GridDB クイックスタートガイド
Revision: 3759
1 はじめに
1.1 本書の構成
本書では、初めてGridDBをお使いの方に製品の概要と簡単な使い方を説明します。簡単な使い方としては、1台のPCにGridDBをインストールして、起動・停止やデータ操作を行う一連の手順を説明します。
各章は次の内容です。
はじめに
GridDBの2つの製品(GridDB Standard Edition/GridDB Advanced Edition)について説明します。また、GridDBのアーキテクチャ・データモデルの基本である「ノードとクラスタ」と「コンテナとロウ」について、概略を説明します。GridDBのインストール
1台のPCへGridDBをインストールする操作手順を説明します。ここで説明する手順に従ってGridDBをインストールしてください。起動/停止
GridDBの起動操作、停止操作を説明します。GridDBには操作方法はいくつかありますが、運用コマンドを使った操作方法を紹介します。データ操作
GridDBの様々な操作を行うgs_shコマンドや、インポートを行うgs_importコマンドを使った簡単なデータ操作を説明します。ここでは、クラスタに接続してコンテナを作成したのち、データ登録して検索を行うという一連の基本的な操作を説明します。サンプルプログラムの実行
GridDBには、コンテナ作成やデータ登録するサンプルプログラムが用意されています。サンプルプログラムのビルドおよび実行方法の例を紹介します。GridDBのアンインストール
GridDBが不要となった場合のアンインストール手順を説明します。
1.2 GridDBとは
GridDBは、膨大なデータを高速かつ安全に蓄積し検索することができるデータベースです。
GridDBには、以下の2つの製品があります。
- GridDB Standard Edition (GridDB SE)
- NoSQL型データベース製品
- GridDB Advanced Edition (GridDB AE)
- GridDB SEに、さらにSQL機能を備えたNewSQL型データベース製品
GridDB Standard Edition(以降「GridDB SE]と呼びます)には、次の特長があります。
- インメモリ処理によるデータ管理の高速化
- スケールアウトによる大容量化
- ディスクへのデータ保存による永続化、データのレプリケーション、さらにトランザクション機能による高信頼化
- クラスタへのノードの追加・削除の自律管理による運用の容易化
GridDB Advanced Edition(以降「GridDB AE」と呼びます)は、GridDB SEのベース技術を活用し、さらにSQL機能を追加した製品です。 GridDB AEは機能的にGridDB SEを包含していますので、GridDB SEの特長・機能をそのまま持ちます。 SQL機能はSQL92に準拠しており、JDBC(Java Database Connectivity)とODBC(Open Database Connectivity)を利用できます。また、JDBC/ODBCを利用することで、BI(Business Intelligence)ツールやETL(Extract Transfer Load)ツールからデータベースに直接アクセスすることもできます。
各製品で利用できるインタフェース
| GridDB SE | GridDB AE | |
|---|---|---|
| Java API | ○ | ○ |
| C API | ○ | ○ |
| JDBC | - | ○ |
| ODBC | - | ○ |
1.3 GridDBの仕組み
GridDBのアーキテクチャ・データモデルの基本である「ノードとクラスタ」および「コンテナとロウ」について説明します。
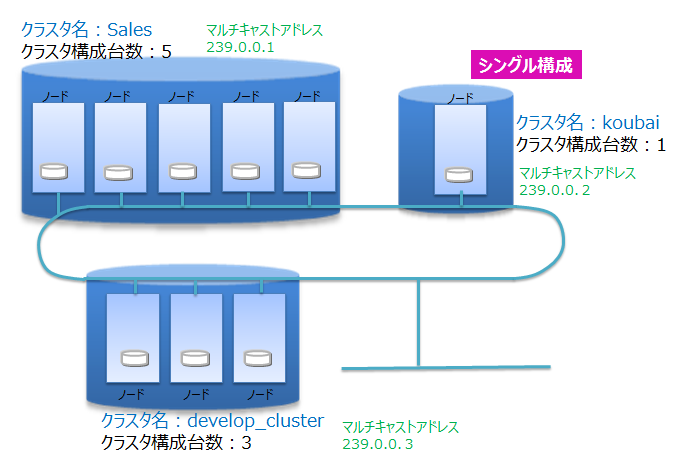
1.3.1 ノードとクラスタ
「ノード」とは、GridDBでデータ管理を行うひとつのサーバプロセスを指します。1台のマシンには、ひとつのノードだけが動作できます。
GridDBは、複数のノードで構成される「クラスタ」で動作します。アプリケーションからデータベースにアクセスするには、ノードが起動されており、かつ、クラスタのサービスが開始されている必要があります。
クラスタは、クラスタを構成するノード数分のノードがクラスタへ参加することで、サービスが開始されます。構成ノード数のノードすべてがクラスタに参加するまでクラスタは開始されず、アプリケーションからはデータベースにアクセスすることはできません。
ノード1台で動作させる場合にもクラスタを構成する必要があります。この場合、構成ノード数を1台でクラスタを構成することになります。ノード1台で動作させる構成を「シングル構成」と呼びます。ネットワーク上に複数のクラスタが混在しても識別できるように、クラスタには「クラスタ名」をつけます。この「クラスタ名」を使って、ノードやアプリケーションはクラスタを特定します。
1.3.2 データモデル -コンテナとロウを理解しましょうー
GridDBは、NoSQLの代表的なデータモデルであるキー・バリュー型を拡張した独自のキー・コンテナ型データモデルです。以下の特長があります。
- 「コンテナ」というRDBのテーブルに似た概念を導入しています。コンテナでデータを管理します。
- コンテナには、カラムのデータ型を定義するスキーマ設定が可能です。また、カラムにインデックスを設定することができます。
- コンテナ単位でデータのACID特性を保証します。
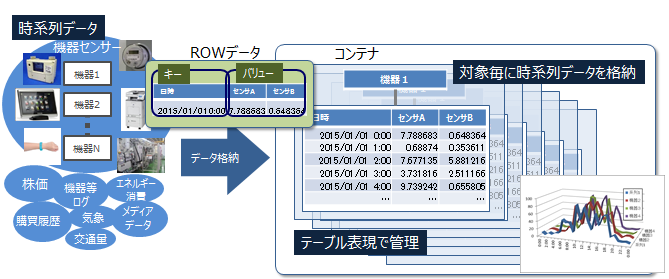
コンテナ
データを格納する入れ物です。コンテナには、コレクションと時系列コンテナという2つの種別が存在します。
- コレクション
- 一般的なデータを管理するためのコンテナ
- 時系列コンテナ
- 時系列データを管理するためのコンテナ
アプリケーションでデータを登録する前には、必ずコンテナを作成しておく必要があります。
- コレクション
ロウ
ロウは、コンテナに登録される1行のデータを指します。コンテナには複数のロウが登録されます。
1.4 用語の説明
本書で用いられる用語の説明です。
| 用語 | 意味 |
|---|---|
| ノード | GridDBでデータ管理を行うひとつのサーバプロセスを指します。 |
| クラスタ | 一体となってデータ管理を行う、1つ、もしくは複数のノードの集合を指します。 |
| コンテナ | ロウの集合を管理する入れ物です。コレクションと時系列コンテナの2種類が存在します。 |
| コレクション | 一般の型のキーを持つロウを管理するコンテナの一種です。 |
| 時系列コンテナ | 時刻型のキーを持つロウを管理するコンテナの1種です。時系列データを扱う専用の機能を持ちます。 |
| ロウ | GridDBで管理する1件分のデータを指します。キーと複数の値からなるひとまとまりのデータです。 |
2 GridDBのインストール
1台のPCへGridDBをインストールして、GridDBを使ってみましょう。次の流れでインストールを行います。
- インストール前の確認
- GridDBのインストール
- 環境設定
2.1 インストール前の確認
GridDBをインストールするマシンのOSが、GridDBの動作保証範囲であることを確認します。 OSがRHELもしくはCentOSであり、かつ、リリースノートに記載のバージョンであることを確認してください。
[実行例] OSバージョンの確認
$ cat /etc/redhat-release
CentOS Linux release 7.2.1511 (Core)
[メモ]
- OSインストール時のOSパッケージグループの選択では、最低「Basic Server」を選択している必要があります。
2.2 GridDBのインストール
2.2.1 パッケージをインストールする
GridDBのRPMパッケージをインストールします。RPMパッケージには、サーバや運用ツール、ライブラリなどの種類があります。
| 分類 | パッケージ名 | ファイル名 | 内容 |
|---|---|---|---|
| サーバ | griddb-xx-server | griddb-xx-server-X.X.X-linux.x86_64.rpm | ノードモジュールとノードの起動コマンドなどが含まれます。 |
| 運用ツール | griddb-xx-client | griddb-xx-client-X.X.X-linux.x86_64.rpm | ノード起動を除く運用ツール一式が含まれます。 |
| 運用ツール/アプリケーション開発ライブラリ | griddb-xx-java_lib | griddb-xx-java_lib-X.X.X-linux.x86_64.rpm | javaのライブラリが含まれます。 |
| アプリケーション開発ライブラリ | griddb-xx-c_lib | griddb-xx-c_lib-X.X.X-linux.x86_64.rpm | Cのヘッダファイルとライブラリが含まれます。(必要に応じてインストールします) |
| 運用ツール/アプリケーション開発ライブラリ | griddb-xx-newsql | griddb-xx-newsql-X.X.X-linux.x86_64.rpm | NewSQLインターフェースのライブラリ(Java, C)が含まれます。(AE版のみ) |
※: xxはGridDBのエディション(se, ae, ve)
※: X.X.XはGridDBのバージョン
[メモ]
- アプリケーション開発ライブラリは、JavaやC以外のプログラミング言語のパッケージも提供しています。必要に応じてインストールしてください。
インストールするマシンの任意の場所に、上記のRPMパッケージを配置してください。 rootユーザでrpmコマンドを用いてパッケージをインストールします。サーバパッケージ「griddb-xx-server」を最初にインストールしてください。
[実行例]
# rpm -Uvh griddb-xx-server-X.X.X-linux.x86_64.rpm
準備中... ########################################### [100%]
User gsadm and group gridstore have been registered.
GridDB uses new user and group.
1:griddb-xx-server ########################################### [100%]
#
# rpm -Uvh griddb-xx-client-X.X.X-linux.x86_64.rpm
準備中... ########################################### [100%]
User and group has already been registered correctly.
GridDB uses existing user and group.
1:griddb-xx-client ########################################### [100%]
#
# rpm -Uvh griddb-xx-java_lib-X.X.X-linux.x86_64.rpm
準備中... ########################################### [100%]
1:griddb-xx-java_lib ########################################### [100%]
#
# rpm -Uvh griddb-xx-c_lib-X.X.X-linux.x86_64.rpm
準備中... ########################################### [100%]
1:griddb-xx-c_lib ########################################### [100%]
#
# rpm -Uvh griddb-xx-newsql-X.X.X-linux.x86_64.rpm
準備中... ########################################### [100%]
1:griddb-xx-newsql ########################################### [100%]
2.2.2 インストール後のユーザやディレクトリ構成
GridDBパッケージのインストールを行うと、以下のようなユーザやディレクトリ構成が作成されます。
ユーザ
OSのグループgridstoreとユーザgsadmが作成されます。ユーザgsadmは、GridDBを運用するためのユーザとして使用します。
| ユーザ | 所属グループ | ホームディレクトリ |
|---|---|---|
| gsadm | gridstore | /var/lib/gridstore |
ユーザgsadmには、以下の環境変数が定義されます。
| 環境変数 | 値 | 意味 |
|---|---|---|
| GS_HOME | /var/lib/gridstore | ユーザgsadm/GridDBホームディレクトリ |
| GS_LOG | /var/lib/gridstore/log | ノードのイベントログファイルの出力ディレクトリ |
ディレクトリ構成
ノードの定義ファイルやデータベースファイルなどを配置するGridDBホームディレクトリと、インストールしたファイルを配置するインストールディレクトリが作成されます。
GridDBホームディレクトリ
/var/lib/gridstore/ # GridDBホームディレクトリ
admin/ # 統合運用管理GUIホームディレクトリ
archive/ # 長期アーカイブツール用ディレクトリ
backup/ # バックアップディレクトリ
conf/ # 定義ファイルディレクトリ
gs_cluster.json # クラスタ定義ファイル
gs_node.json # ノード定義ファイル
password # ユーザ定義ファイル
data/ # データベースファイルディレクトリ
expimp/ # Export/Importツール用ディレクトリ
log/ # ログディレクトリ
webapi/ # Web API用ディレクトリ
インストールディレクトリ
/usr/griddb/ # インストールディレクトリ
Readme.txt
bin/ # 運用コマンド、モジュールディレクトリ
conf/ # 定義ファイルの雛形ディレクトリ
gs_cluster.json.tmpl # クラスタ定義ファイルの雛形
gs_cluster.json.tmpl # ノード定義ファイルの雛形
password.tmpl # ユーザ定義ファイルの雛形
etc/
lib/ # ライブラリディレクトリ
license/ # ライセンスディレクトリ
prop/ # 設定ファイルディレクトリ
sample/ # サンプルプログラム
web/ # 統合運用管理GUIファイルディレクトリ
[メモ]
- ノードを起動したりツールを実行したりすると、データベースファイルやログファイルが以下のディレクトリに作成されます。
/var/lib/gridstore/data # データベースファイルディレクトリ /var/lib/gridstore/log # ログディレクトリ
2.3 環境設定
2.3.1 ネットワークの設定
GridDBでは、クラスタを構成する際にマルチキャスト通信を使用します。マルチキャスト通信を可能にするためのネットワークの設定を行います。
まず、ホスト名とIPアドレスの対応付けを確認します。ホストとIPアドレスの設定を確認する「hostname -i」コマンドを実行してください。以下のようにマシンのIPアドレスが表示される場合は設定済みですので、本節のネットワーク設定の作業は不要です。
- [実行例]
$ hostname -i 192.168.11.10
以下のようなメッセージやループバックアドレス127.0.0.1が表示される場合は、設定が行われていません。以下の1から3の手順を実施してください。
- [実行例]
または$ hostname -i hostname: 名前に対応するアドレスがありません$ hostname -i 127.0.0.1
ネットワークの設定手順
- OSで設定されているホスト名とIPアドレスを確認する
ホスト名を確認します
[実行例]
$ hostname MY_HOSTIPアドレスを確認します
[実行例]
$ ip -f inet -o addr show eth0 | cut -d' ' -f 7 | cut -d/ -f 1 192.168.11.10
- ホスト名とIPアドレスの対応付けを設定する
1で確認したホスト名とIPアドレスを、rootユーザで/etc/hostsファイルに追加します。
[ファイルの記述例]
192.168.11.10 MY_HOST
- 設定されたことを確認する
ホストとIPアドレスの設定を確認する「hostname -i」コマンドを実行してください。2で指定したIPアドレスが表示されることを確認してください。
[実行例]
$ hostname -i 192.168.11.10
2.3.2 ノードのパラメータの設定
インストール後にGridDBを動作させるためには、アドレスやクラスタ名などのパラメータの初期設定が必要です。本ガイドでは、必須項目の「クラスタ名」のみ設定を行い、それ以外はデフォルト値を用います。
クラスタの「クラスタ名」をクラスタ定義ファイルに記述します。クラスタ定義ファイルは「/var/lib/gridstore/conf/gs_cluster.json」です。
「"clusterName":""」の部分にクラスタ名を記載します。本書では、「myCluster」という名前を用います。
[ファイルの記述例]
{
"dataStore":{
"partitionNum":128,
"storeBlockSize":"64KB"
},
"cluster":{
"clusterName":"myCluster",
"replicationNum":2,
・・・省略
[メモ]
- クラスタ名はサブネットワーク上で一意となる名前にすることを推奨します。
- クラスタ名は1文字以上のASCII英数字ならびにアンダースコア「_」の列で構成されます。ただし、先頭の文字には数字を指定できません。また、大文字・小文字は区別されません。また、64文字以内で指定する必要があります。
2.3.3 設定内容
ネットワーク設定とクラスタ名以外は、デフォルト値の設定のままで動作することができます。以下に主な設定項目を示します。これ以降のツールの実行などでは、以下の値を用います。
| 設定項目 | 値 |
|---|---|
| IPアドレス | "hostname -i"コマンドで表示されるIPアドレス |
| クラスタ名 | myCluster |
| マルチキャストアドレス | 239.0.0.1 (デフォルト値) |
| マルチキャストポート番号 | 31999 (デフォルト値) |
| ユーザ名 | admin (デフォルト値) |
| ユーザパスワード | admin (デフォルト値) |
| SQLマルチキャストアドレス(AEのみ) | 239.0.0.1 (デフォルト値) |
| SQLマルチキャストポート番号(AEのみ) | 41999 (デフォルト値) |
2.3.4 運用ツールの初期設定
運用ツールの中には初期設定が必要なものがあります。本節では、データ操作で用いるgs_shとgs_importの初期設定を行います。(ツールを使用しない場合は、本節の設定は不要です。)
2.3.4.1 gs_shコマンドの設定
gs_shはGridDBのクラスタ操作やデータ操作のためのコマンドラインインターフェイスです。クラスタの構成ノードに対する一括した操作や、コンテナの作成、TQLやSQL検索などのデータ操作の機能を提供します。
gs_shコマンドを利用する前に、gs_shの設定ファイル「/var/lib/gridstore/.gsshrc」にクラスタの接続情報情報を設定しておきます。
クラスタの接続先アドレスや接続するユーザの名前を、setclusterサブコマンドとsetuserサブコマンドを用いて定義します。クラスタ変数名とクラスタ名以外は、デフォルトの値を指定します。以下のように「/var/lib/gridstore/.gsshrc」ファイルに記載してください。
[ファイルの記載例]
setcluster cluster myCluster 239.0.0.1 31999
setuser admin admin
クラスタ情報定義サブコマンド
- setcluster <クラスタ変数名> <クラスタ名> <マルチキャストアドレス> <ポート番号>
- クラスタ変数名: cluster
- クラスタ名: myCluster
- マルチキャストアドレス: 239.0.0.1 (デフォルト値)
- マルチキャストポート番号: 31999 (デフォルト値)
- setcluster <クラスタ変数名> <クラスタ名> <マルチキャストアドレス> <ポート番号>
ユーザ情報定義サブコマンド
- setuser <ユーザ名> <パスワード>
- ユーザ名: admin (デフォルト値)
- パスワード: admin (デフォルト値)
- setuser <ユーザ名> <パスワード>
GridDB AEの場合は、SQLの接続先情報も定義します。クラスタ変数名とクラスタ名以外は、デフォルトの値を指定します。以下のようにファイルに記載してください。
[ファイルの記載例]
setcluster cluster myCluster 239.0.0.1 31999
setclustersql cluster myCluster 239.0.0.1 41999
setuser admin admin
- クラスタ情報(SQL)定義サブコマンド
- setclustersql <クラスタ変数名> <クラスタ名> <SQLアドレス> <SQLポート番号>
- クラスタ変数名: cluster
- クラスタ名: myCluster
- SQLアドレス: 239.0.0.1 (デフォルト値)
- SQLポート番号: 41999 (デフォルト値)
- setclustersql <クラスタ変数名> <クラスタ名> <SQLアドレス> <SQLポート番号>
2.3.4.2 gs_importコマンドの設定
gs_importは、コンテナにデータをインポートするためのコマンドです。
利用する前に、クラスタのアドレスなどの情報をプロパティファイルに記載します。プロパティファイルは「/var/lib/gridstore/expimp/conf/gs_expimp.properties」です。
プロパティファイル内の「clusterName=」の部分にクラスタ名(ここでは「myCluster」)を記載します。
[ファイルの記載例]
clusterName=myCluster
mode=MULTICAST
hostAddress=239.0.0.1
hostPort=31999
・・・(省略)
3 起動/停止
GridDBノードの起動/停止および、クラスタの開始/停止を行います。起動や停止の操作方法はいくつかありますが、運用コマンドを使った操作方法を紹介します。
運用コマンド一覧
| コマンド | 機能 |
|---|---|
| gs_startnode | ノードを起動する |
| gs_joincluster | ノードをクラスタに参加する |
| gs_leavecluster | クラスタからノードを離脱させる |
| gs_stopcluster | クラスタを停止する |
| gs_stopnode | ノードを停止する(シャットダウン) |
| gs_stat | ノードの内部情報を取得する |
【注意点】
- 運用コマンドはgsadmユーザで実行してください。
- 例
# su - gsadm $ pwd /var/lib/gridstore
- 例
- プロキシ変数(http_proxy)が設定されている場合、ノードのアドレス(群)を、no_proxyで設定し、proxyから除外してください。運用コマンドはREST/http通信を行うため、誤ってproxyサーバ側に接続されてしまい、運用コマンドが動作しません。
- 設定例
$ export no_proxy=localhost,127.0.0.1,192.168.10.11,192.168.10.12,192.168.10.13
- 設定例
3.1 起動操作
GridDBノードのインストールおよびセットアップを行った後、GridDBクラスタの起動の流れは以下のようになります。
- ノードを起動する
- クラスタを開始する
「ノードとクラスタ」で説明した通り、GridDBクラスタはユーザが指定した構成ノード数分のノードがクラスタへ参加することで構成され、サービスが開始されます。構成ノード数のノードすべてがクラスタに参加するまで、クラスタサービスは開始されず、アプリケーションからはクラスタにアクセスすることはできません。
今回説明するのは、ノード1台で利用する「シングル構成」です。ノードを1台起動したのち、起動したノードをクラスタに参加させて、クラスタを開始します。
3.1.1 ノードを起動する
ノードの起動には以下のコマンドを用います。
gs_startnode -u ユーザ名/パスワード -w
- ユーザ認証オプション-uには管理ユーザadminのユーザ名とパスワードを指定し、ノードの起動を待ち合せる-wオプションを指定します。
[実行例]
$ gs_startnode -u admin/admin -w
3.1.2 クラスタを開始する
各ノードでクラスタ参加コマンドを実行し、クラスタを開始します。クラスタの開始には以下のコマンドを用います。
gs_joincluster -u ユーザ名/パスワード -w -c クラスタ名
- ユーザ認証オプション-uには管理ユーザadminのユーザ名とパスワードを指定し、クラスタの開始を待ち合せる-wオプションを指定します。クラスタ名を-cオプションで指定します。
[実行例]
$ gs_joincluster -u admin/admin –w -c myCluster
クラスタ開始後、クラスタの状態を確認します。状態の確認には以下のコマンドを使います。
gs_stat -u ユーザ名/パスワード
- ユーザ認証オプション-uには管理ユーザadminのユーザ名とパスワードを指定します。また、クラスタのステータスを確認するために、"Status"の表記の行のみをgrepで抽出します。
[実行例]
$ gs_stat -u admin/admin | grep Status
"clusterStatus": "MASTER",
"nodeStatus": "ACTIVE",
"partitionStatus": "NORMAL"
「gs_stat」で表示される3つのステータスが「実行例」のように表示されていれば、正常に起動しています。アプリケーションからクラスタにアクセスが可能になります。
3.2 停止操作
3.2.1 基本の流れ
GridDBクラスタの停止の流れは以下のようになります。
- クラスタを停止する
- ノードを停止する
起動の流れとは逆に、クラスタを安全に停止してから、各ノードを停止します。クラスタを停止した段階で、アプリケーションからはクラスタにアクセスできなくなります。
3.2.2 クラスタを停止する
クラスタ停止コマンドを実行します。クラスタ停止コマンドを実行した時点で、アプリケーションからはクラスタにアクセスできなくなります。
gs_stopcluster -u ユーザ名/パスワード -w
- ユーザ認証オプション-uには管理ユーザadminのユーザ名とパスワードを指定し、クラスタの停止を待ち合せる-wオプションを指定します。
[実行例]
$ gs_stopcluster -u admin/admin -w
3.2.3 ノードを停止する
ノード停止コマンドを実行し、ノードを停止(シャットダウン)します。必ず、クラスタを停止してからノードを停止します。
gs_stopnode -u ユーザ名/パスワード -w
- ユーザ認証オプション-uには管理ユーザadminのユーザ名とパスワードを指定し、ノードの停止を待ち合せる-wオプションを指定します。
[実行例]
$ gs_stopnode -u admin/admin -w
4 データ操作
GridDBのデータ操作を行ってみましょう。ここでは、gs_shコマンド、およびgs_importコマンドを使った、次の基本的な操作について説明します。
- クラスタに接続する (gs_shコマンドを使用)
- コンテナを作成する (gs_shコマンドを使用)
- ロウを登録する (gs_importコマンドを使用)
- TQL検索する (gs_shコマンドを使用)
- SQL検索する (gs_shコマンドを使用) (AE版の場合のみ)
4.1 クラスタに接続する
gs_shコマンドを使いクラスタに接続します。gs_shを起動すると「gs>」プロンプトが表示されて、サブコマンドの入力待ちになります。クラスタに接続する場合はサブコマンドは「connect」を使います。
- 接続サブコマンド
- connect <クラスタ変数>
- 第1引数:setclusterで定義したクラスタ変数:$cluster
- connect <クラスタ変数>
[実行例]
$ gs_sh
gs>
gs> connect $cluster
接続に成功しました(NoSQL)
gs[public]>
4.2 コンテナを作成する
4.2.1 コンテナとは
「データモデル-コンテナとロウを理解しましょう」で説明したように、GridDBでは、「コンテナ」と称される入れ物でデータを管理します。コンテナには、カラムやデータ型などのスキーマを定義します。アプリケーションでデータを登録する前には、必ずコンテナを作成しておく必要があります。
コンテナの種類
- コンテナには次の2種類があります。用途に応じて使い分けます。
- コレクション:一般的なデータを管理するためのコンテナ
- 時系列コンテナ:時系列データを管理するためのコンテナ
- コンテナには次の2種類があります。用途に応じて使い分けます。
カラムのデータ型
- カラムのデータ型には次の種類があります。
基本型
- ブール型 (BOOL型)
- 文字列型 (STRING型)
- 整数型
- BYTE型
- SHORT型
- INTEGER型
- LONG型
- 浮動小数点型
- FLOAT型
- DOUBLE型
- 時刻型 (TIMESTAMP型)
- 空間型 (GEOMETRY型)
- BLOB型
複合型
- 配列型
- ブール型、文字列型、整数型、浮動小数点型、時刻型の配列
- 配列型
- カラムのデータ型には次の種類があります。
4.2.2 コンテナを作成する
コンテナを作成してみましょう。ここでは、コンテナの種類は「コレクション」、カラムは「id」(型はinteger)と「value」(型はstring)であるコンテナを作成する操作を紹介します。
コレクション作成サブコマンド
- createcollection <コンテナ名> <カラム名> <カラムタイプ> [<カラム名> <カラムタイプ>...]
[実行例] サブコマンド「createcollection」を実行し、カラムは「id」(型はinteger)と「value」(型はstring)である、「mycollection」という名前のコンテナを作成する
gs[public]> createcollection mycollection id integer value stringコンテナ一覧表示サブコマンド
- showcontainer
[実行例]サブコマンド「showcontainer」を実行し、作成したコンテナを確認する
gs[public]> showcontainer Database : public Name Type PartitionId ---------------------------------------------------------------- mycollection COLLECTION 59 Total Count: 1
4.3 ロウを登録する
「ロウ」は、コンテナやテーブルに登録される1行のデータ指します。ここではサンプルデータをエクスポートし、ロウを登録しましょう。サンプルデータをインポートするために展開します。
[実行例]
$ cd /usr/griddb/sample/ja/data/
$ unzip impSample.zip
impSample/collectionのデータをインポートします。
[実行例]
$ cd impSample/collection
$ gs_import -u admin/admin --all
インポートを開始します
対象コンテナ数 : 1
public.c001 : 5
対象コンテナ数 : 1 ( 成功:1 失敗:0 )
インポートを終了しました
4.4 TQL検索を行う
コンテナに対してTQL検索を実行し、結果を表示します。TQL検索は、gs_shコマンドの「tql」と「get」のサブコマンドを使って行います。
- tql:TQL文でコンテナのロウを検索する
- get:TQLの結果を表示する
ここでは、「c001」という名前のコンテナに対して検索を行う操作を紹介します。
操作は、クラスタに接続したのちに行います。まず、サブコマンド「tql」を実行し、コンテナ(c001)に対してTQL検索を実行します。
TQL実行サブコマンド
- tql <コンテナ名> <クエリ>;
[実行例]
gs[public]> tql c001 select * where count > 20; 3 件ヒットしました。 (26 ms)
次に、サブコマンド「get」を実行して結果を表示します。
TQL実行結果の取得サブコマンド
- get
[実行例]
gs[public]> get name,status,count tokyo,false,100 iwate,false,30 akita,false,45 3 件の取得が完了しました。
4.5 SQL検索を行う (AE版のみ)
テーブルに対してSQL検索を実行し、結果を表示します。 SQL検索は、gs_shコマンドの「sql」と「get」のサブコマンドを使って行います。
- sql:SQL文でNewSQLデータ(テーブルと時系列テーブル)を検索する
- get:SQLの結果を表示する(検索結果の全件を表示する場合は、省略できます)
ここでは、「c001」という名前のコンテナに対して検索を行う操作を紹介します。操作は、クラスタに接続したのち、行います。サブコマンド「sql」を実行し、コンテナ(c001)に対してSQL検索を実行します。
SQL実行サブコマンド
- sql <SQL文>;
[実行例]
gs[public]> sql select * from c001 where count > 20 and count < 80; 2 件ヒットしました。 (179 ms)
次に、サブコマンド「get」を実行して結果を表示します。
SQL実行結果の取得サブコマンド
- get
[実行例]
gs[public]> get name,status,count iwate,false,30 akita,false,45 2 件の取得が完了しました。
5 サンプルプログラムの実行
Java APIとJDBCを用いたサンプルプログラムが用意されています。サンプルプログラムでプログラムのビルドおよび実行方法の例を説明します。
サンプルプログラムは、/usr/griddb/sampleにありますのでご利用ください。
5.1 Java APIを用いたサンプルプログラムの実行
Java APIを用いたサンプルプログラムを実行するためには、以下のパッケージをインストールしている必要があります。
- アプリケーション開発ライブラリ(Java)パッケージ:griddb-xx-java_lib
サンプルプログラムは、次のディレクトリにあります。
/usr/griddb/sample/ja/java
プログラムのコンパイル・実行の際には、以下のライブラリを環境変数CLASSPATHに指定します。
/usr/share/java/gridstore.jar
[実行例]
プログラムをコンパイルして実行します。
$ export CLASSPATH=${CLASSPATH}:/usr/share/java/gridstore.jar:.
$ javac TQLSelect.java
$ java TQLSelect
サンプルプログラム"TQLSelect.java"は、以下の処理を行うプログラムです。
- クラスタに接続する
- コンテナを作成する
- ロウを登録する
- TQLで検索する
import java.util.ArrayList;
import java.util.List;
import java.util.Properties;
import com.toshiba.mwcloud.gs.Collection;
import com.toshiba.mwcloud.gs.ColumnInfo;
import com.toshiba.mwcloud.gs.Container;
import com.toshiba.mwcloud.gs.ContainerInfo;
import com.toshiba.mwcloud.gs.GSType;
import com.toshiba.mwcloud.gs.GridStore;
import com.toshiba.mwcloud.gs.GridStoreFactory;
import com.toshiba.mwcloud.gs.Query;
import com.toshiba.mwcloud.gs.Row;
import com.toshiba.mwcloud.gs.RowSet;
public class TQLSelect {
public static void main(String[] args){
try {
//===============================================
// クラスタに接続する
//===============================================
// 接続情報を指定する (マルチキャスト方式)
Properties prop = new Properties();
prop.setProperty("notificationAddress", "239.0.0.1");
prop.setProperty("notificationPort", "31999");
prop.setProperty("clusterName", "myCluster");
prop.setProperty("database", "public");
prop.setProperty("user", "admin");
prop.setProperty("password", "admin");
prop.setProperty("applicationName", "SampleJava");
// GridStoreオブジェクトを生成する
GridStore store = GridStoreFactory.getInstance().getGridStore(prop);
// コンテナ作成や取得などの操作を行うと、クラスタに接続される
store.getContainer("dummyContainer");
//===============================================
// コンテナを作成する
//===============================================
String containerName = "SampleJava_TQLSelect";
createContainerPutRow(store, containerName);
//===============================================
// TQLで検索する
//===============================================
// (1)Containerオブジェクトの取得
Container<?, Row> container = store.getContainer(containerName);
if ( container == null ){
throw new Exception("Container not found.");
}
// (2)TQLで検索実行
Query<Row> query = container.query("SELECT * WHERE count >= 50 ORDER BY id");
RowSet<Row> rs = query.fetch();
// (3)結果をロウで取得
while ( rs.hasNext() ) {
Row row = rs.next();
int id = row.getInteger(0);
String name = row.getString(1);
int count = row.getInteger(2);
System.out.println("row id=" + id + ", name=" + name + ", count=" + count);
}
//===============================================
// 終了処理
//===============================================
rs.close();
query.close();
container.close();
store.close();
System.out.println("success!");
} catch ( Exception e ){
e.printStackTrace();
}
}
private static void createContainerPutRow(GridStore store, String containerName) throws Exception {
// コンテナを作成する
ContainerInfo containerInfo = new ContainerInfo();
List<ColumnInfo> columnList = new ArrayList<ColumnInfo>();
columnList.add(new ColumnInfo("id", GSType.INTEGER));
columnList.add(new ColumnInfo("productName", GSType.STRING));
columnList.add(new ColumnInfo("count", GSType.INTEGER));
containerInfo.setColumnInfoList(columnList);
containerInfo.setRowKeyAssigned(true);
Collection<Void, Row> collection = store.putCollection(containerName, containerInfo, false);
System.out.println("Create Collection name=" + containerName);
// ロウを登録する
String[] nameList = {"notebook PC", "desktop PC", "keyboard", "mouse", "printer"};
int[] numberList = {108, 72, 25, 45, 62};
List<Row> rowList = new ArrayList<Row>();
for ( int i = 0; i < nameList.length; i++ ){
Row row = collection.createRow();
row.setInteger(0, i);
row.setString(1, nameList[i]);
row.setInteger(2, numberList[i]);
rowList.add(row);
}
collection.put(rowList);
}
}5.2 C APIを用いたサンプルプログラムの実行
C APIを用いたサンプルプログラムを実行するためには、以下のパッケージをインストールしている必要があります。
- アプリケーション開発ライブラリ(C)パッケージ:griddb-xx-c_lib
サンプルプログラムは、次のディレクトリにあります。
/usr/griddb/sample/ja/c
プログラムのコンパイル・実行の際には、以下のライブラリを環境変数LD_LIBRARY_PATHに指定します。
/usr/lib64
[実行例]
プログラムをコンパイルして実行します。
$ export LD_LIBRARY_PATH=${LD_LIBRARY_PATH}:/usr/lib64
$ gcc -lgridstore -o TQLSelect TQLSelect.c
$ ./TQLSelect
サンプルプログラム"TQLSelect.c"は、以下の処理を行うプログラムです。
- クラスタに接続する
- コンテナを作成する
- ロウを登録する
- TQL検索を実行する
#include "gridstore.h"
#include <stdlib.h>
#include <stdio.h>
void main(int argc, char *argv[]){
/* 定数 */
// コンテナ名
const GSChar * containerName = "SampleC_TQLSelect";
// 登録するロウのデータ (コンテナのロウ数 5)
const int rowCount = 5;
const GSChar * nameList[5] = {"notebook PC", "desktop PC", "keyboard", "mouse", "printer"};
const int numberList[5] = {108, 72, 25, 45, 62};
// TQLクエリ
const GSChar * queryStr = "SELECT * WHERE count >= 50 ORDER BY id";
/* 変数 */
GSGridStore *store = NULL;
GSContainer *container;
GSResult ret;
int i;
int j;
// コンテナ作成用
GSContainerInfo info0 = GS_CONTAINER_INFO_INITIALIZER;
GSColumnInfo columnInfo = GS_COLUMN_INFO_INITIALIZER;
GSColumnInfo columnInfoList[3]; // カラム数 3
// ロウ登録用
GSRow *row;
GSRow * rowList[5];
const void * const * rowObj;
// エラー処理用
size_t stackSize;
GSResult errorCode;
GSChar errMsgBuf1[1024], errMsgBuf2[1024]; // エラーメッセージを格納するバッファ
// 検索用
GSQuery *query;
GSRowSet *rs;
GSBool exist;
//===============================================
// クラスタに接続する
//===============================================
// 接続情報を指定する (マルチキャスト方式)
const GSPropertyEntry props[] = {
{ "notificationAddress", "239.0.0.1" },
{ "notificationPort", "31999" },
{ "clusterName", "myCluster" },
{ "database", "public" },
{ "user", "admin" },
{ "password", "admin" },
{ "applicationName", "SampleC" }
};
const size_t propCount = sizeof(props) / sizeof(*props);
// GridStoreインスタンスを取得する
ret = gsGetGridStore(gsGetDefaultFactory(), props, propCount, &store);
if ( !GS_SUCCEEDED(ret) ){
fprintf(stderr, "ERROR gsGetGridStore\n");
goto LABEL_ERROR;
}
// コンテナ作成や取得などの操作を行うと、クラスタに接続される
ret = gsGetContainerGeneral(store, "containerName", &container);
if ( !GS_SUCCEEDED(ret) ){
fprintf(stderr, "ERROR gsGetContainerGeneral\n");
goto LABEL_ERROR;
}
gsCloseContainer(&container, GS_TRUE);
printf("Connect to Cluster\n");
//===============================================
// データ準備 (コンテナ作成&ロウ登録)
//===============================================
{
// コンテナ情報を設定する
info0.type = GS_CONTAINER_COLLECTION;
info0.rowKeyAssigned = GS_TRUE;
columnInfo.name = "id";
columnInfo.type = GS_TYPE_INTEGER;
columnInfoList[0] = columnInfo;
columnInfo.name = "productName";
columnInfo.type = GS_TYPE_STRING;
columnInfoList[1] = columnInfo;
columnInfo.name = "count";
columnInfo.type = GS_TYPE_INTEGER;
columnInfoList[2] = columnInfo;
info0.columnCount = sizeof(columnInfoList) / sizeof(*columnInfoList);
info0.columnInfoList = columnInfoList;
// コレクションを作成する
ret = gsPutContainerGeneral(store, containerName, &info0, GS_FALSE, &container);
if ( !GS_SUCCEEDED(ret) ){
fprintf(stderr, "ERROR gsPutCollectionGeneral\n");
goto LABEL_ERROR;
}
printf("Sample data generation: Create Collection name=%s\n", containerName);
for ( i = 0; i < rowCount; i++ ){
// 空のロウオブジェクトを生成する
gsCreateRowByContainer(container, &row);
// ロウオブジェクトに値をセットする
gsSetRowFieldByInteger(row, 0, i);
gsSetRowFieldByString(row, 1, nameList[i]);
gsSetRowFieldByInteger(row, 2, numberList[i]);
rowList[i] = row;
}
rowObj = (void *)rowList;
// 複数のロウを登録する
ret = gsPutMultipleRows(container, rowObj, rowCount, NULL);
if ( !GS_SUCCEEDED(ret) ){
fprintf(stderr, "ERROR gsPutMultipleRows\n");
goto LABEL_ERROR;
}
printf("Sample data generation: Put Rows count=%d\n", rowCount);
gsCloseContainer(&container, GS_TRUE);
}
//===============================================
// TQLで検索する
//===============================================
// (1)コンテナを取得する
ret = gsGetContainerGeneral(store, containerName, &container);
if ( !GS_SUCCEEDED(ret) ){
fprintf(stderr, "ERROR gsGetContainerGeneral\n");
goto LABEL_ERROR;
}
if ( container == NULL ){
fprintf(stderr, "ERROR Container not found. name=%s\n", containerName);
goto LABEL_ERROR;
}
// (2)TQLで検索実行
printf("TQL query : %s\n", queryStr);
ret = gsQuery(container, queryStr, &query);
if ( !GS_SUCCEEDED(ret) ){
fprintf(stderr, "ERROR gsQuery\n");
goto LABEL_ERROR;
}
ret = gsFetch(query, GS_FALSE, &rs);
if ( !GS_SUCCEEDED(ret) ){
fprintf(stderr, "ERROR gsFetch\n");
goto LABEL_ERROR;
}
// (3)空のロウを作成
gsCreateRowByContainer(container, &row);
// (4)結果を取得する
while (gsHasNextRow(rs)) {
int id;
const GSChar *productName;
int count;
// (5)ロウを取得する
ret = gsGetNextRow(rs, row);
if ( !GS_SUCCEEDED(ret) ){
fprintf(stderr, "ERROR gsGetNextRow\n");
goto LABEL_ERROR;
}
gsGetRowFieldAsInteger(row, 0, &id);
gsGetRowFieldAsString(row, 1, &productName);
gsGetRowFieldAsInteger(row, 2, &count);
printf("TQL result: id=%d, productName=%s, count=%d\n", id, productName, count);
}
//===============================================
// 終了処理
//===============================================
// リソースを解放する
gsCloseGridStore(&store, GS_TRUE);
printf("success!\n");
return;
LABEL_ERROR:
//===============================================
// エラー処理
//===============================================
// エラーコードとエラーメッセージを出力する
stackSize = gsGetErrorStackSize(store);
for ( i = 0; i < stackSize; i++ ){
errorCode = gsGetErrorCode(store, i);
gsFormatErrorMessage(store, i, errMsgBuf1, sizeof(errMsgBuf1));
gsFormatErrorLocation(store, i, errMsgBuf2, sizeof(errMsgBuf2));
fprintf(stderr, "[%d] %s (%s)\n", errorCode, errMsgBuf1, errMsgBuf2);
}
// リソースを解放する
gsCloseGridStore(&store, GS_TRUE);
return;
}5.3 JDBCを用いたサンプルプログラムの実行
JDBC APIを用いたサンプルプログラムを実行するためには、以下のパッケージをインストールしている必要があります。
- アプリケーション開発ライブラリ(NewSQL)パッケージ:griddb-xx-newsql
サンプルプログラムは、次のディレクトリにあります。
/usr/griddb-ae-newsql-X.X.X/sample/ja/jdbc/
※: X.X.XはGridDBのバージョン
プログラムのコンパイル・実行の際には、以下のライブラリを環境変数CLASSPATHに指定します。
/usr/share/java/gridstore-jdbc.jar
[実行例]
プログラムをコンパイルして実行します。
$ export CLASSPATH=${CLASSPATH}:/usr/share/java/gridstore-jdbc.jar:.
$ javac JDBCSelect.java
$ java JDBCSelect
サンプルプログラム"JDBCSelect.java"は、以下の処理を行うプログラムです。
- クラスタに接続する
- コンテナを作成する
- ロウを登録する
- SQLで検索を実行する
import java.net.URLEncoder;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.Statement;
import java.util.Properties;
public class JDBCSelect {
public static void main(String[] args){
try {
//===============================================
// クラスタに接続する
//===============================================
// JDBCの接続情報
String jdbcAddress = "239.0.0.1";
String jdbcPort = "41999";
String clusterName = "myCluster";
String databaseName = "public";
String username = "admin";
String password = "admin";
String applicationName = "SampleJDBC";
// クラスタ名とデータベース名はエンコードする
String encodeClusterName = URLEncoder.encode(clusterName, "UTF-8");
String encodeDatabaseName = URLEncoder.encode(databaseName, "UTF-8");
// URLを組み立てる (マルチキャスト方式)
String jdbcUrl = "jdbc:gs://"+jdbcAddress+":"+jdbcPort+"/"+encodeClusterName+"/"+encodeDatabaseName;
Properties prop = new Properties();
prop.setProperty("user", username);
prop.setProperty("password", password);
prop.setProperty("applicationName", applicationName);
// 接続する
Connection con = DriverManager.getConnection(jdbcUrl, prop);
//===============================================
// コンテナ作成とデータ登録
//===============================================
{
Statement stmt = con.createStatement();
// (存在した場合は削除する)
stmt.executeUpdate("DROP TABLE IF EXISTS SampleJDBC_Select");
// コンテナ作成
stmt.executeUpdate("CREATE TABLE IF NOT EXISTS SampleJDBC_Select ( id integer PRIMARY KEY, value string )");
System.out.println("SQL Create Table name=SampleJDBC_Select");
// ロウ登録
int ret1 = stmt.executeUpdate("INSERT INTO SampleJDBC_Select values "+
"(0, 'test0'),(1, 'test1'),(2, 'test2'),(3, 'test3'),(4, 'test4')");
System.out.println("SQL Insert count=" + ret1);
stmt.close();
}
//===============================================
// 検索の実行
//===============================================
// (1)ステートメント作成
Statement stmt = con.createStatement();
// (2)SQL実行
ResultSet rs = stmt.executeQuery("SELECT * from SampleJDBC_Select where ID > 2");
// (3)結果の取得
while( rs.next() ){
int id = rs.getInt(1);
String value = rs.getString(2);
System.out.println("SQL row(id=" + id + ", value=" + value + ")");
}
//===============================================
// 終了処理
//===============================================
stmt.close();
con.close();
System.out.println("success!");
} catch ( Exception e ){
e.printStackTrace();
}
}
}
6 GridDBのアンインストール
GridDBが不要となった場合には全てのパッケージをアンインストールします。root権限で、以下の手順でアンインストールを実行してください。
[実行例]
# rpm -e griddb-xx-server
# rpm -e griddb-xx-client
# rpm -e griddb-xx-java_lib
# rpm -e griddb-xx-c_lib
# rpm -e griddb-xx-newsql (AEのみ)
※: xxはGridDBのエディション(se, ae)
[注意点]
- 定義ファイルやデータファイルなど、GridDBホームディレクトリ下のファイルはアンインストールされません。不要な場合は手動で削除して下さい。