択して、コネクションの一覧画面を開きます。
「+新規」を選択して、「新規」画面を開きます。
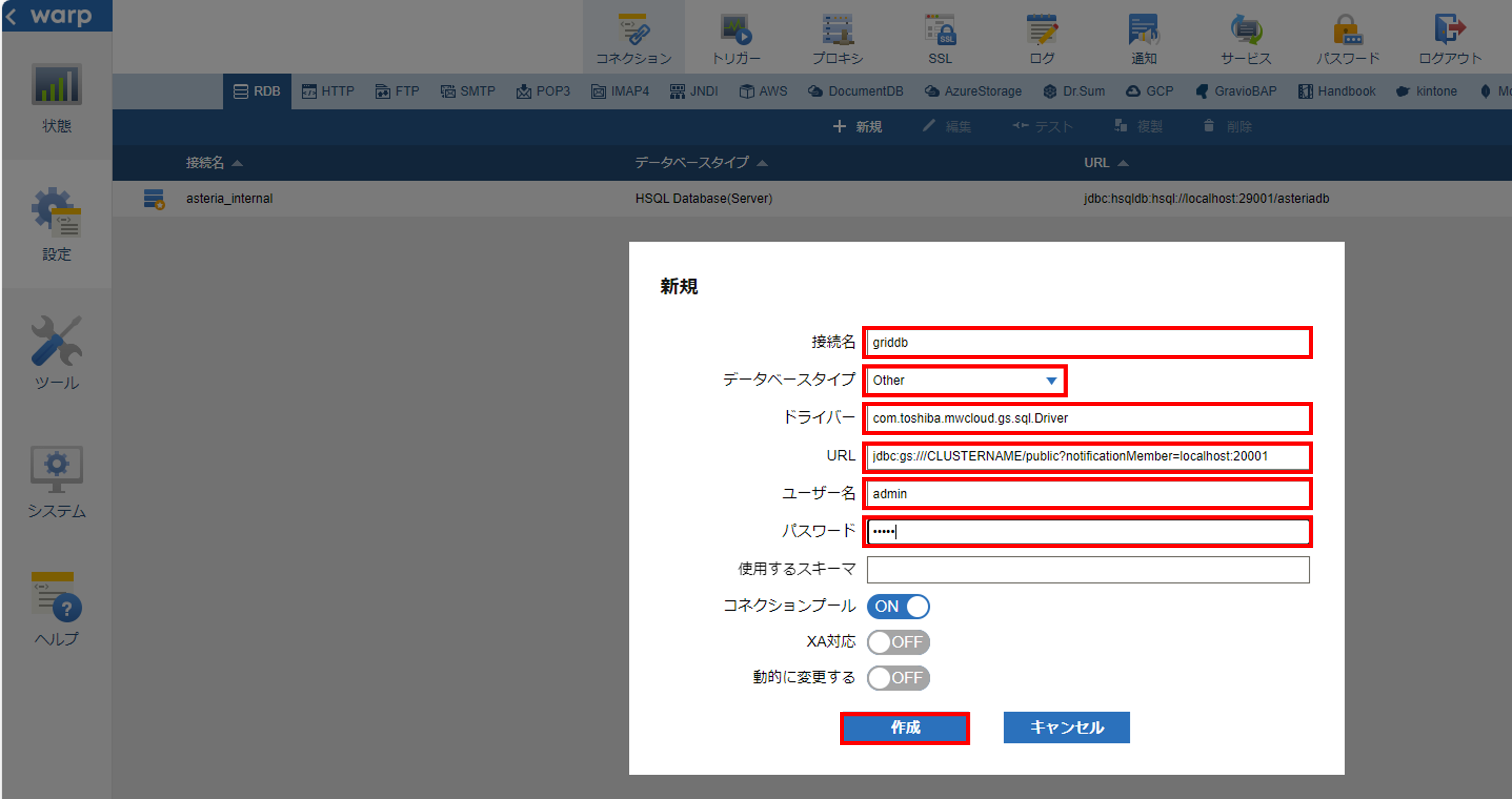
「接続名」に接続名を入力して、「データベースタイプ」に「Other」を選択します。「ドライバ」に「com.toshiba.mwcloud.gs.sql.Driver」と入力します。「URL」に接続対象のGridDBのJDBCのURLを入力します。
GridDBのJDBC URLの設定は『GridDB JDBCドライバ説明書』(GridDB_JDBC_Driver_UserGuide.html) を参照してください。
本ガイドでは固定リスト方式のGridDBクラスタに接続する場合のJDBC URLについて記載します。その他の接続方式については『GridDB JDBCドライバ説明書』をご確認ください。
固定リスト方式の場合、以下のようなJDBC URLを設定します。
jdbc:gs:///(clusterName)/(databaseName)?notificationMember=(notificationMember)
clusterName:GridDBクラスタのクラスタ名
databaseName:データベース名。省略した場合はデフォルトデータベース(public)に接続します。
notificationMember:ノードのアドレスリスト(URLエンコードが必要)。デフォルトポートは20001
例:jdbc:gs:///CLUSTERNAME/public?notificationMember=192.168.0.10:20001,192.168.0.11:20001,192.168.0.12:20001
「ユーザ名」と「パスワード」にそれぞれGridDBの接続ユーザ名とパスワードを入力します。「作成」を押してコネクションを作成して、コネクションの一覧画面に作成したコネクションを追加されます。
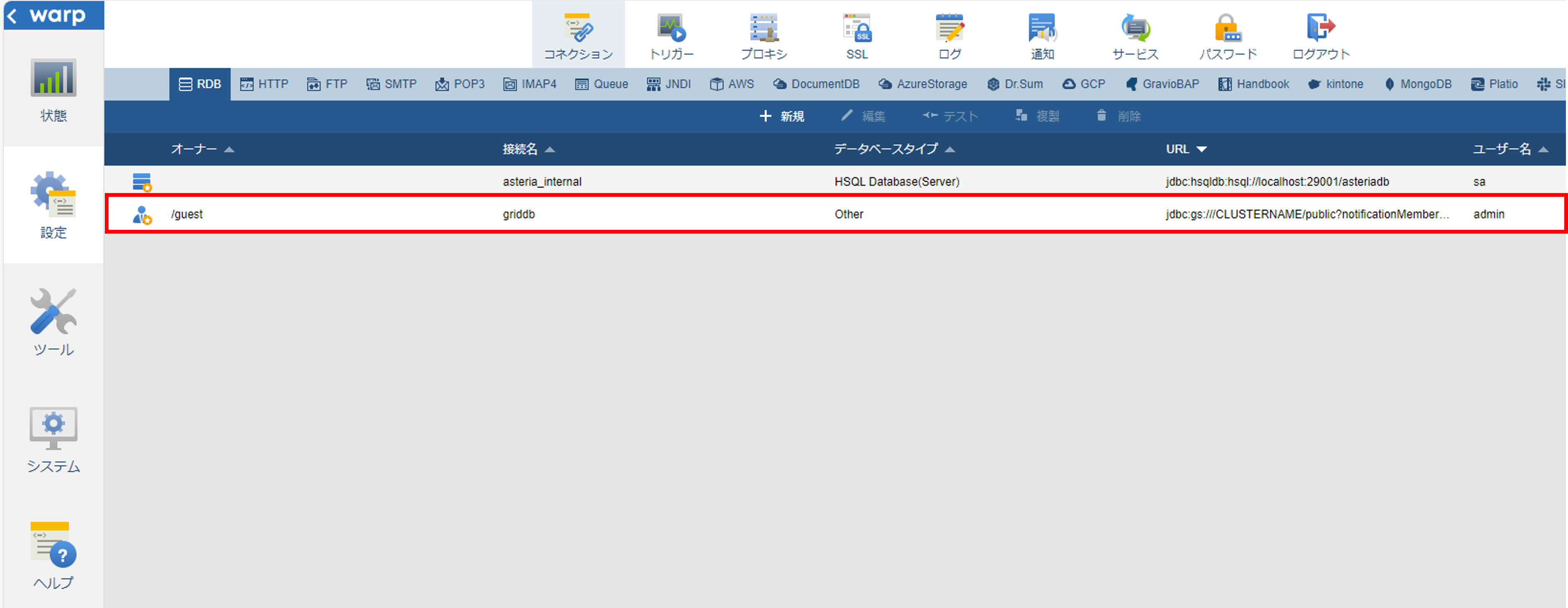
フローサービスの操作は以上で完了です。
4.4 ASTERIA Warp フロー作成
ASTERIA Warpではフローを作成して、集計処理を実現します。このフローの中でコンポーネントと呼ばれる機能を配置します。フローはフローデザイナーで作成します。
フローデザイナーを開きます。フローサービスと再度接続を行って、「コネクション」が追加されていることを確認します。
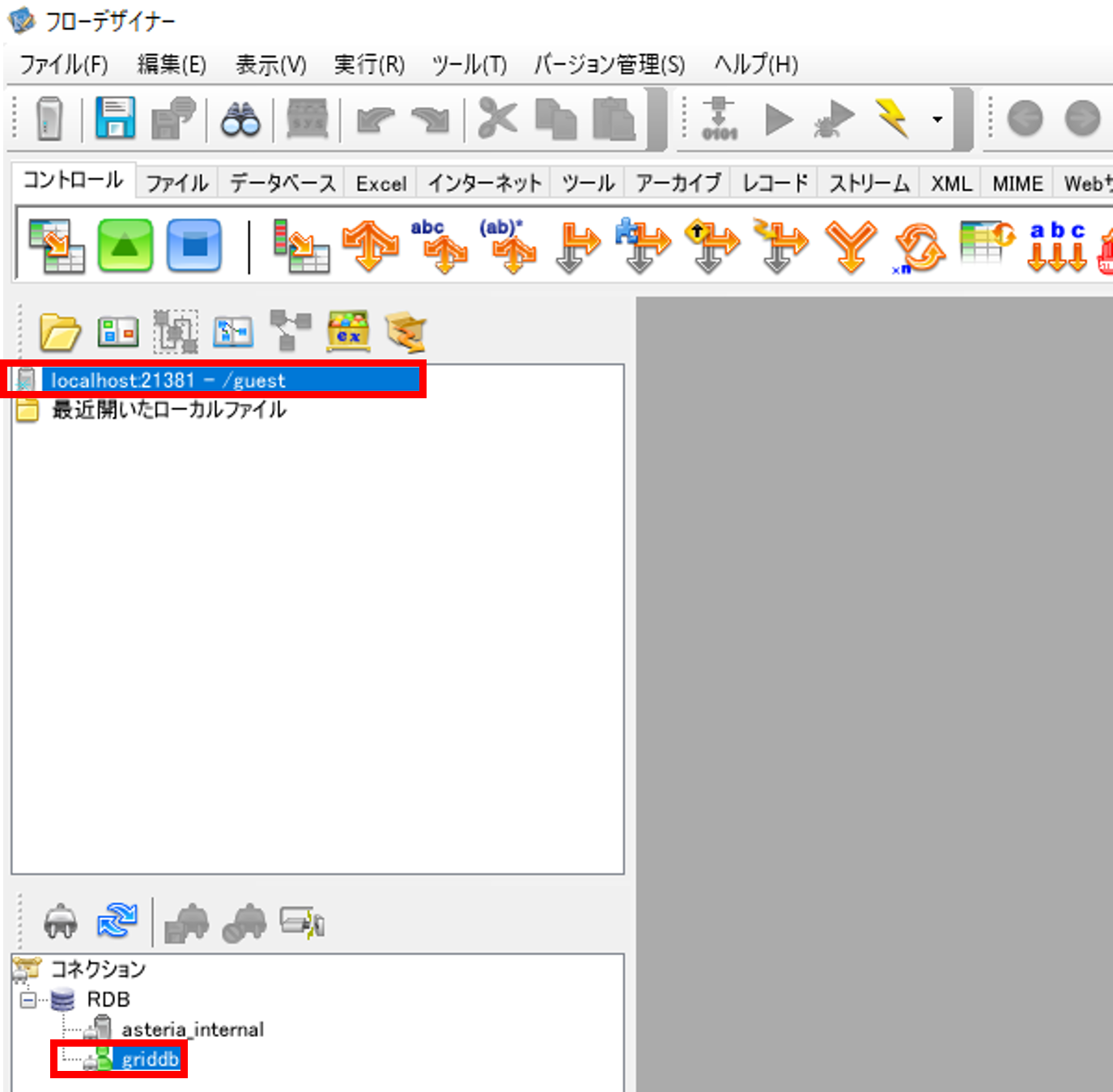
フローサービスとフローデザイナーサーバーの接続で作成したサーバーで右クリックをして、「フォルダの作成」を選択して、「フォルダの作成」画面でフォルダを作成します。
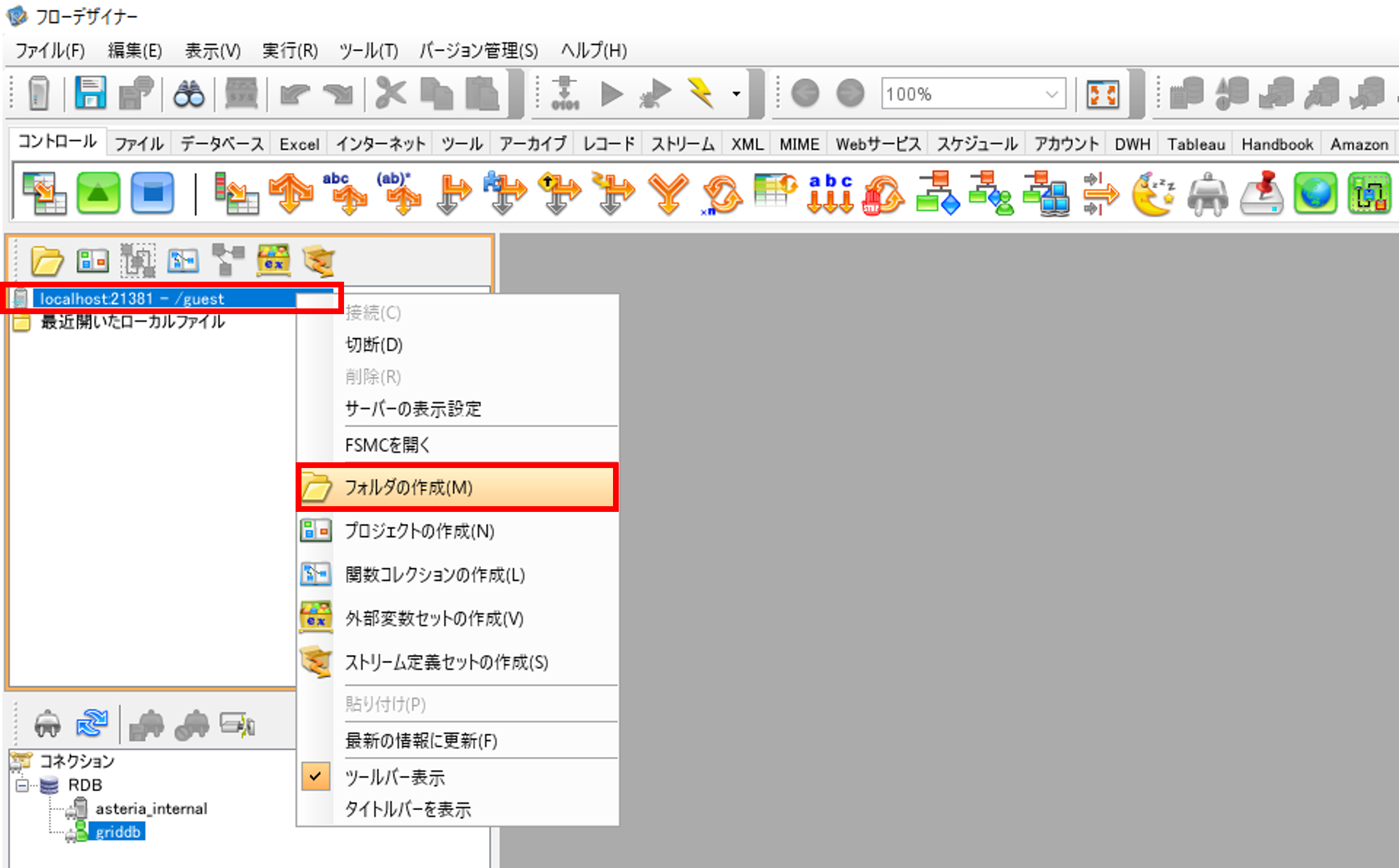
作成したフォルダで右クリックをして、「プロジェクトの作成」を選択して、「プロジェクトの作成」画面でプロジェクトとフローを作成します。
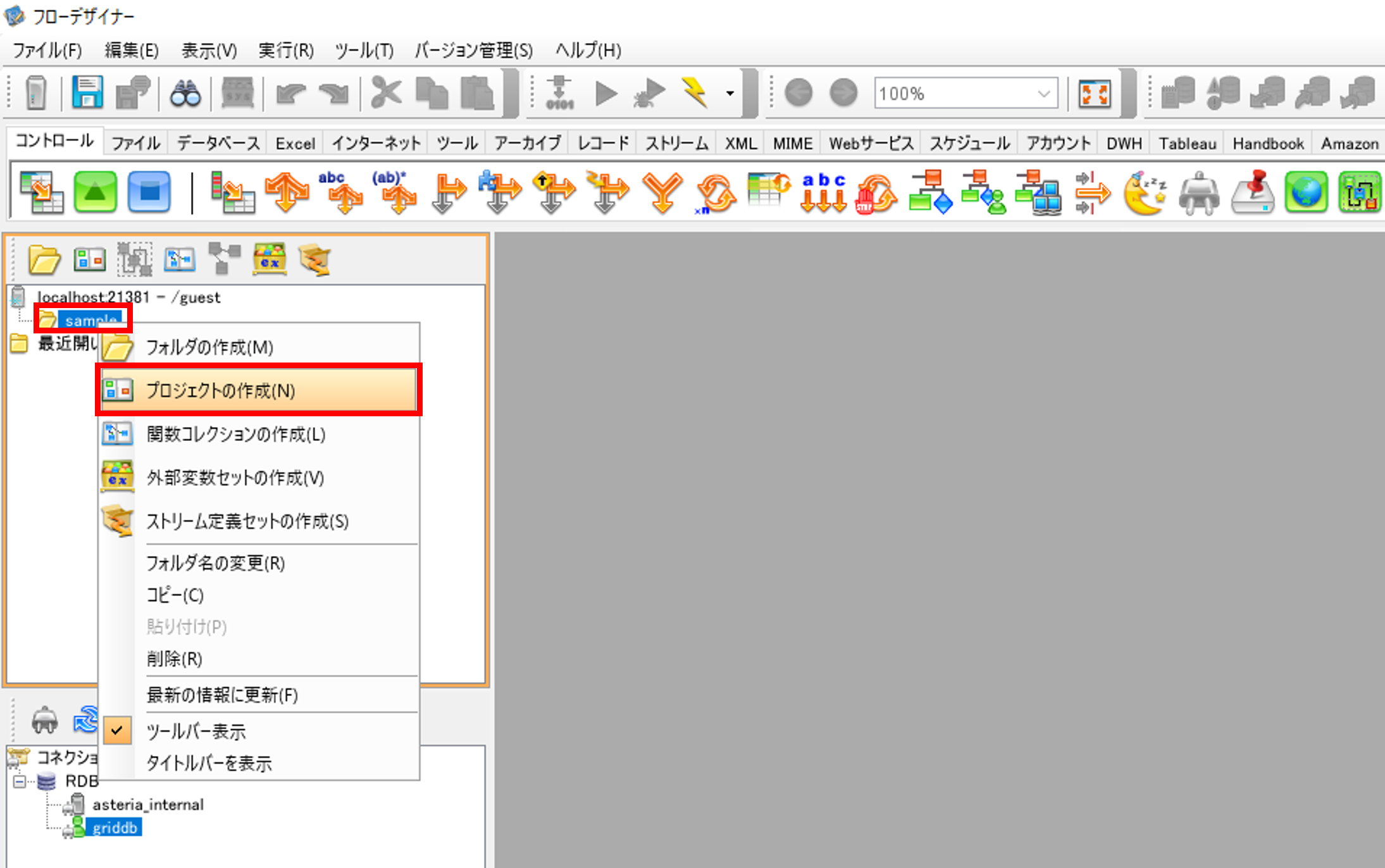
プロジェクトの作成の際に最初のフローを作成するため、合わせて新規フローも作成します。
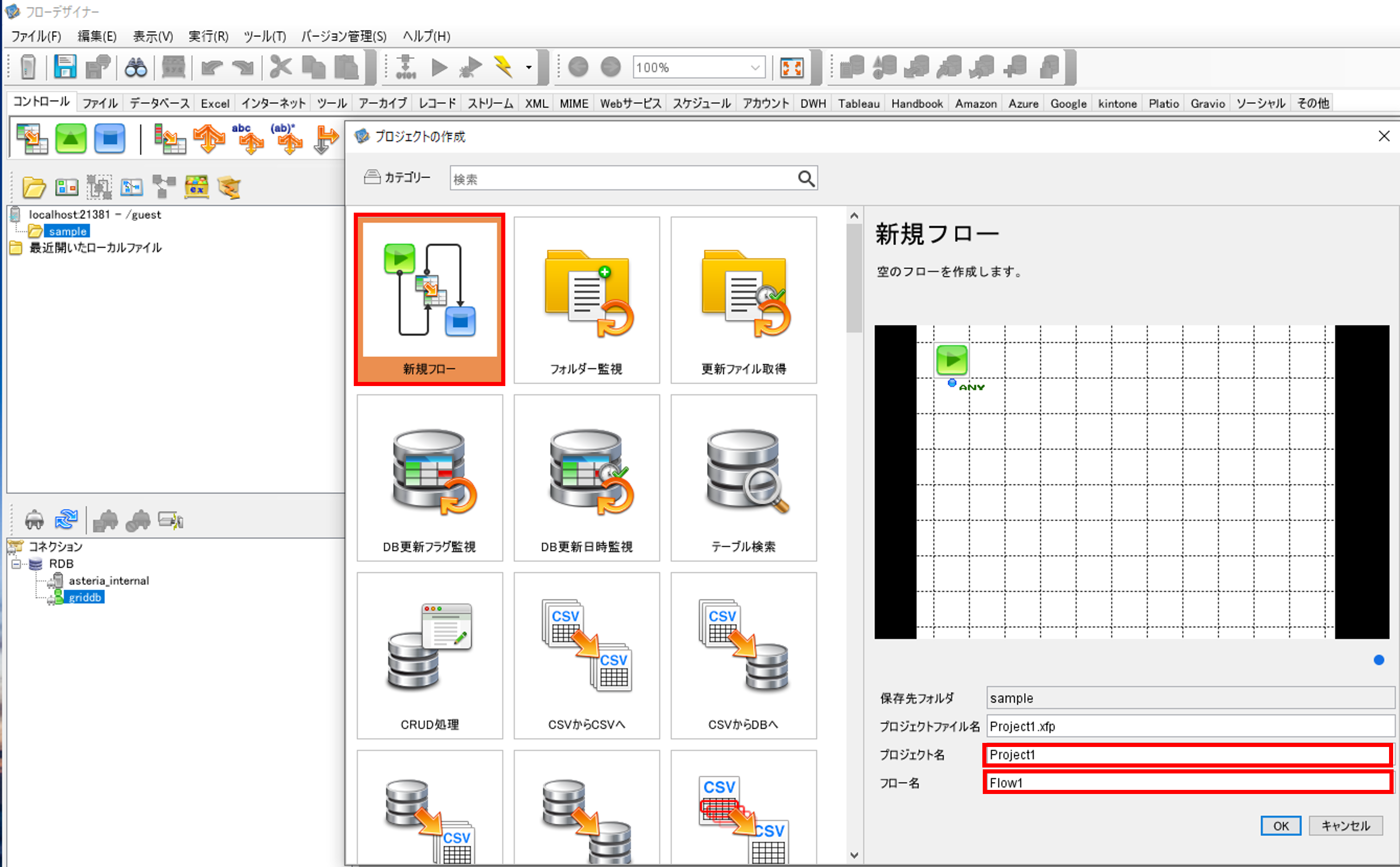
「新規フロー」を選択して、「プロジェクト名」と「フロー名」を入力して、プロジェクトとフローを作成します。
4.5 ASTERIA Warp コンポーネント作成と配置
以下の各コンポーネントを配置して、フローを作成します。
| コンポーネント名 | コンポーネントの説明 | コンポーネントのイメージ |
|---|---|---|
| Start | フローを開始します |  |
| End | フローを終了します |  |
| Mapper | データをマッピングします |  |
| RDBGet | RDBからデータを取得します |  |
| RDBPut | RDBへデータを挿入、またはデータの更新、削除をします |  |
| BranchStart | 条件で分岐します |  |
| SQLCall | SQL文を実行します |  |
集計方法として、GridDBからの取得とGridDBへの出力を一つのコンポーネントで実施する方法と GridDBからの取得とGridDBへの出力を別のコンポーネントで実施する方法があります。それぞれのフローについて説明します。
RDBGetコンポーネント、RDBPutコンポーネント、SQLCallコンポーネントなどDBとの接続をするコンポーネントをクリックした際に、「コネクション」画面が開きます。
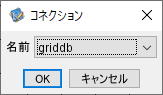
「名前」からGridDBドライバのインポートとコネクション作成で作成したコネクションを選択して、GridDBと接続します。
4.5.1 GridDBからの取得とGridDBへの出力のコンポーネントを一つにしたフロー
GridDBから集計結果を取得して、そのデータそのままGridDBへデータの挿入または更新するフローを説明します。
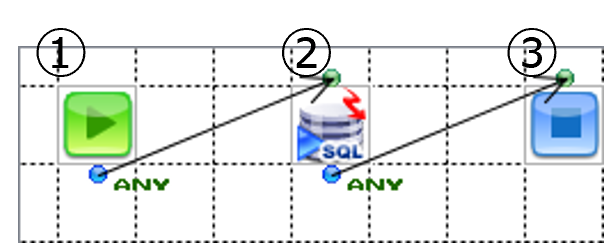
①フローの開始
フローを開始します。Startコンポーネントはデフォルトで配置されます。
②GridDBから集計結果の取得して、GridDBへデータ挿入または更新
SQLCallコンポーネントを配置して、GridDBから集計結果の取得とGridDBへデータ挿入または更新をします。
SQLCallコンポーネントをクリックして、「SQL文プロパティの編集」画面を開きます。
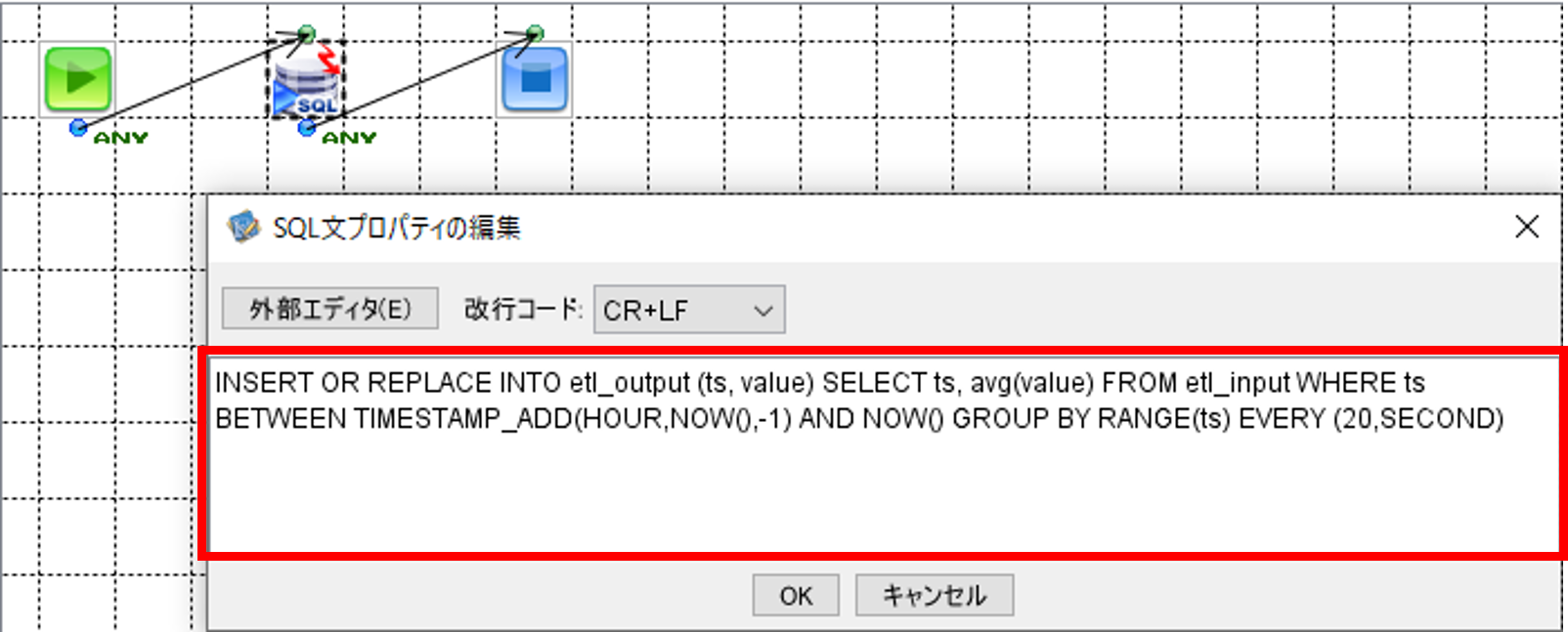
画面に以下のSQL文を記載します。
直近1時間のデータを20秒ごとに集計して平均値を求めて、出力先コンテナへ登録または更新します。
INSERT OR REPLACE INTO etl_output (ts, value)
SELECT ts, avg(value) FROM etl_input
WHERE ts BETWEEN TIMESTAMP_ADD(HOUR,NOW(),-1) AND NOW()
GROUP BY RANGE(ts) EVERY (20,SECOND)
記入が完了したら「OK」ボタンで「SQL文プロパティの編集」画面を閉じます。
③フローの終了
Endコンポーネントを配置して、フローを終了します。
必要に応じて、一度実行して動作確認を行います。
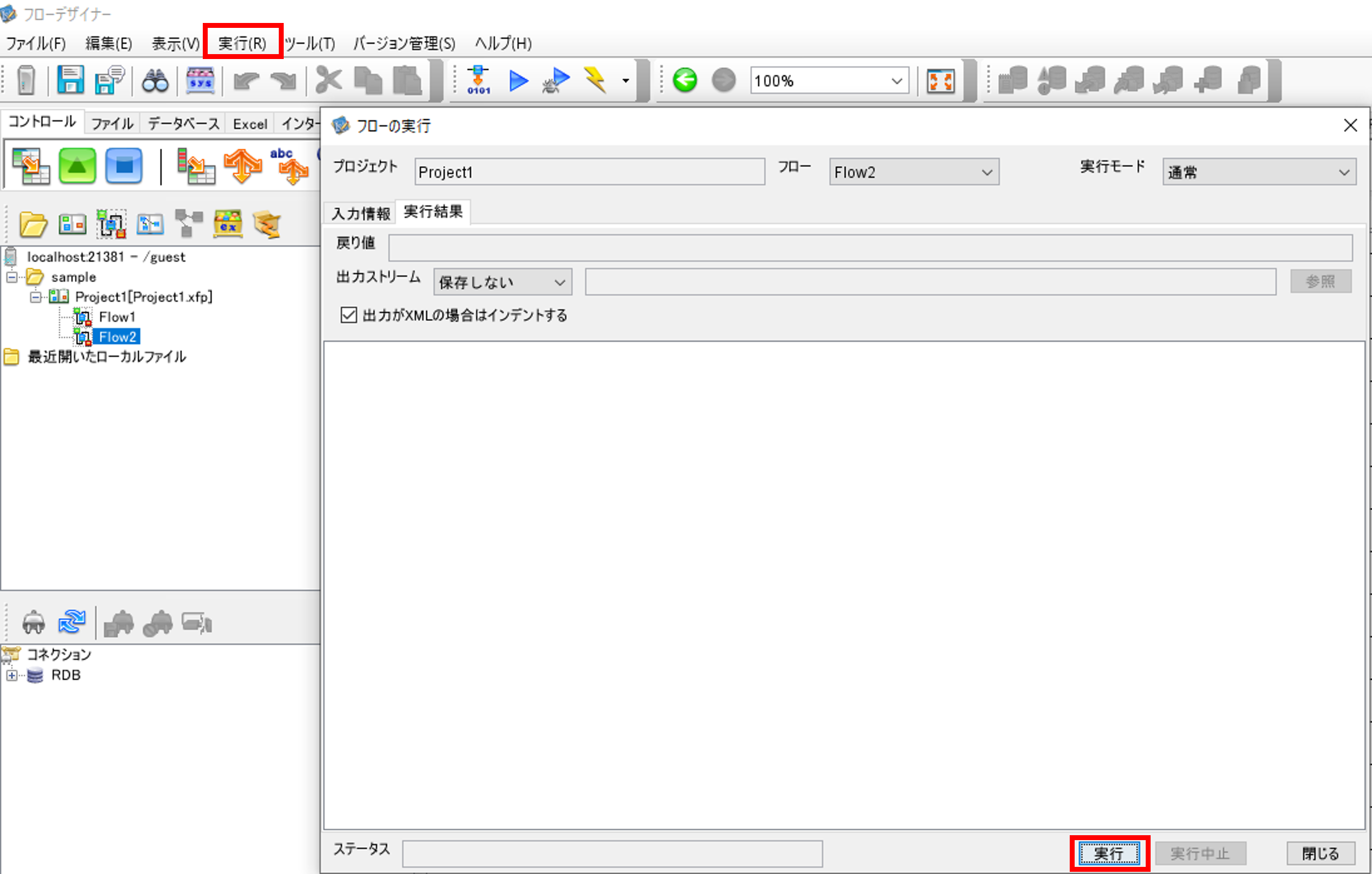
「実行」を選択して、「フローの実行」画面を開きます。「実行」ボタンを押して、実行を行います。
4.5.2 GridDBからの取得とGridDBへの出力のコンポーネントを分けたフロー

①フローの開始
フローを開始します。Startコンポーネントはデフォルトで配置されます。
②GridDBからデータ取得 前回集計の最終時刻の取得
RDBGetコンポーネントを配置して、GridDBから前回集計の最終時刻を取得します。
RDBGetコンポーネントをクリックして、「SQLビルダー」画面を開きます。
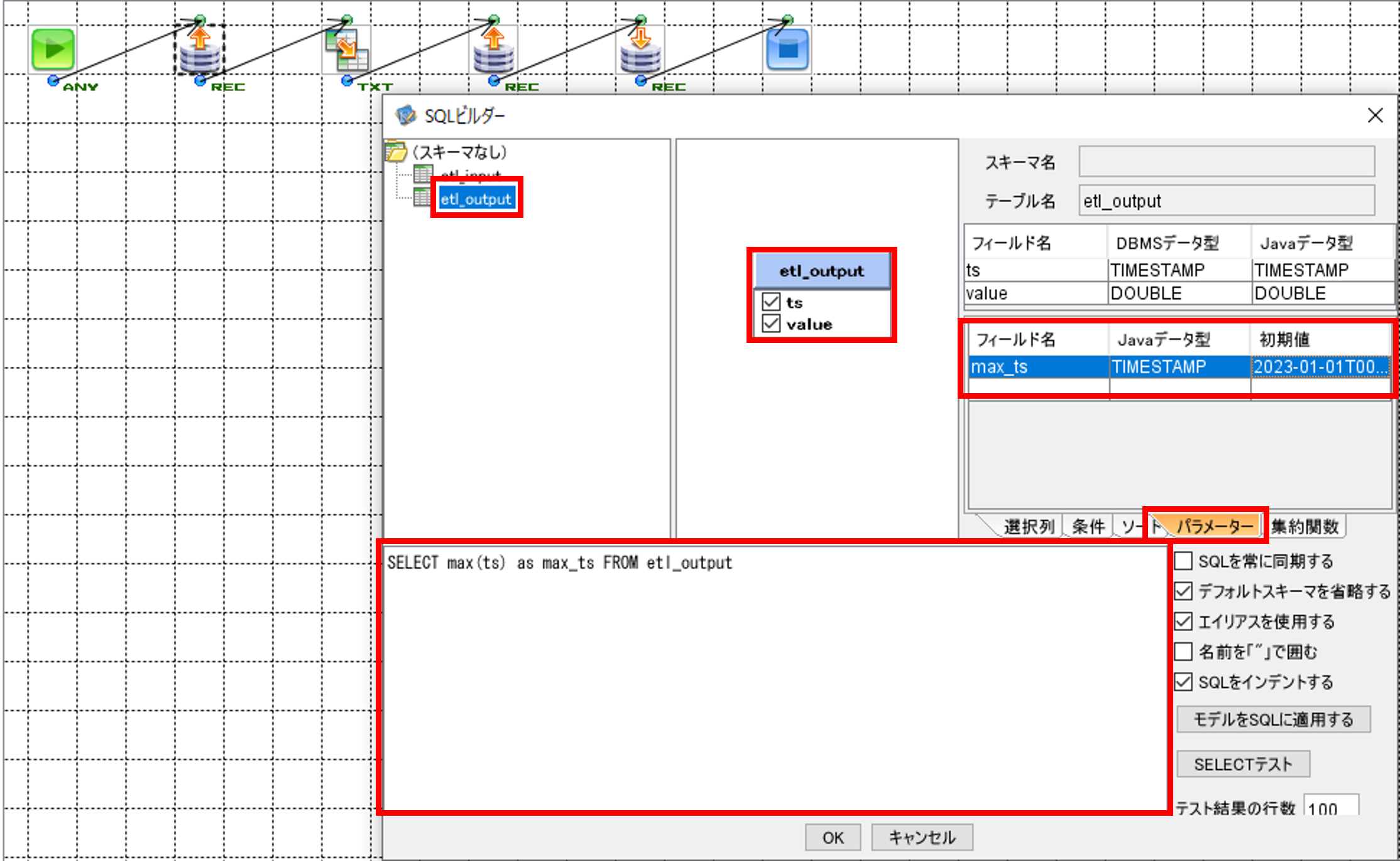
「SQLビルダー」画面の左上のテーブル一覧画面から、SQL実行対象である「etl_output」を選択して、中央上の画面にドラッグ&ドロップします。カラム名として表示されている「ts」と「value」にチェックを入れます。
右上の画面で「パラメーター」タブを選択して、「フィールド名」に「max_ts」、「Javaデータ型」に「TIMESTAMP」、「初期値」に「2023-01-01T00:00:00」と入力します。
下の画面に以下のSQL文を記載します。
前回集計の最終時刻を取得します。
SELECT max(ts) as max_ts FROM etl_output
記入が完了したら「OK」ボタンを押して「SQLビルダー」画面を閉じます。
「フィールド定義を更新しますか?」というメッセージが表示されるので、「はい」を押します。
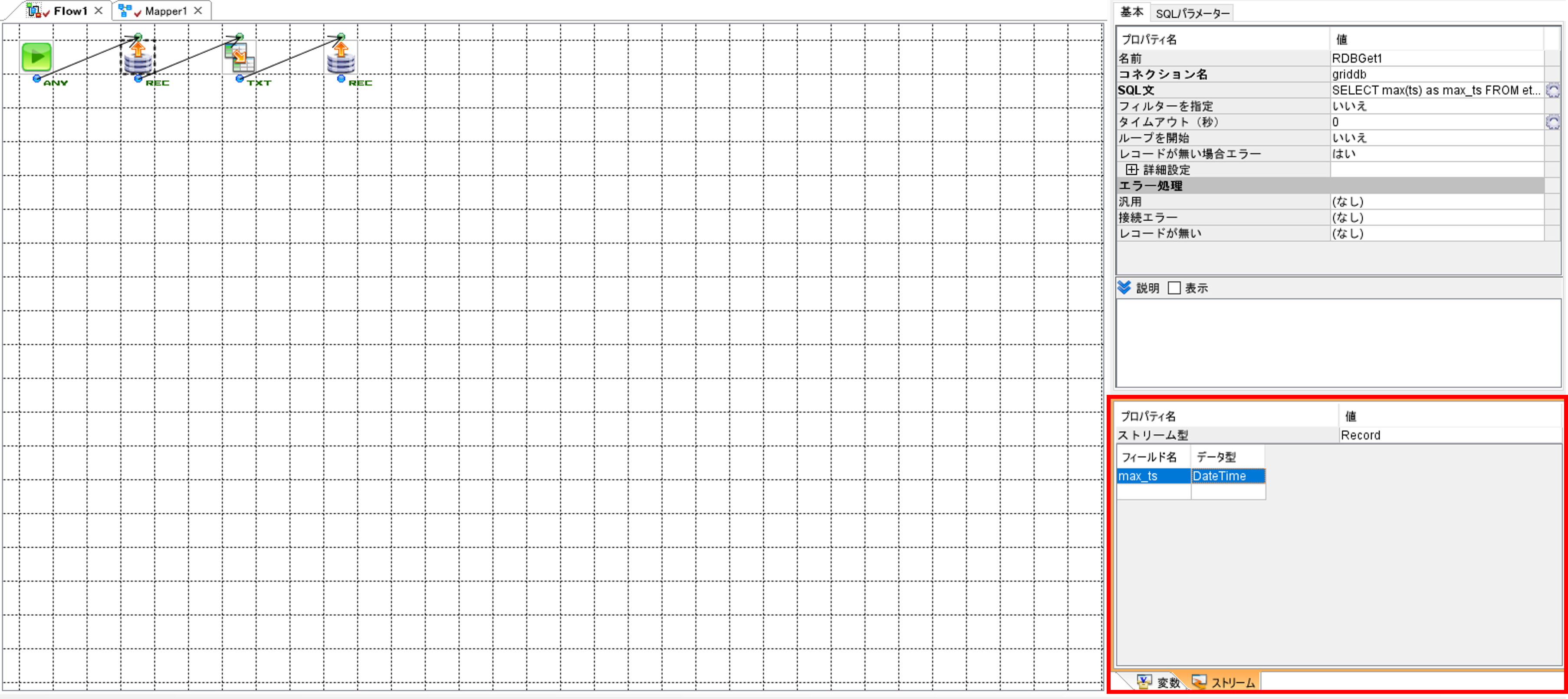
右下の「ストリーム」画面に「フィールド名」と「データ型」が表示されます。「データ型」に記載されているデータ型とGridDBのコンテナのデータ型が一致していない場合は、データ型を一致させてください。データのマッピングについてはGridDBとASTERIA Warpのデータ型のマッピングを参照してください。
③データのマッピング
Mapperコンポーネントを配置します。
Mapperコンポーネントの配置だけ実施して、先に④GridDBからデータ取得 集計結果の取得を実施します。
④GridDBからデータ取得 集計結果の取得
RDBGetコンポーネントを配置して、GridDBからデータを取得します。
RDBGetコンポーネントをクリックして、「SQLビルダー」画面を開きます。
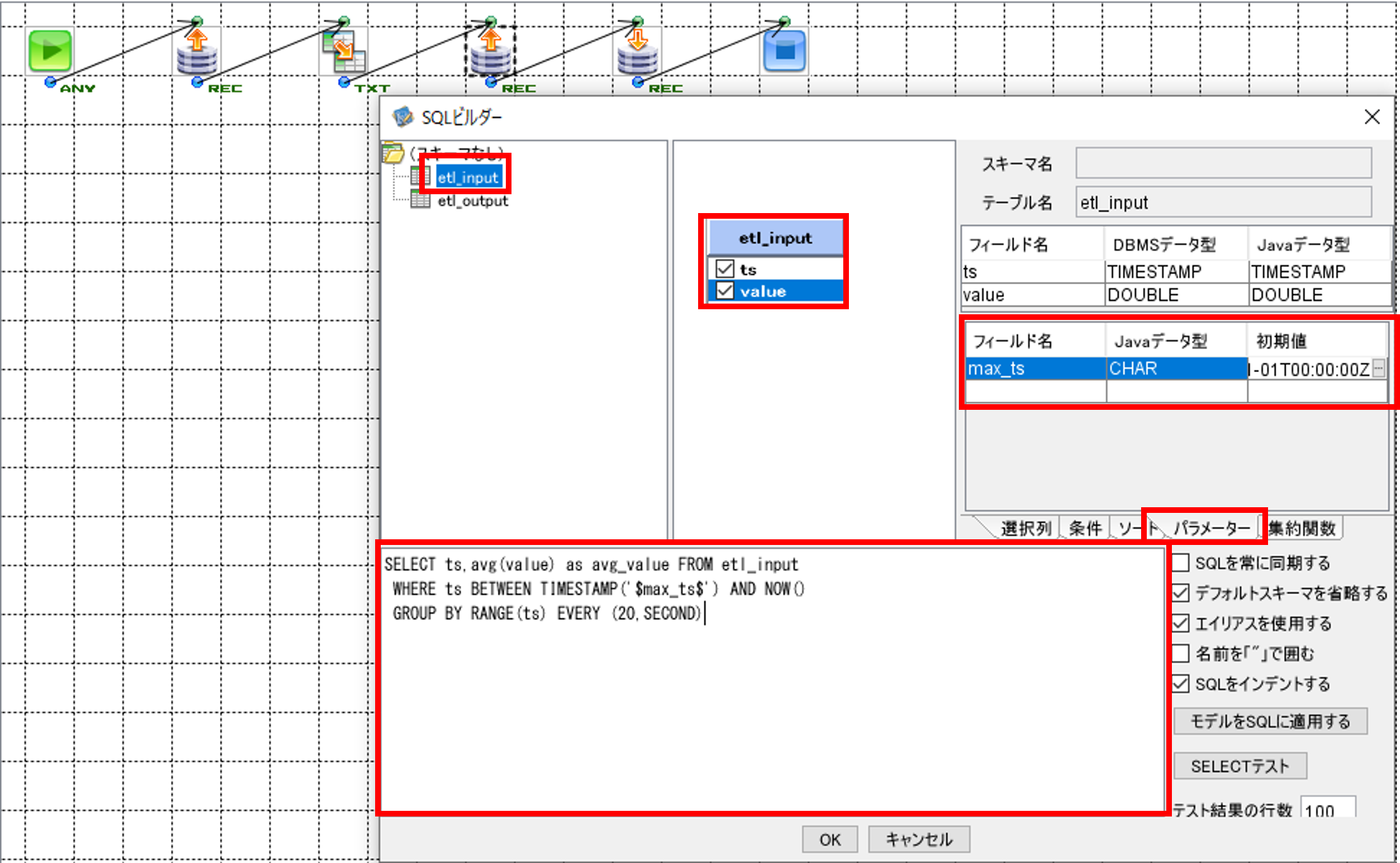
「SQLビルダー」画面の左上のテーブル一覧画面から、SQL実行対象である「etl_input」を選択して、中央上の画面にドラッグ&ドロップします。カラム名として表示されている「ts」と「value」にチェックを入れます。
右上の画面で「パラメーター」タブを選択して、「フィールド名」に「max_ts」、「Javaデータ型」に「CHAR」、「初期値」に「2023-01-01T00:00:00Z」と入力します。
下の画面に以下のSQL文を記載します。
前回集計の最終時刻から現在時刻の間のデータを20秒ごとに集計して平均値を取得します。
SELECT ts,avg(value) as avg_value FROM etl_input
WHERE ts BETWEEN TIMESTAMP('$max_ts$') AND NOW()
GROUP BY RANGE(ts) EVERY (20,SECOND)
記入が完了したら「OK」ボタンで「SQLビルダー」画面を閉じます。
「フィールド定義を更新しますか?」というメッセージが表示されるので、「はい」を押します。
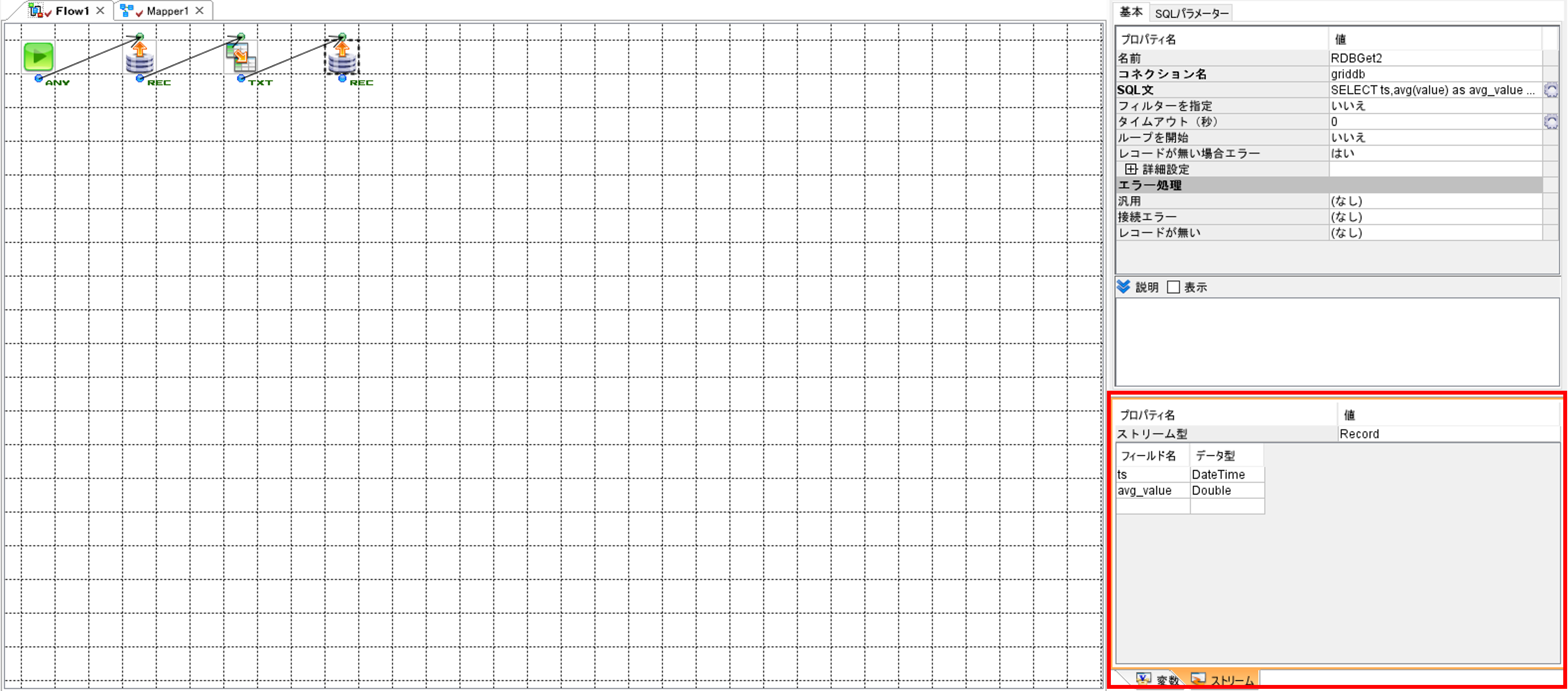
右下の「ストリーム」画面の「データ型」に記載されているデータ型とGridDBのコンテナのデータ型が一致していない場合は、データ型を一致させてください。
⑤データのマッピング
③データのマッピングで配置したMapperコンポーネントを使って、変数にデータをマッピングします。
Mapperコンポーネントをクリックして、Mapperの画面を開きます。
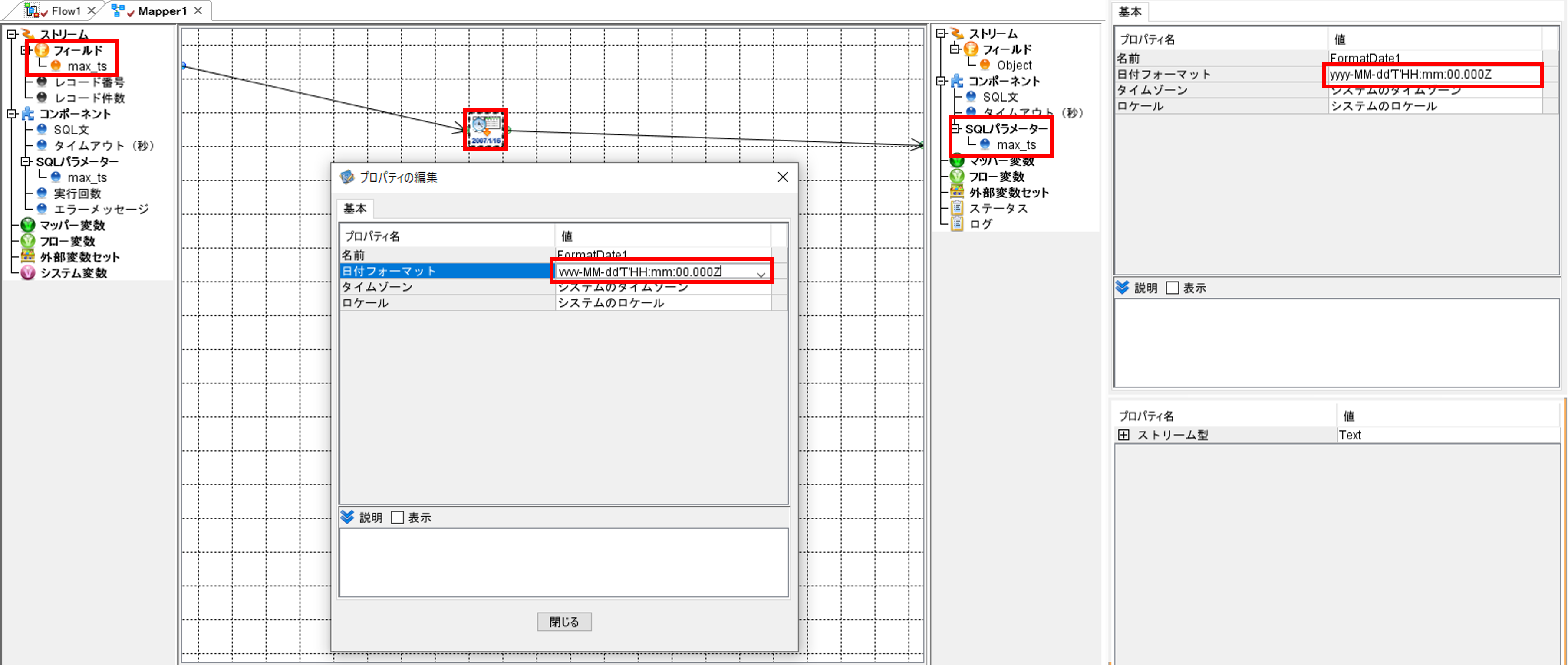
「日付」タブから「日時データから文字列に変換」コンポーネントを選択して、配置します。
「日時データから文字列に変換」コンポーネントをクリックして、「プロパティの編集」画面を開きます。
「日付フォーマット」に「yyyy-MM-dd'T'HH:mm:00.000Z」と入力します。
「日時データから文字列に変換」コンポーネントと「フィールド/max_ts」、「コンポーネント/SQLパラメーター/max_ts」を矢印でつなぎます。
⑥GridDBへデータ挿入または更新、削除
RDBPutコンポーネントを配置して、GridDBへデータを登録します。
RDBPutコンポーネントをクリックして、「テーブルとフィールドの設定」画面を開きます。
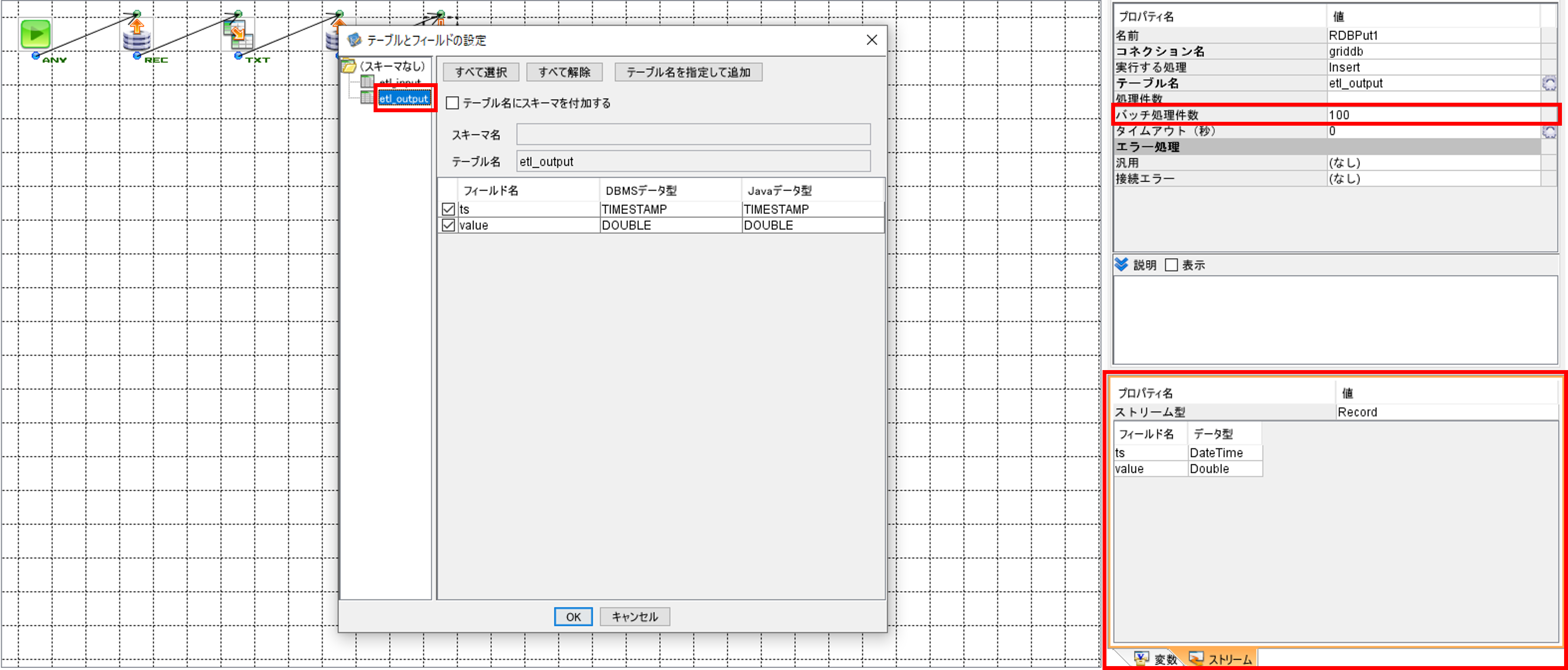
「SQLビルダー」画面の左のテーブル一覧画面から、SQL実行対象である「etl_output」を選択します。右下の「ストリーム」画面の「データ型」に記載されているデータ型とGridDBのコンテナのデータ型が一致していない場合は、データ型を一致させてください。
バッチ更新を使用する場合は「バッチ処理件数」を指定します。
⑦フローの終了
Endコンポーネントを配置して、フローを終了します。
必要に応じて、一度実行して動作確認を行います。
「実行」を選択して、「フローの実行」画面を開きます。「実行」ボタンを押して、実行を行います。
出力先の「etl_output」にデータが登録されていないために実行でエラーが発生する場合は、以下のSQLで出力先のコンテナにデータを登録して、再度実行を行います。
現在時刻のデータを1件登録します。
insert into etl_output values (NOW(),NULL)
4.6 ASTERIA Warp フローサービスでスケジュール実行する
フローサービスで定期実行のスケジュールを設定します。
asuユーザでログインして、フローサービス画面を開きます。
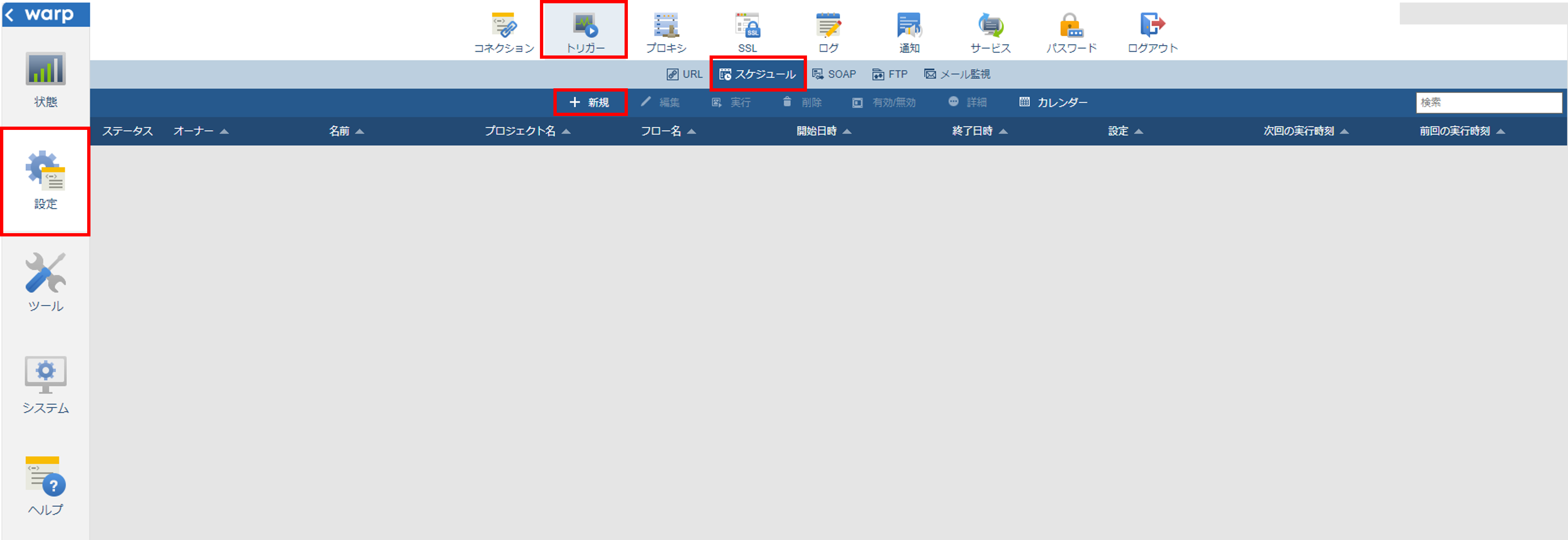
左のタブから「設定」を選択して、「トリガー」「スケジュール」を選択して、スケジュールの一覧画面を開きます。「+新規」を押して、「新規」画面を開きます。
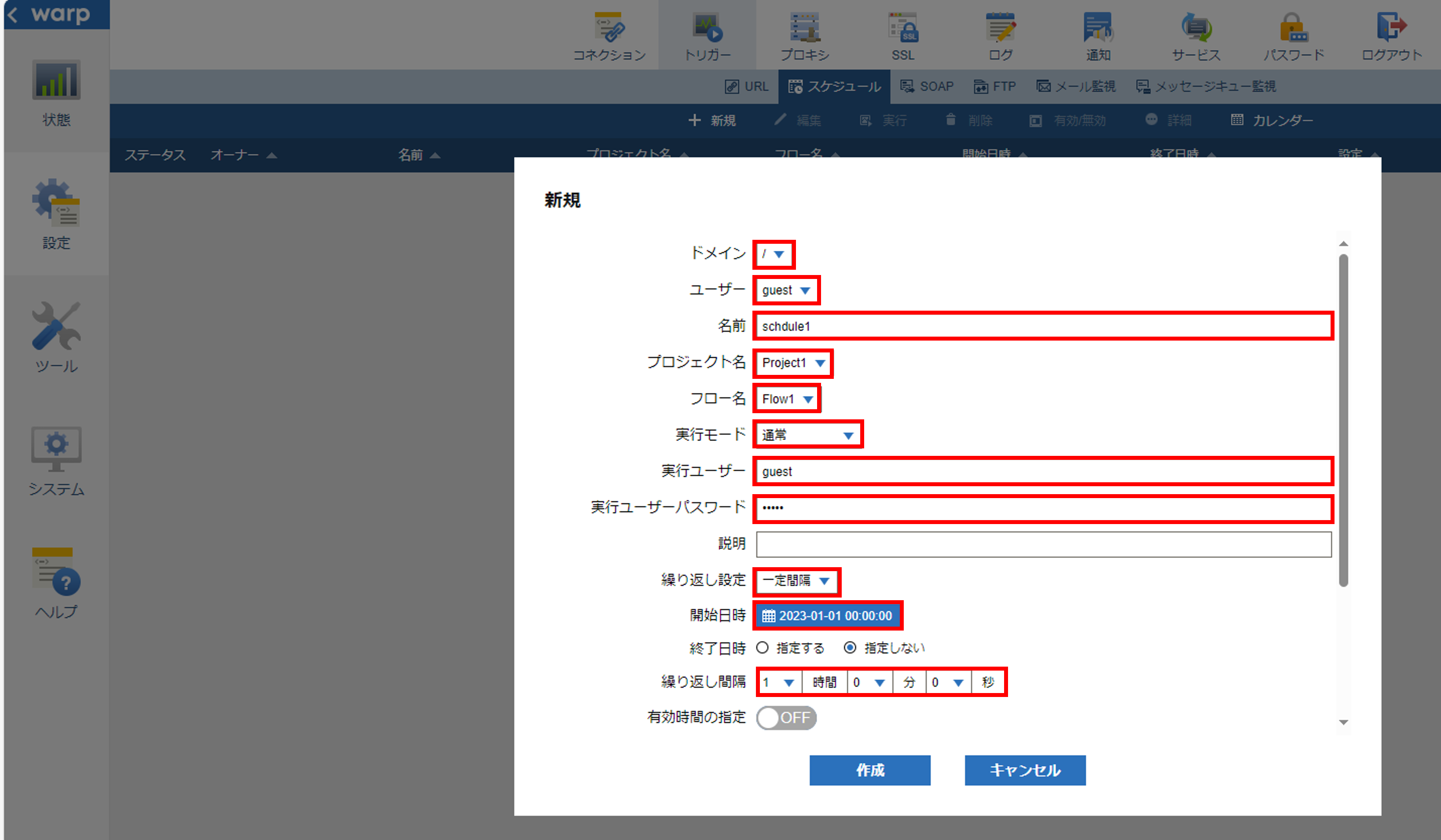
「ドメイン」「ユーザ」を選択して、スケジュールの「名前」を入力します。スケジュールで実行する「プロジェクト」と「フロー名」を選択して、「実行モード」を選択します。「実行ユーザ」と「実行ユーザパスワード」を入力します。「繰り返し設定」で「一定間隔」を選択します。「開始日時」に「2023-01-01 00:00:00」を設定して、「繰り返し間隔」に「1時間0分0秒」を設定します。
以上の設定で「2023-01-01 00:00:00」から1時間ごとに自動でスケジュール実行が行われます。
5 GridDBとASTERIA Warpのデータ型のマッピング
GridDBとASTERIA Warpのデータ型のマッピングを下記の表に示します。
| GridDB データ型 | ASTERIA Warpデータ型 |
|---|---|
| BOOL | Boolean |
| STRING | String |
| BYTE | Integer |
| SHORT | Integer |
| INTEGER | Integer |
| LONG | Integer |
| FLOAT | Double |
| DOUBLE | Double |
| TIMESTAMP | DateTime |
上記以外のデータ型については動作対象外となります。
6 Talend Open Studioについて
本項では、Talend Open StudioのTalend Open Studio for Data Integration 8.0.1(以降、Talend Open Studio)での集計方法について説明します。
Talend Open Studioとは、Talend株式会社が提供しているETLツールです。
指定したデータソースからデータウェアハウスを構築して、データの分析を行うツールです。
詳細はTalend株式会社の公式ページを参照してください。
7 Talend Open Studioを用いたGridDBの集計手順
Talend Open Studioを用いたGridDBの集計手順について説明します。
Talendはジョブと呼ばれる処理の流れを作成して、集計処理を実現します。
ジョブの中でコンポーネントと呼ばれる機能を配置します。
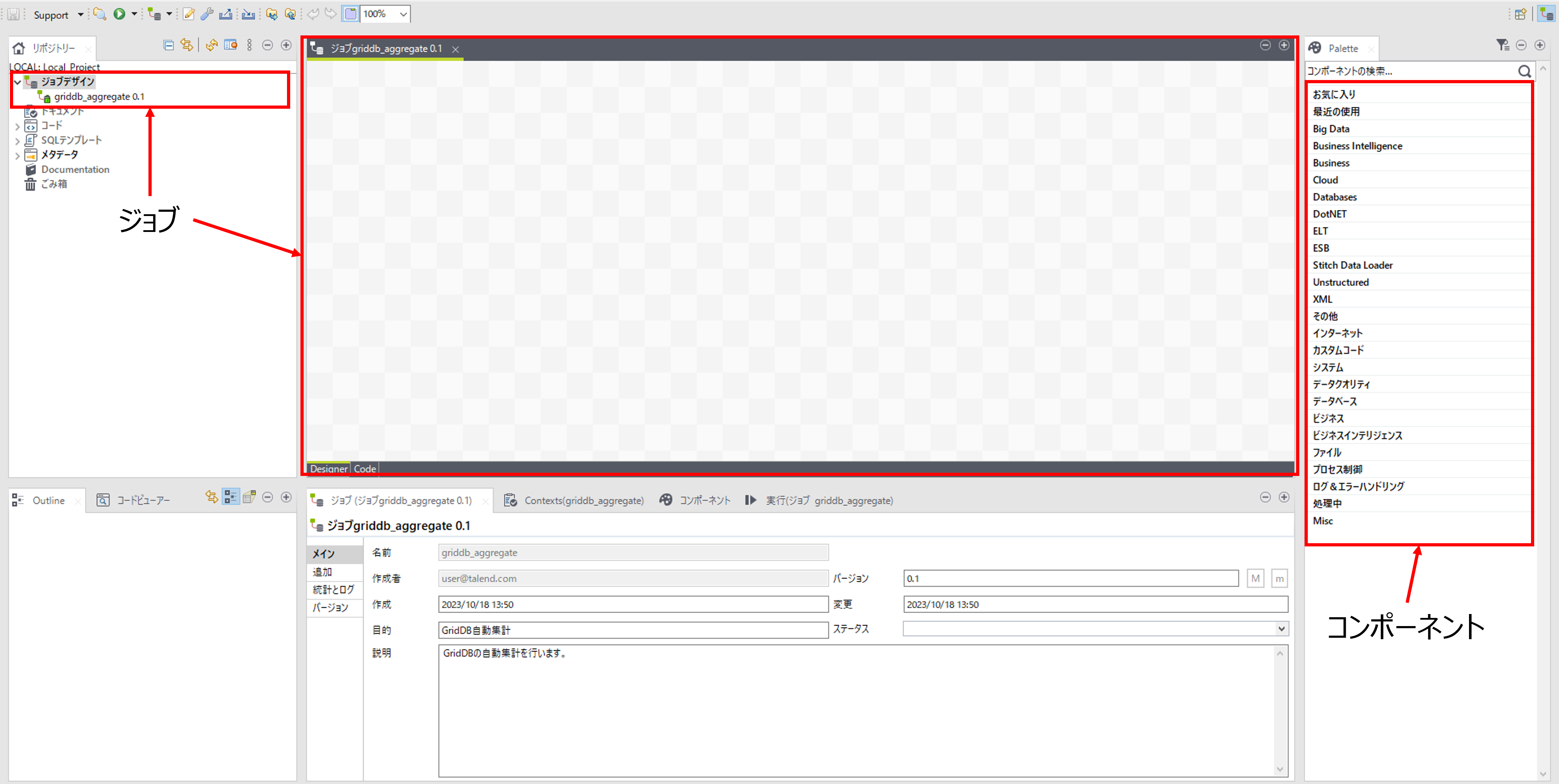
Talend Open Studioを用いたGridDBの集計手順では、GridDBのコンテナ、JDBCドライバとTalend Open Studioの各コンポーネントを用います。
Talend Open StudioとGridDBをそれぞれ準備します。
以下の流れで自動集計を行います。
- 環境構築
- ジョブ作成
- データベース作成
- スキーマ取得
- コンポーネント作成と配置
- デプロイ
- 定期実行
7.1 環境構築
Talendのインストール方法は、Talend Open Studioのインストール手順を参照してください。
7.2 Talend ジョブ作成
ジョブデザインで右クリックをして「ジョブの作成」を選択して、「新規ジョブ」画面を開きます。
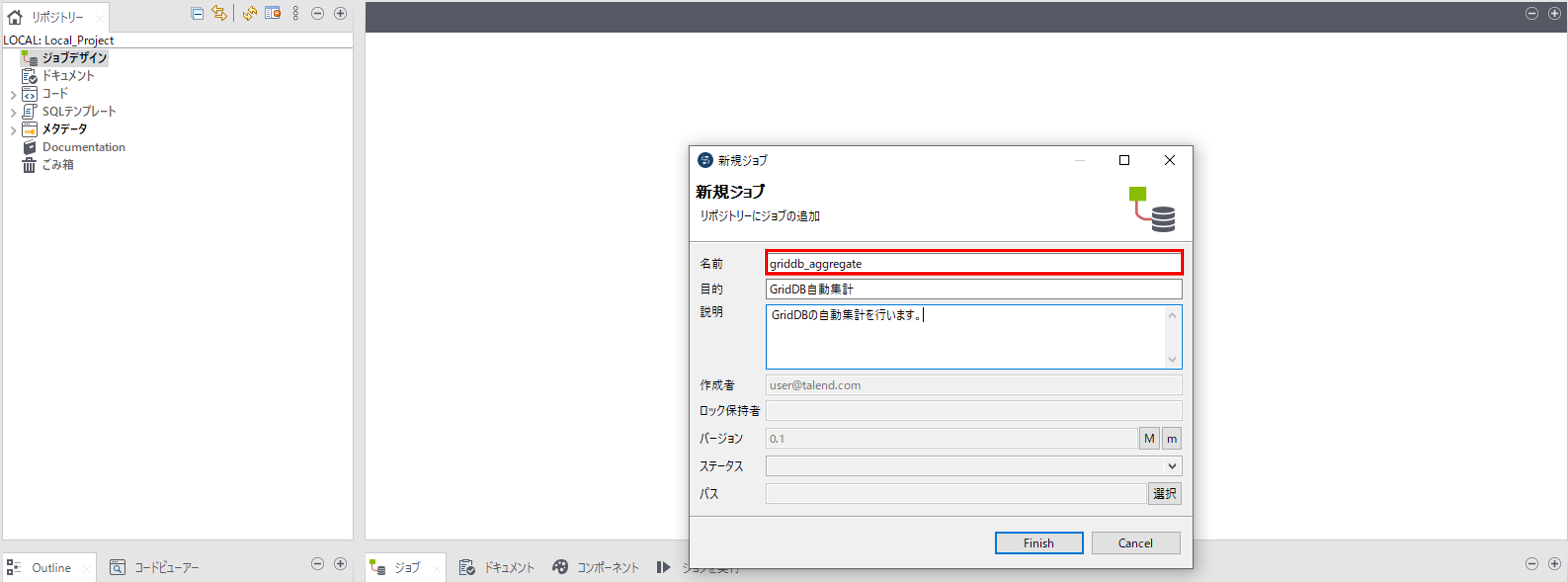
ジョブの「名前(必須)」、「目的(任意)」、「説明(任意)」を入力して、ジョブを作成します。
7.3 Talend データベース接続作成
メタデータのDB接続で右クリックをして「接続を作成」を選択して、「データベース接続」画面を開きます。
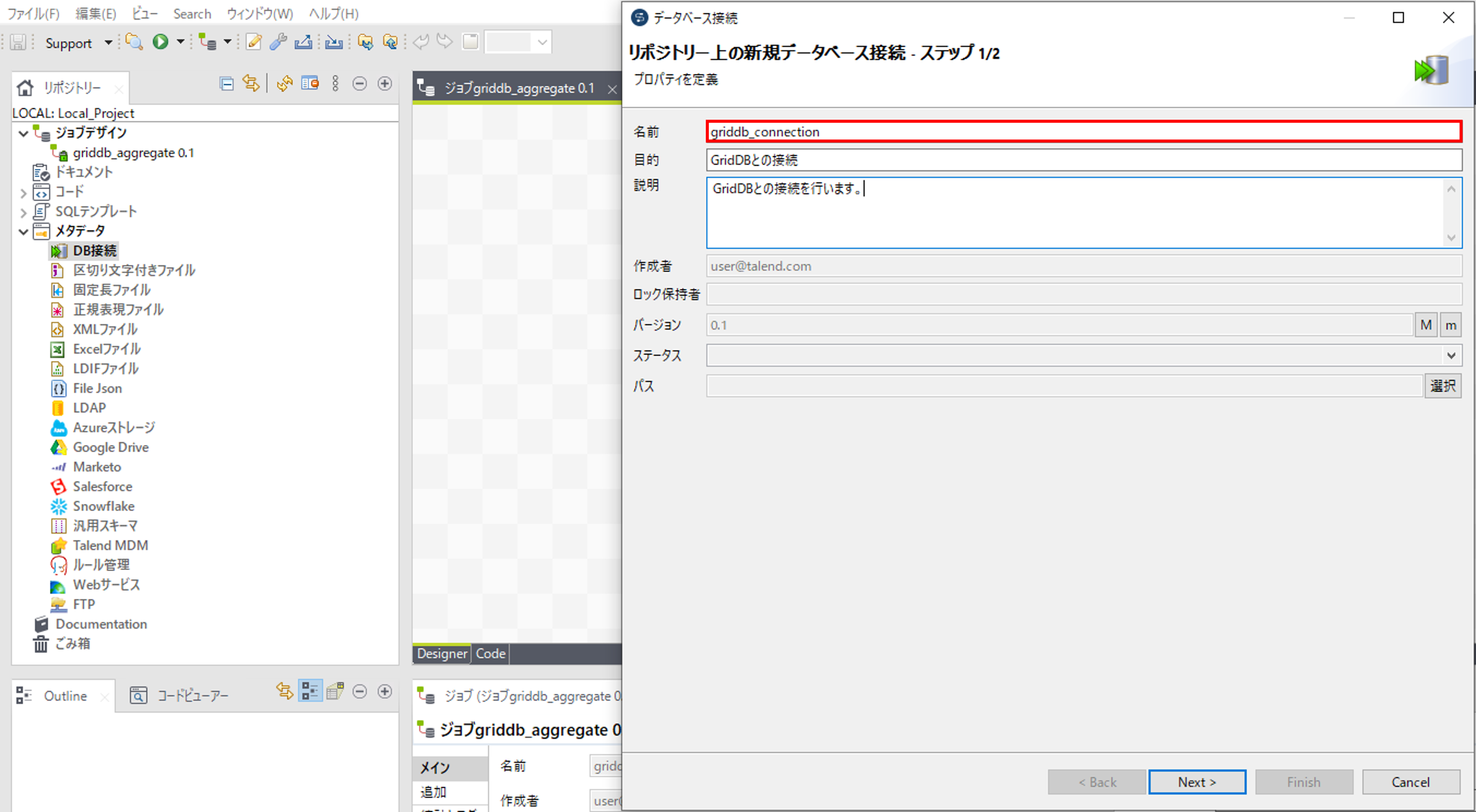
データベースの「名前(必須)」、「目的(任意)」、「説明(任意)」を入力します。
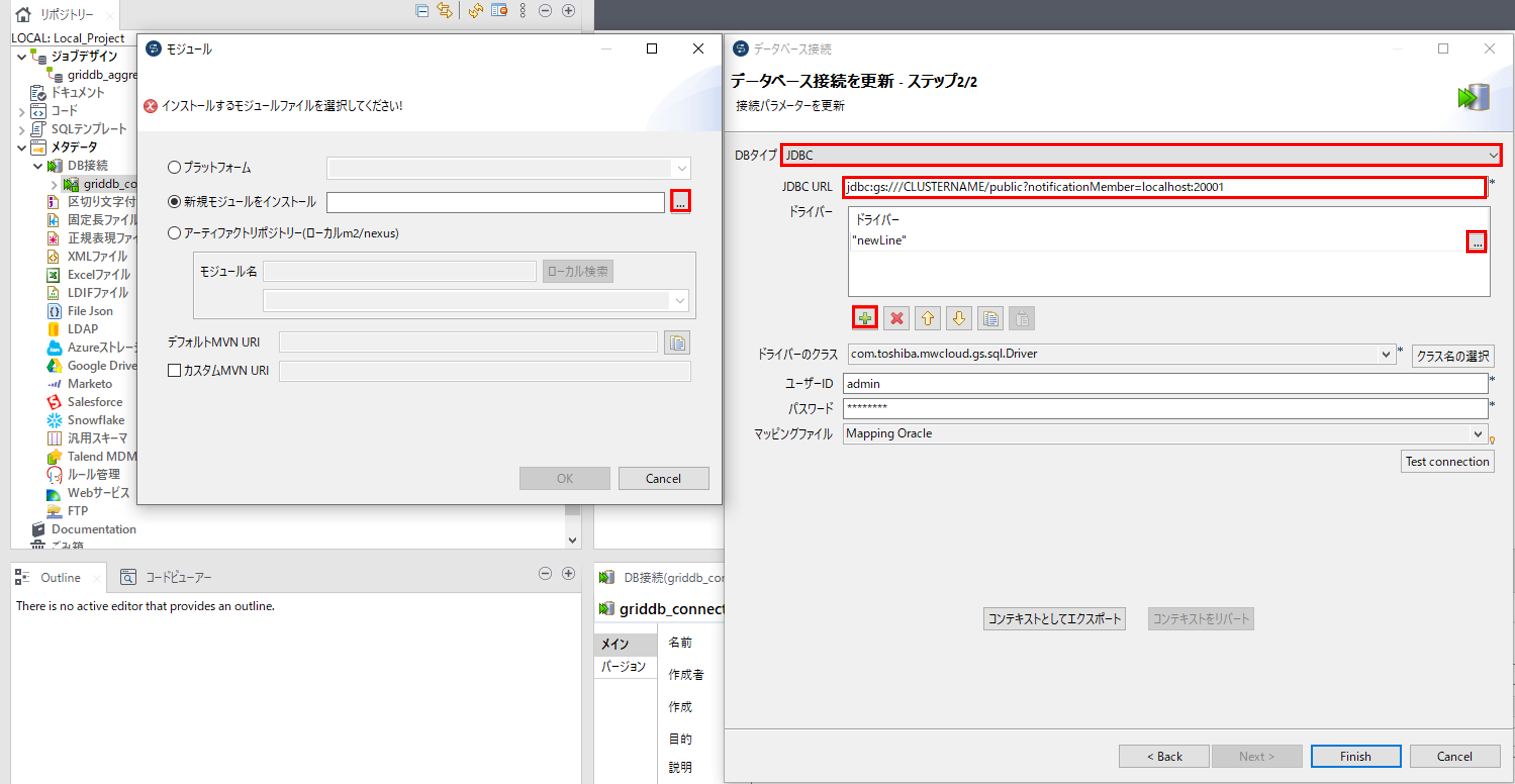
「DBタイプ」からJDBCを選択して、「JDBC URL」に接続対象のGridDBのJDBCのURLを入力します。
GridDBのJDBC URLの設定は『GridDB JDBCドライバ説明書』(GridDB_JDBC_Driver_UserGuide.html) を参照してください。
ドライバ入力欄から「+」を押して、ドライバを追加します。追加したドライバの「...」を押して「モジュール」画面を開きます。「新規モジュールをインストール」を選択して、「...」からTalendの動作環境から「gridstore-jdbc.jar」を選んで、ドライバに追加します。
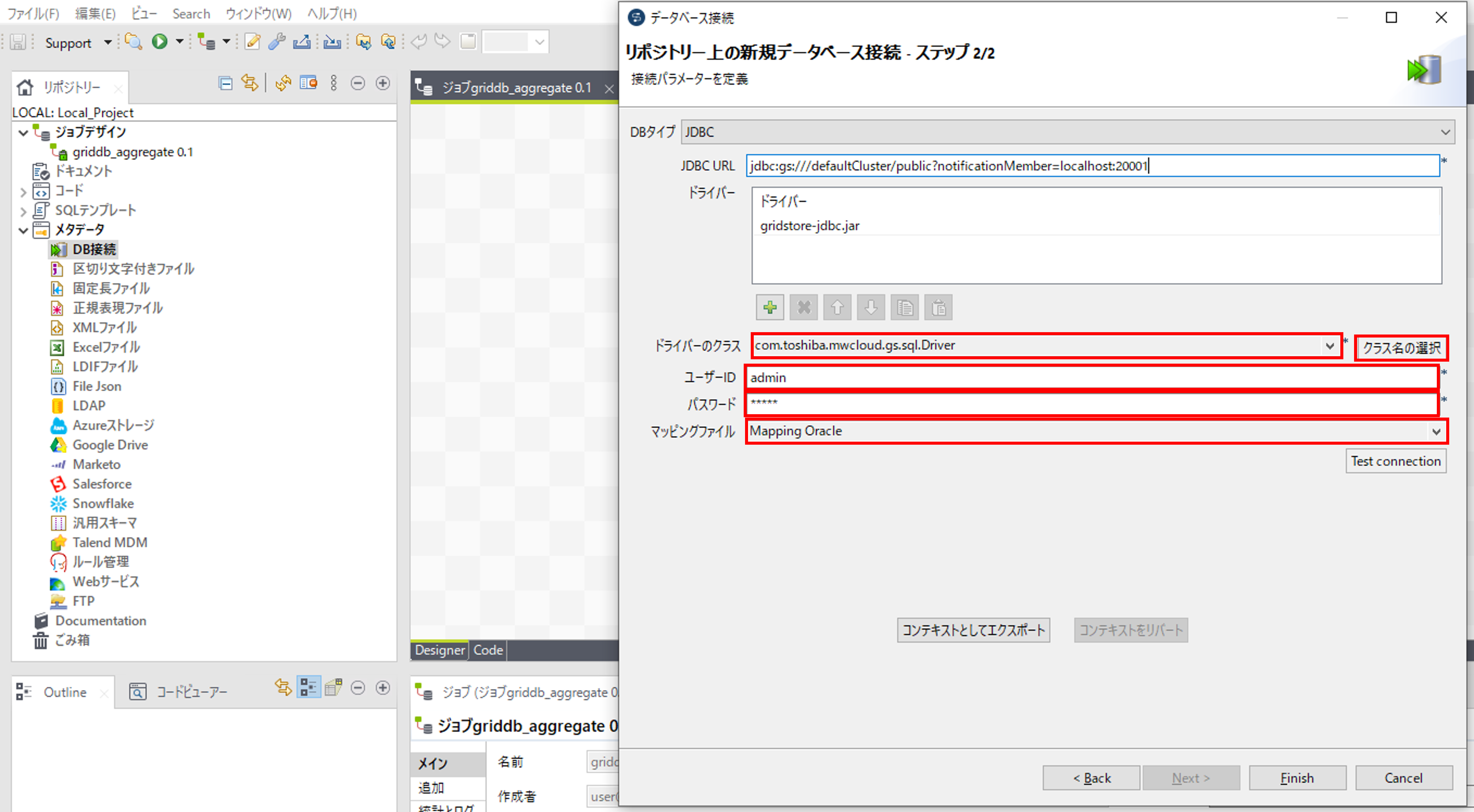
「ドライバのクラス」で「クラス名の選択」を押して、「com.toshiba.mwcloud.gs.sql.Driver」を追加します。「ユーザID」と「パスワード」にそれぞれGridDBの接続ユーザIDとパスワードを入力します。「マッピングファイル」で「Mapping Oracle」を選択して、データベースを作成します。
7.4 Talend スキーマ取得
Talend データベース接続作成で作成したデータベース接続で右クリックをして「スキーマを取得」を選択して、「スキーマ」画面を開きます。
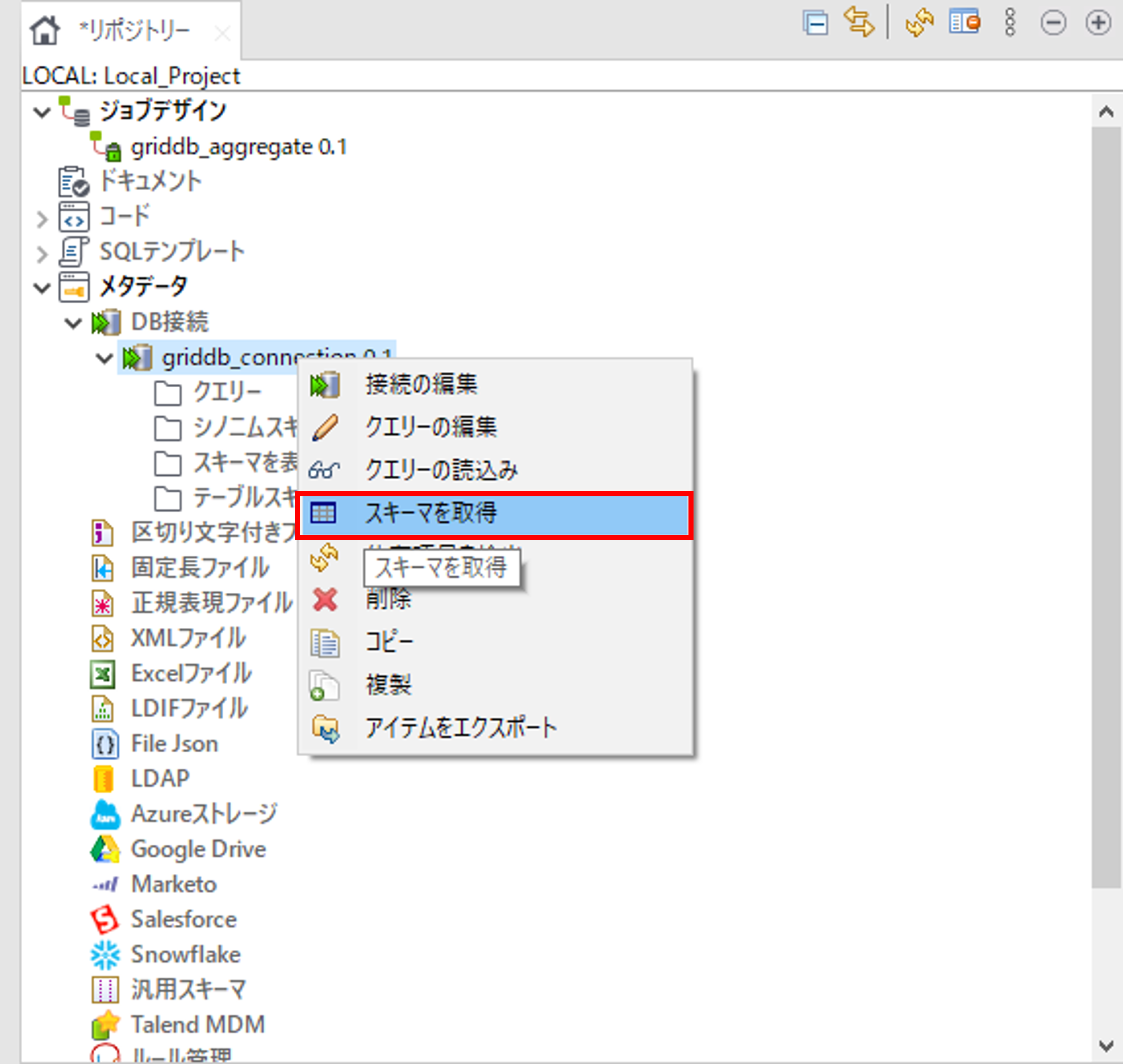
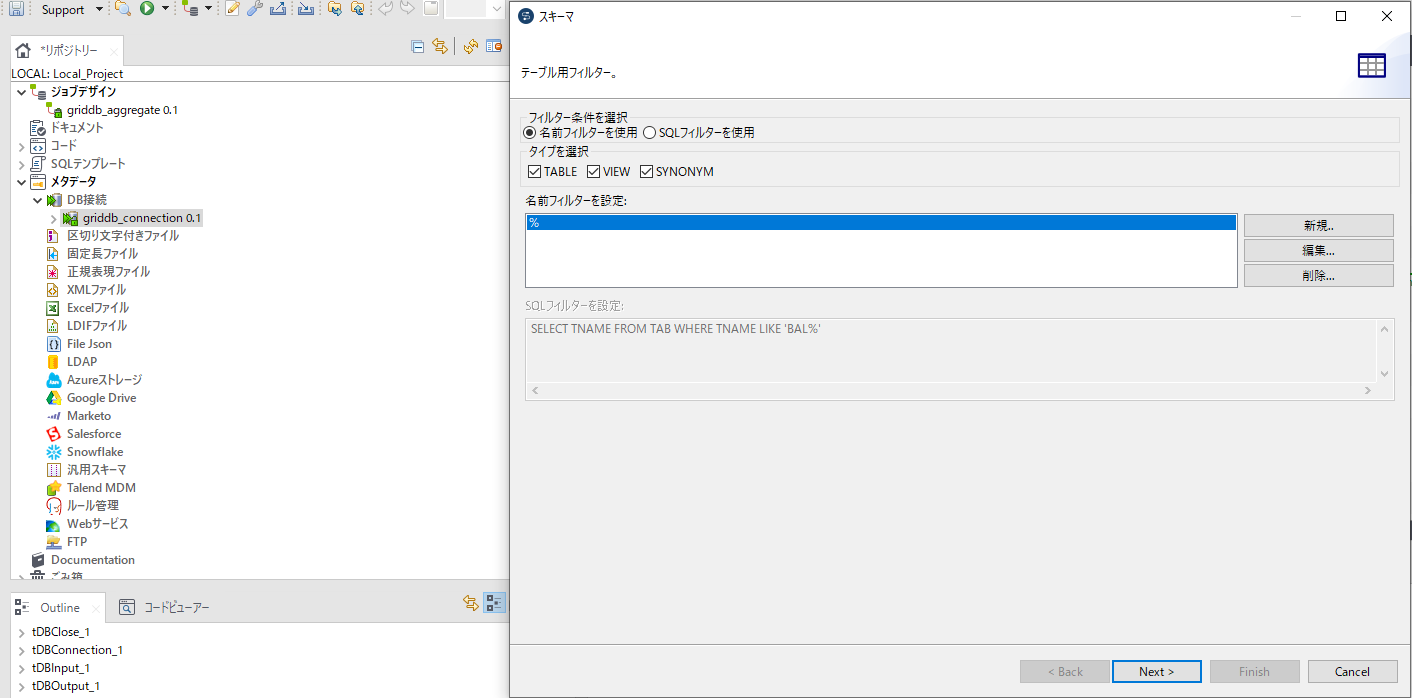
フィルターの条件を指定して、「Next」ボタンを押します。
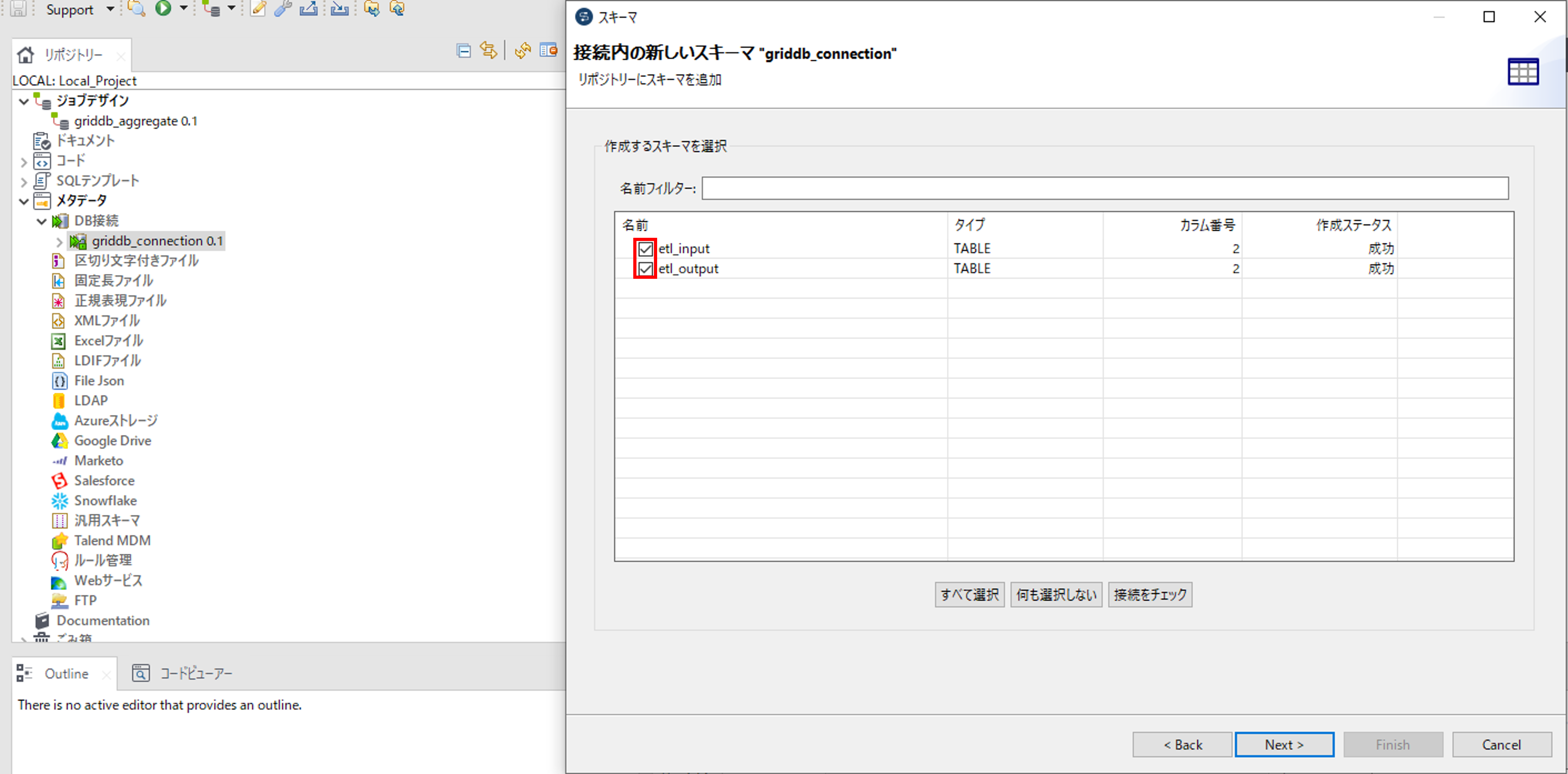
スキーマを取得するコンテナにチェックを入れて、「Next」ボタンを押します。
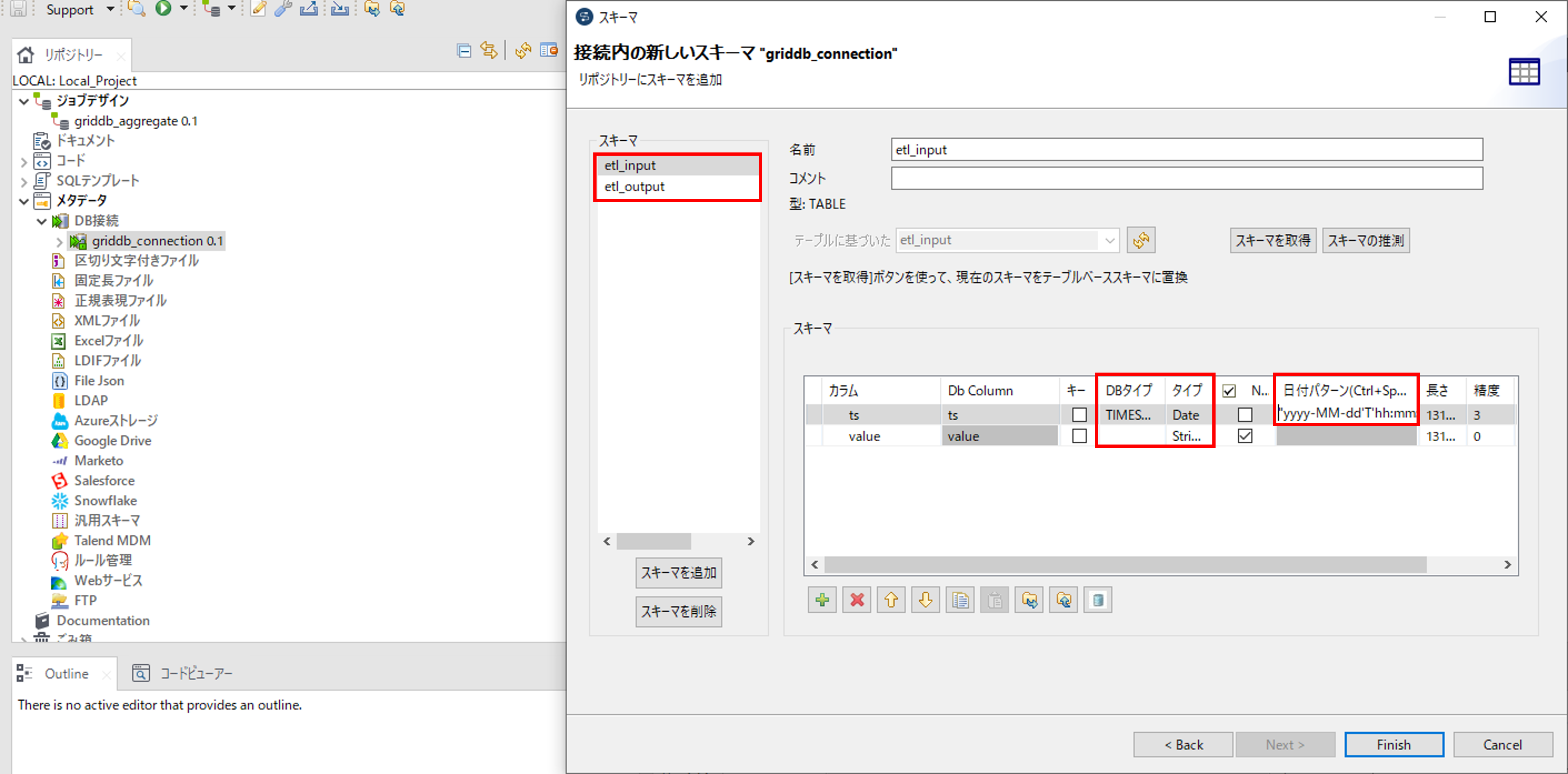
「スキーマ」でコンテナを選択して、「スキーマ」の「DBタイプ」がTIMESTAMPのカラムの「日付パターン」に"yyyy-MM-dd'T'hh:mm:ssZ"を記載して、スキーマを取得します。「タイプ」に記載されているデータ型とGridDBのコンテナのデータ型が一致していない場合は、データ型を一致させてください。データのマッピングについてはGridDBとTalendのデータ型のマッピングを参照してください。
7.5 Talend コンポーネント作成と配置
各コンポーネントを配置して、ジョブを作成します。
| コンポーネント名 | コンポーネントの説明 | コンポーネントのイメージ |
|---|---|---|
| tDBConnection | 外部のデータソースとの接続を確立するコンポーネント |  |
| tDBInput | 外部のデータソースからデータを取得するコンポーネント |  |
| tLogRow | データを標準出力するコンポーネント |  |
| tDBOutput | データを外部のデータソースに出力するコンポーネント |  |
| tDBClose | 外部のデータソースとの接続を閉じるコンポーネント |  |

①GridDBとのコネクション作成
tDBConnectionコンポーネントでGridDBとのコネクションを作成します。
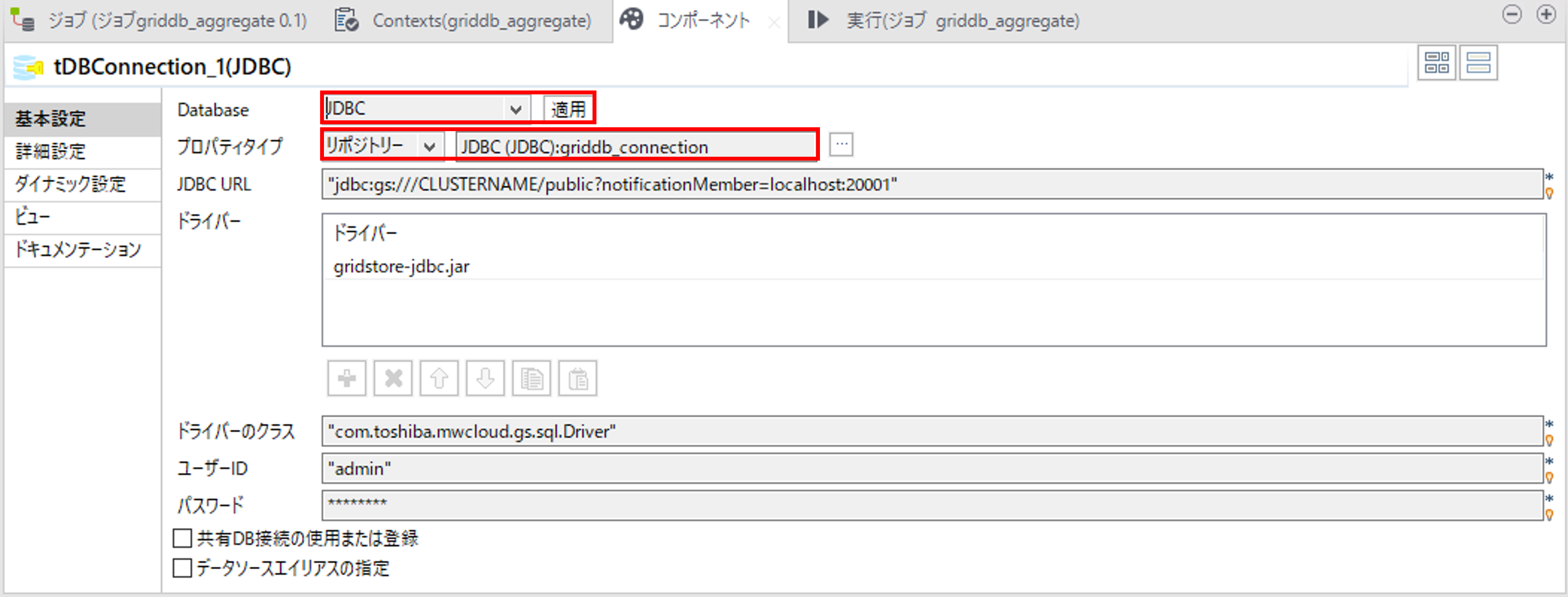
「Database」で「JDBC」を選択して、「適用」を押します。
「プロパティタイプ」で「リポジトリ」を選択し、Talend データベース接続作成で作成したデータベース接続を選択します。
②GridDBから集計結果取得
tDBInputコンポーネントでGridDBからクエリ条件を指定してデータを取得します。
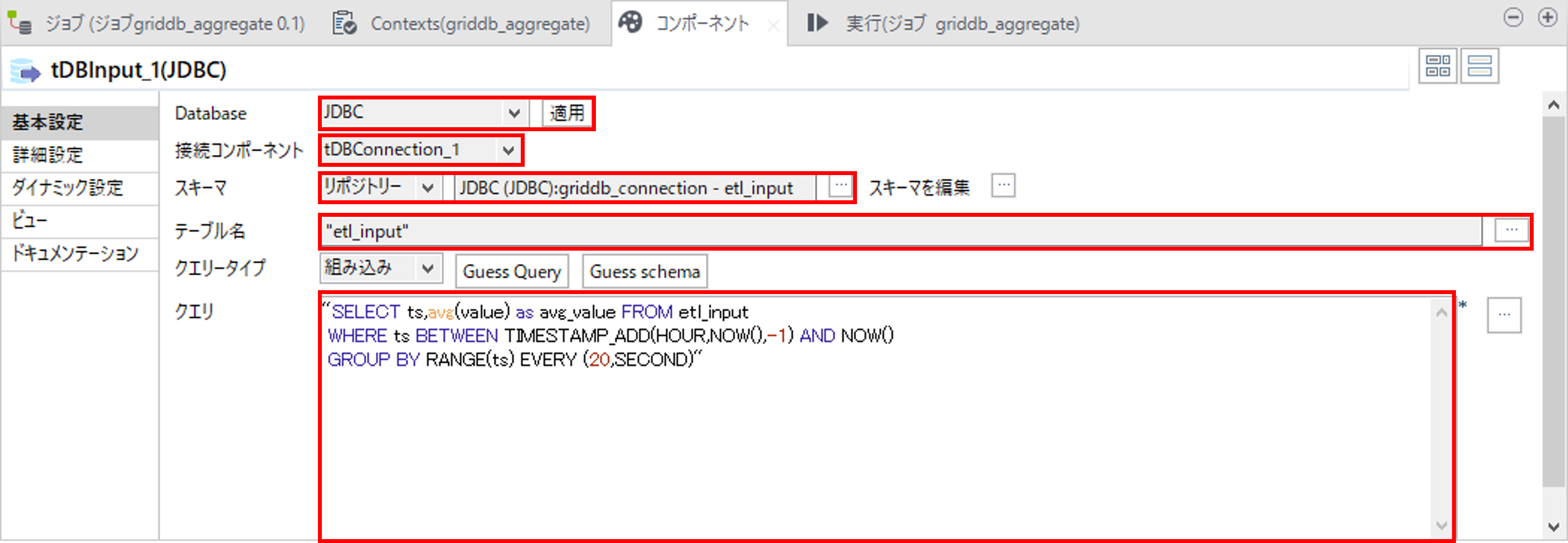
「Database」で「JDBC」を選択して、「適用」を押します。
「接続コンポーネント」で①GridDBとのコネクションで作成したtDBConnectionコンポーネントを選択します。
「スキーマ」で「リポジトリー」を選択して、Talend スキーマ取得で取得したスキーマを選択します。
「テーブル名」で、Talend スキーマ取得で取得したスキーマを選択します。
「クエリ」に以下のSQL文を記載します。
直近1時間のデータを20秒ごとに集計して平均値を取得します。
SELECT ts,avg(value) as avg_value FROM etl_input
WHERE ts BETWEEN TIMESTAMP_ADD(HOUR,NOW(),-1) AND NOW()
GROUP BY RANGE(ts) EVERY (20,SECOND)
③データの標準出力
tLogRowコンポーネントで取得したデータを標準出力します。
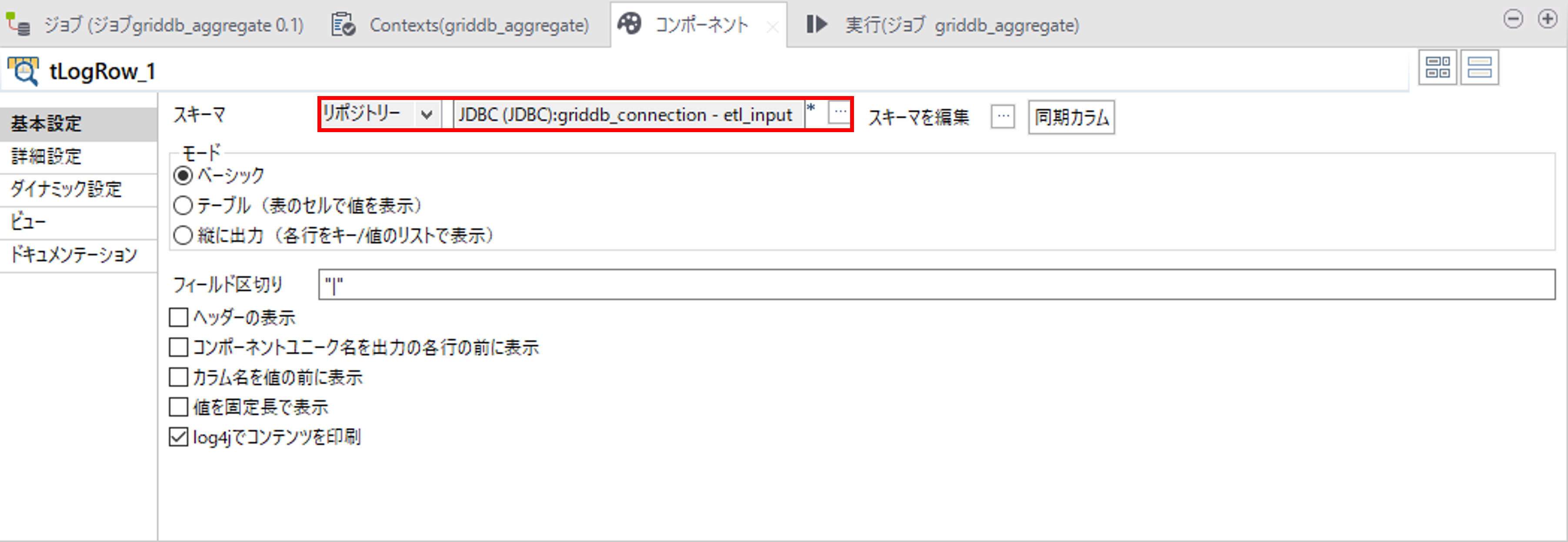
「スキーマ」で「リポジトリー」を選択して、Talend スキーマ取得で取得したスキーマを選択します。
④集計結果をGridDBに登録
tDBOutputコンポーネントでGridDBにデータを登録します。
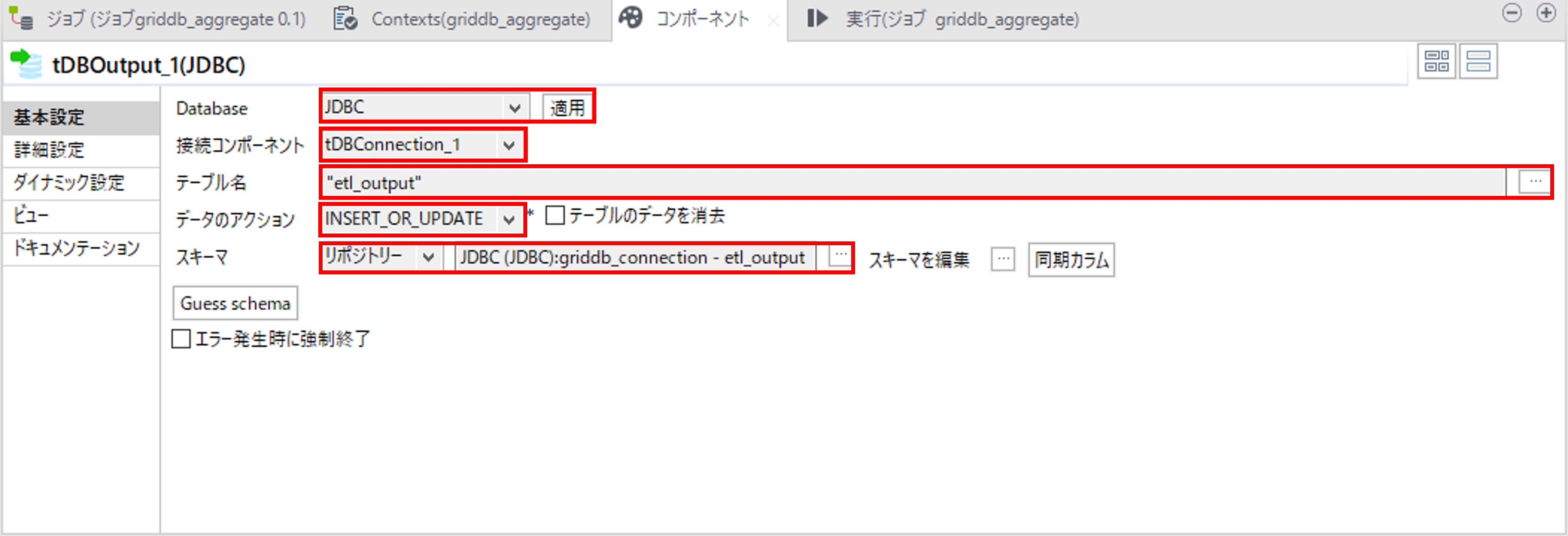
「Database」で「JDBC」を選択して、「適用」を押します。
「接続コンポーネント」で①GridDBとのコネクションで作成したtDBConnectionコンポーネントを選択します。
「テーブル名」で、Talend スキーマ取得で取得したスキーマを選択します。
「データのアクション」で、「INSERT」を選択します。
「スキーマ」で「リポジトリー」を選択して、Talend スキーマ取得で取得したスキーマを選択します。
更新や削除を行う場合は「詳細設定」でフィールドオプションを指定します。
バッチ更新を使用する場合は「バッチの使用」にチェックを入れて、「バッチサイズ」を指定します。
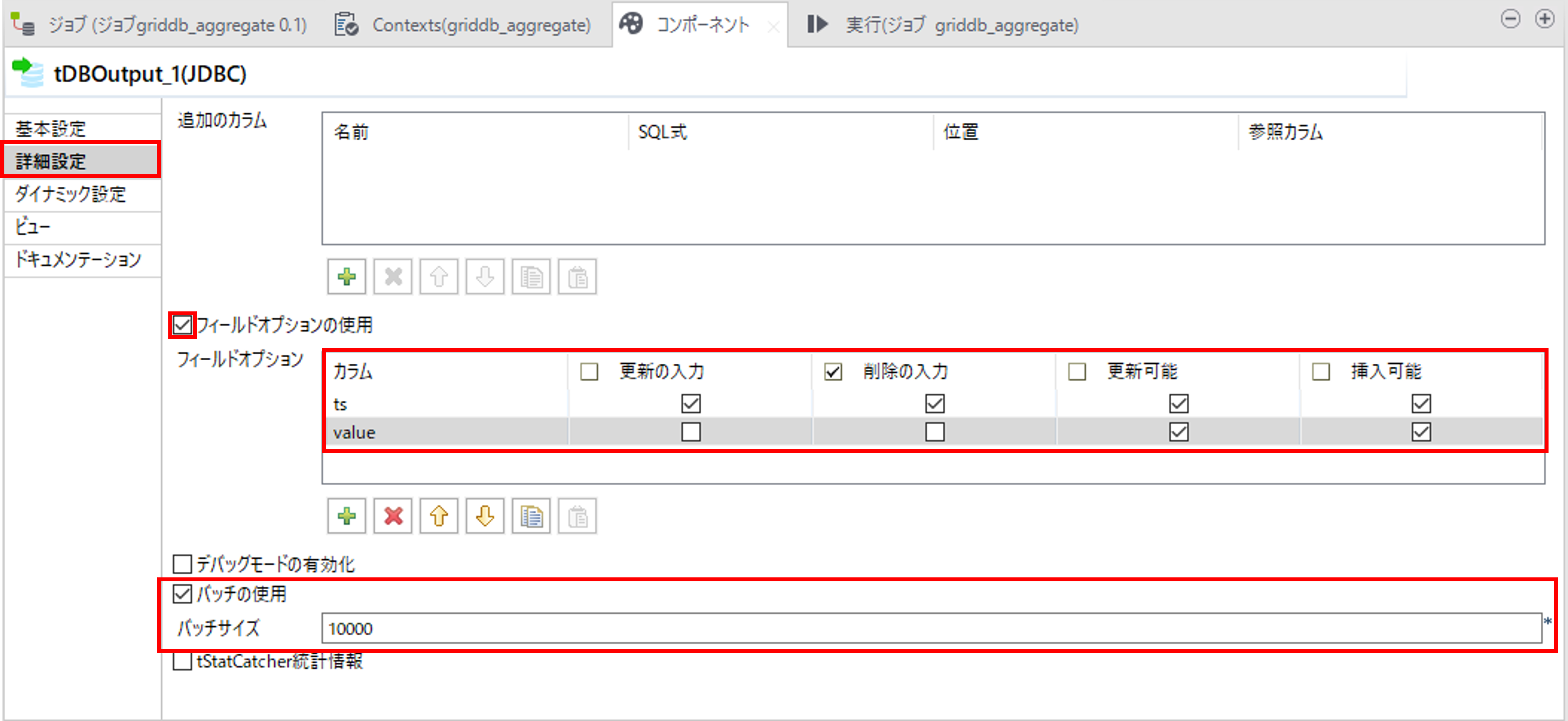
⑤GridDBとのコネクションをクローズ
tDBCloseコンポーネントでGridDBとのコネクションを閉じます。
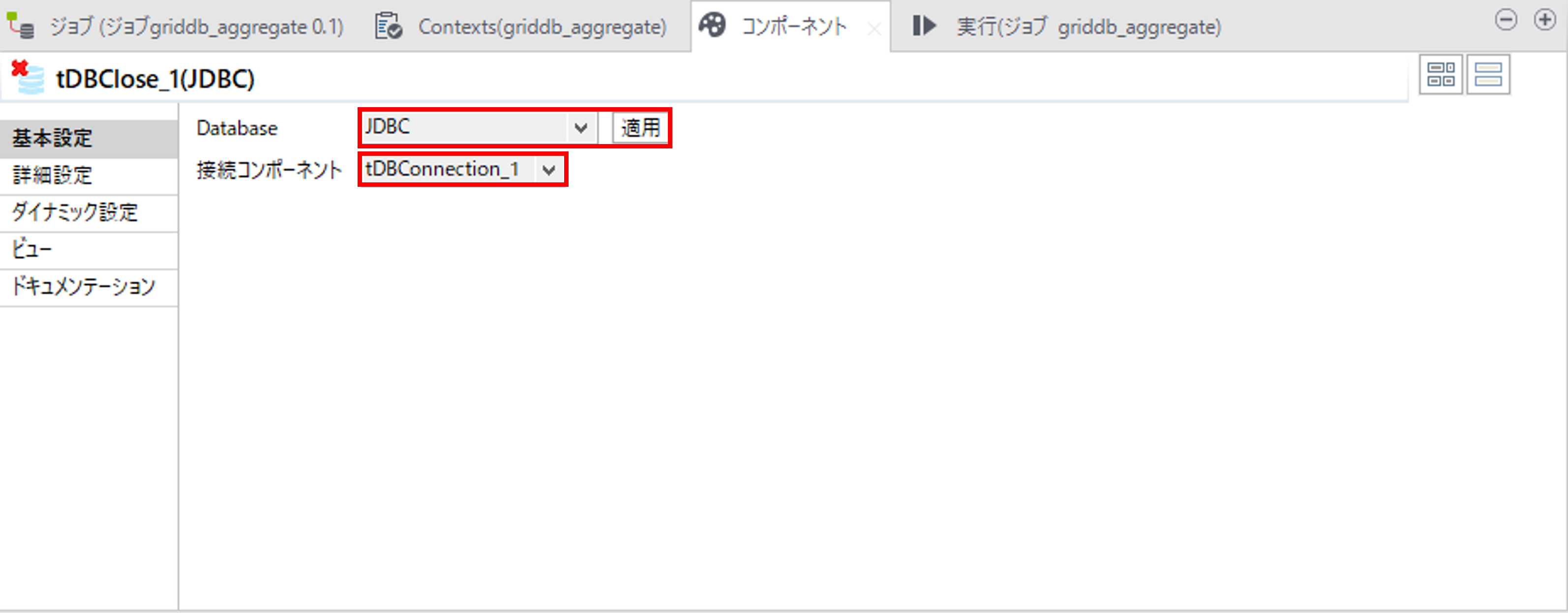
「Database」で「JDBC」を選択して、「適用」を押します。
「接続コンポーネント」で①GridDBとのコネクションで作成したtDBConnectionコンポーネントを選択します。
必要に応じて、一度実行して動作確認を行います。
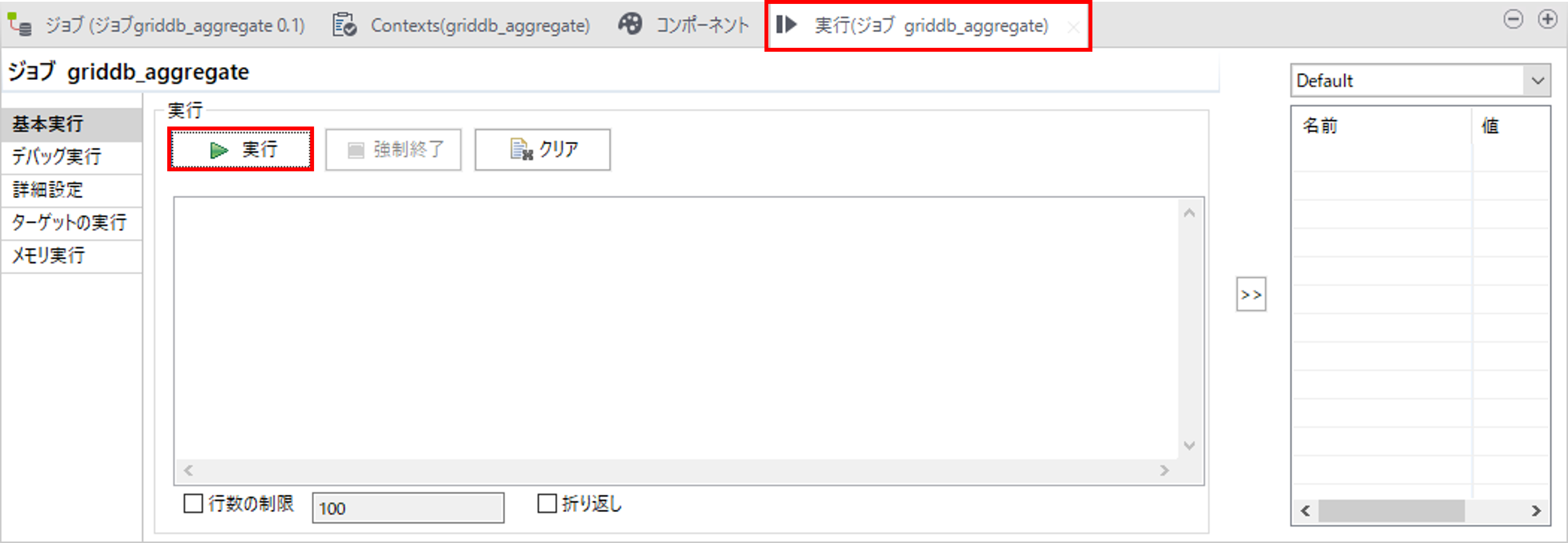
「実行」タブを選択して、「実行」ボタンを押して、実行を行います。
7.6 Talend デプロイ
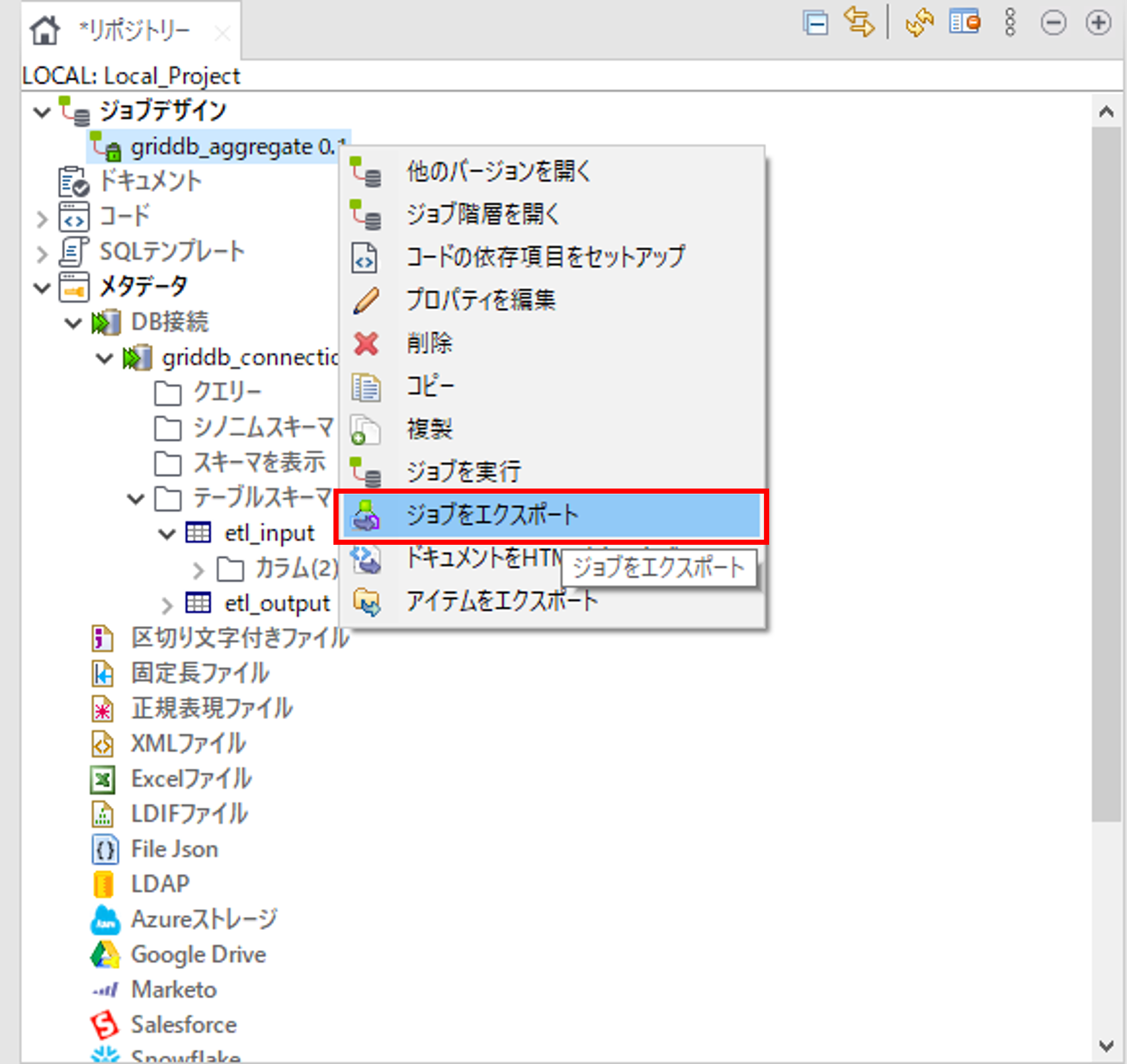
ジョブデザインの作成したジョブで右クリックをして「ジョブをエクスポート」を選択して、「ジョブをエクスポート」画面を開きます。
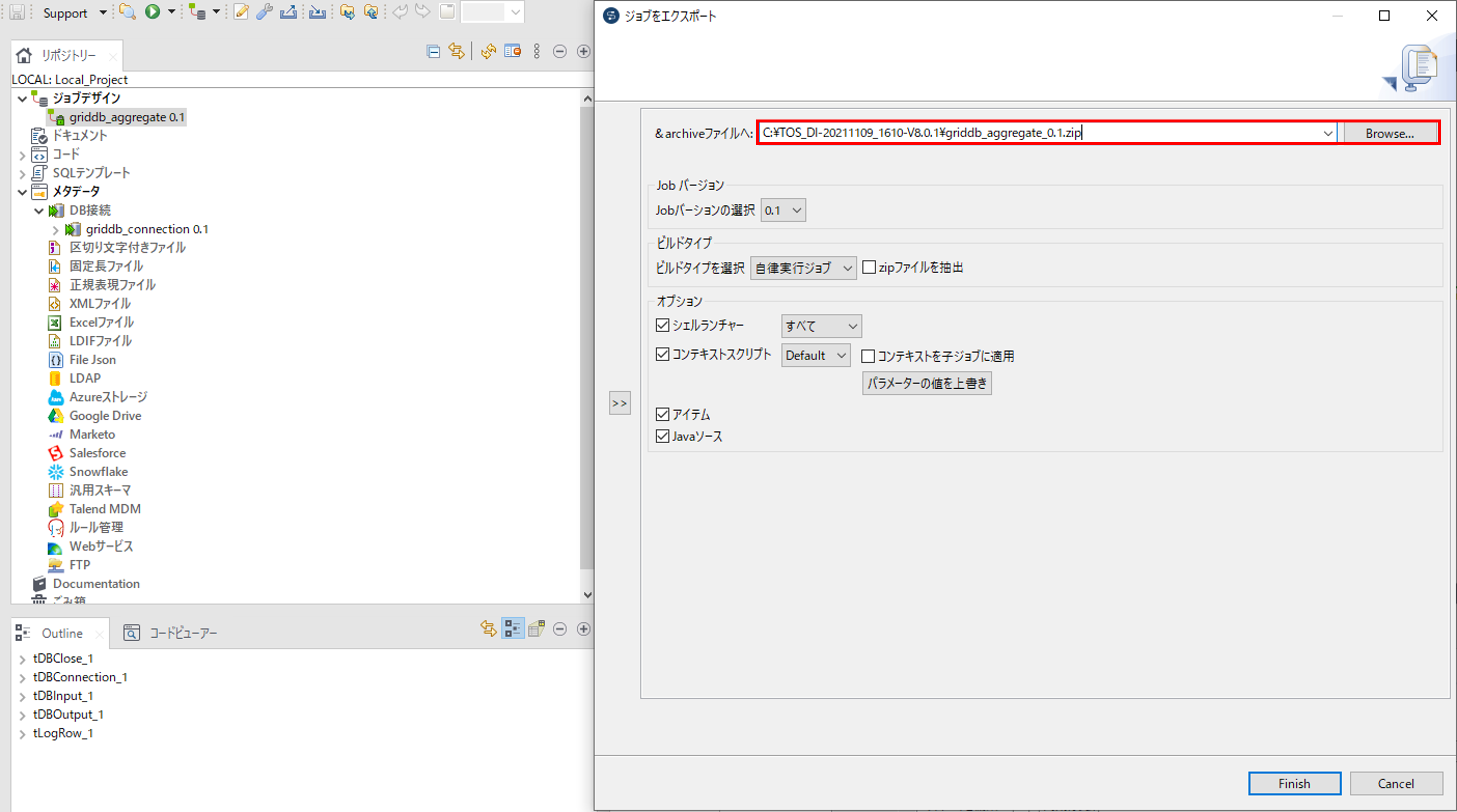
指定した場所にジョブの圧縮ファイルをエクスポートします。
圧縮ファイルを解凍するとフォルダに実行ファイルのバッチファイルとシェルスクリプトファイルが作成されます。
解凍したフォルダを動作させる環境にデプロイします。デプロイした実行ファイルを実行します。
$ cd griddb_aggregate_0.1/griddb_aggregate
$ sh griddb_aggregate_run.sh
2023-01-01T09:00:00+0900|20.0
2023-01-01T09:00:20+0900|40.0
2023-01-01T09:00:40+0900|60.0
2023-01-01T09:01:00+0900|
7.7 定期実行
cronを用いて、定期実行を行います。 1時間ごとに実行する場合は以下のようなcronを作成します。
$ crontab -e
* */1 * * * /griddb_aggregate_0.1/griddb_aggregate/griddb_aggregate_run.sh
上記のようにcrontabとシェルスクリプトを組み合わせて定期実行を実現します。
8 GridDBとTalendのデータ型のマッピング
GridDBとTalendのデータ型のマッピングを下記の表に示します。
| GridDB データ型 | Talendデータ型 |
|---|---|
| BOOL | BOOLEAN |
| STRING | STRING |
| BYTE | INTEGER |
| SHORT | INTEGER |
| INTEGER | INTEGER |
| LONG | INTEGER |
| FLOAT | FLOAT |
| DOUBLE | FLOAT |
| TIMESTAMP | TIMESTAMP |
上記以外のデータ型については動作対象外となります。