GridDB Advanced Edition SQLリファレンス
Revision: 2203
Table of Contents
1 はじめに
1.1 本書の目的と構成
本書では、GridDB Advanced EditionにおけるSQLの記述方法および、注意事項について記載しています。GridDB Advanced Editionをご使用になる前に、必ずお読みください。
なお、本書で説明する機能は、GridDB Advanced Editionライセンスを保有するユーザのみがご利用いただけます。
1.2 GridDB Advanced Editionとは
GridDB Advanced Editionでは、GridDBのデータにSQLでアクセスできるインターフェイス(NewSQLインターフェイス)を提供します。
本書では、GridDB Advanced Edition(以降GridDB AEと記載します)のサポートするデータベースにアクセスするためのNewSQLインターフェイスのSQLについて説明します。NoSQLインターフェイスとは異なるインターフェイスですのでご注意ください。
NewSQLインターフェイスは、NoSQLインターフェイスで作成したコンテナをテーブルとみなして参照・更新可能です。更新には行の更新だけでなく、コンテナのスキーマや索引の変更を含みます。また、NewSQLインターフェイスで作成したテーブルは、コンテナとしてNoSQLインターフェイスで参照・更新可能です。
また、JDBCドライバの使用方法は、『GridDB Advanced Edition JDBCドライバ説明書』(GridDB_AE_JDBC_DriverGuide.html)を参照してください。
2 SQL記述形式
本章では、NewSQLインタフェースで使用できるSQLの記述形式について示します。
2.1 使用できる操作
SELECT文の他、CREATE TABLE等のDDL(Data Definition Language、データ定義言語)やINSERT/DELETE文などをサポートしています。詳細はGridDB AEでサポートされるSQL文を参照して下さい。
2.2 データ型
2.2.1 データ格納に使用する型
NewSQLインターフェイスでデータの格納に使用する型は次のとおりです。この型名はテーブル作成時にカラム型として記述できます。
| データ型 | 内容詳細 |
|---|---|
| BOOL型 | True/False |
| BYTE型 | -27から27-1 (8ビット)の整数値 |
| SHORT型 | -215から215-1 (16ビット)の整数値 |
| INTEGER型 | -231から231-1 (32ビット)の整数値 |
| LONG型 | -263から263-1 (64ビット)の整数値 |
| FLOAT型 | 単精度型(32ビット) IEEE754で定められた浮動小数点数 |
| DOUBLE型 | 倍精度型(64ビット) IEEE754で定められた浮動小数点数 |
| TIMESTAMP型 | 日付と時刻の組。日付のみ、時刻のみの値を格納・取得する場合、 |
| 時刻00:00:00または、日付1970-01-01が指定されたとみなす。 | |
| STRING型 | Unicodeコードポイントを文字とする、任意個数の文字の列より構成されるテキスト文字 |
| BLOB型 | 画像や音声などのバイナリデータのためのデータ型。 |
| 入力したままの形式で保存されるラージオブジェクト。 | |
| 文字xあるいはXをつけて、X'23AB'のような16進表現もできる。 |
また、テーブルにNULL値を格納することができます。NULL値に対して“IS NULL”などの演算子を使用すると、SQL仕様に沿った結果を返却します。
2.2.2 テーブル作成時にカラム型として記述可能な表現
NewSQLインターフェイスでは、テーブル作成時にカラム型として記述された型名について、 データ格納に使用する型で列挙した型名と一致しなくても、ルールに従って解釈しデータの格納に使用する型を決定します。
以下のルールを上から順にチェックし、合致したルールによってデータ格納に使用する型を決定します。ルールのチェック時には記述した型名およびルールでチェックする文字列の大文字小文字は区別しません。複数のルールに合致した場合はより上にあるルールが優先されます。どのルールにも当てはまらない場合はエラーとなりテーブル作成に失敗します。
| ルールNo. | テーブル作成時、カラム型として記述した文字列 | 作成するテーブルのカラム型 |
|---|---|---|
| 1 | データ格納に使用する型に列挙した型名 | テーブル作成時に指定された型に従う |
| 2 | "REAL" | DOUBLE型 |
| 3 | "TINYINT" | BYTE型 |
| 4 | "SMALLINT" | SHORT型 |
| 5 | "BIGINT" | LONG型 |
| 6 | "INT"を含む型名 | INTEGER型 |
| 7 | "CHAR", "CLOB", "TEXT"のどれかを含む型名 | STRING型 |
| 8 | "BLOB"を含む型名 | BLOB型 |
| 9 | "REAL", "DOUB"のどれかを含む型名 | DOUBLE型 |
| 10 | "FLOA"を含む型名 | FLOAT型 |
上記ルールによるデータ型決定の例を示します。
- 記述した型名が"BIGINTEGER"→INTEGER型(ルール6)
- 記述した型名が"LONG"→LONG型(ルール1)
- 記述した型名が"TINYINT"→BYTE型(ルール3)
- 記述した型名が"FLOAT"→FLOAT型(ルール1)
- 記述した型名が"VARCHAR"→STRING型(ルール7)
- 記述した型名が"CHARINT"→INTEGER型(ルール6)
- 記述した型名が"BIGBLOB"→BLOB型(ルール8)
- 記述した型名が"FLOATDOUB"→DOUBLE型(ルール9)
- 記述した型名が"INTREAL"→INTEGER型(ルール6)
- 記述した型名が"FLOATINGPOINT"→INTEGER型(ルール6)
- 記述した型名が"DECIMAL"→エラー
NoSQLインターフェイスのクライアントにおけるデータ型と同等の型をNewSQLインターフェイスで使用する場合は以下のように記述してください。ただし一部同等の型が存在せず、使用できないものがあります。
| NoSQLインターフェイスのデータ型 | 同等の型となるNewSQLインターフェイスのカラム型記述 |
|---|---|
| STRING(文字列型) | "STRING" または "STRING型となる表現" |
| BOOL(ブール型) | "BOOL" |
| BYTE(8ビット整数型) | "BYTE" または "BYTE型となる表現" |
| SHORT(16ビット整数型) | "SHORT" または "SHORT型となる表現" |
| INTEGER(32ビット整数型) | "INTEGER" または "INTEGER型となる表現" |
| LONG(64ビット整数型) | "LONG" または "LONG型となる表現" |
| FLOAT(32ビット単精度浮動小数点数型) | "FLOAT" または "FLOAT型となる表現" |
| DOUBLE(64ビット倍精度浮動小数点数型) | "DOUBLE" または "DOUBLE型となる表現" |
| TIMESTAMP(時刻型) | "TIMESTAMP" |
| GEOMETRY(空間型) | 存在しません(使用できません) |
| BLOB型 | "BLOB" または "BLOB型となる表現" |
| 配列型 | 存在しません(使用できません) |
2.2.3 コンテナをテーブルとしてアクセスするときのデータ型と値の扱い
NoSQLインタフェースのクライアントで作成したコンテナを、NewSQLインタフェースでテーブルとしてアクセスする場合のコンテナのカラム型および値の扱いを以下に示します。
| コンテナのカラム型 | NewSQLにマッピングされるデータ型 | 値 |
|---|---|---|
| STRING型 | STRING型 | 元の値と同一 |
| BOOL型 | BOOL型 | 元の値と同一 |
| BYTE型 | BYTE型 | 元の値と同一 |
| SHORT型 | SHORT型 | 元の値と同一 |
| INTEGER型 | INTEGER型 | 元の値と同一 |
| LONG型 | LONG型 | 元の値と同一 |
| FLOAT型 | FLOAT型 | 元の値と同一 |
| DOUBLE型 | DOUBLE型 | 元の値と同一 |
| TIMESTAMP型 | TIMESTAMP型 | 元の値と同一 |
| GEOMETRY型 | STRING型 | 全ての値がNULL |
| BLOB型 | BLOB型 | 元の値と同一 |
| 配列型 | STRING型 | 全ての値がNULL |
2.3 ユーザとデータベース
GridDBのユーザには、管理ユーザと一般ユーザの2種類があり、利用できる機能に違いがあります。また、データベースを作成することで、利用ユーザ単位にアクセスを分離することができます。ユーザ、データベースの詳細は『GridDB テクニカルリファレンス』(GridDB_TechnicalReference.html)を参照ください。
2.4 ネーミングの規則
ネーミングの規則は次のとおりです。
- データベース名・テーブル名・列名・索引名および一般ユーザ名は、1文字以上のASCII英数字ならびにアンダースコア「_」、ハイフン「-」、ドット「.」、スラッシュ「/」、イコール「=」の列で構成されます。
- 名前先頭の文字に数字、または、名前にアンダースコア以外の記号を用いる場合には引用符"で囲んでください。
- テーブル名にはノードアフィニティ機能向けに「@」の文字も指定できます。
ノードアフィニティ機能、ネーミングの規則・制限についての詳細は、『GridDB テクニカルリファレンス』(GridDB_TechnicalReference.html)を参照ください。
3 GridDB AEでサポートされるSQL文
サポートされるSQL文は、次のとおりです。
| コマンド | 概要 |
|---|---|
| CREATE DATABASE | データベースを作成する。 |
| CREATE TABLE | テーブルを作成する。 |
| CREATE INDEX | 索引を作成する。 |
| CREATE USER | 一般ユーザを作成する。 |
| DROP DATABASE | データベースを削除する。 |
| DROP TABLE | テーブルを削除する。 |
| DROP INDEX | 索引を削除する。 |
| DROP USER | 一般ユーザを削除する。 |
| SET PASSWORD | 一般ユーザのパスワードを変更する。 |
| ALTER TABLE | テーブルの構造を変更します。 |
| GRANT | 一般ユーザにデータベースへのアクセス権を設定する。 |
| REVOKE | 一般ユーザからデータベースへのアクセス権を削除する。 |
| SELECT | データを取得する。 |
| INSERT | テーブルに行を挿入する。 |
| DELETE | テーブルから行を削除する。 |
| UPDATE | テーブルにある行を更新する。 |
| コメント | コメントを表記する。 |
| ヒント | 実行計画を制御する。 |
本章では、SQL文の分類ごとに説明を行います。
3.1 データ定義言語(DDL)
3.1.1 CREATE DATABASE
データベースを作成します。
構文
CREATE DATABASE データベース名;
仕様
- 管理ユーザのみが実行可能です。
- 「public」、「information_schema」と同一の名前のデータベースは、GridDBの内部用に予約済みのため作成できません。
- 既に同一の名前のデータベースが存在した場合は何も変更しません。
- データベース名の規則はネーミングの規則を参照ください。
3.1.2 CREATE TABLE
3.1.2.1 テーブルの作成
テーブルを作成します。
構文
-- テーブル(コレクション)
CREATE TABLE [IF NOT EXISTS] テーブル名 ( 列定義 [, 列定義 ...] );
-- 時系列テーブル(時系列コンテナ)
CREATE TABLE [IF NOT EXISTS] テーブル名 ( 列名 TIMESTAMP PRIMARY KEY [, 列定義 ...] )
USING TIMESERIES [WITH (プロパティキー=プロパティ値 [, プロパティキー=プロパティ値 ...])];
列定義
- 列名 型名 [ 列制約 ]
列制約
- PRIMARY KEY (先頭の列のみ指定可)
- NULL
- NOT NULL
仕様
- テーブル名、列名の規則はネーミングの規則を参照ください。
- “IF NOT EXISTS”が指定された場合、指定したテーブル名と同じ名前のテーブルが存在しないときのみ作成します。
- 列定義 では、列名と型名の指定が必須です。指定可能な型名はデータ格納に使用する型を参照ください。
- 時系列テーブル(時系列コンテナ)については『GridDB テクニカルリファレンス』(GridDB_TechnicalReference.html)を参照ください。
-
時系列テーブルの場合、期限解放に関するオプションを" WITH (プロパティキー=プロパティ値, ...)"の形式で指定することができます。
機能 内容 プロパティキー プロパティ値の型 期限解放機能 種別 expiration_type STRING型 (指定可能な値は次の1種類。 ROW: ロウ期限解放) 経過時間 expiration_time INTEGER型 経過単位 expiration_time_unit STRING型 (指定可能な値は次の5種類。 DAY / HOUR / MINUTE / SECOND / MILLISECOND ) 分割数 expiration_division_count INTEGER型 - 各項目の内容については『GridDB テクニカルリファレンス』(GridDB_TechnicalReference.html)を参照ください。
例
-
テーブルの作成
CREATE TABLE IF NOT EXISTS myTable ( key INTEGER PRIMARY KEY, value1 DOUBLE NOT NULL, value2 DOUBLE NOT NULL );
-
ロウ期限解放を使用する時系列テーブルの作成
CREATE TABLE IF NOT EXISTS myTimeseries ( mycolumn1 TIMESTAMP PRIMARY KEY, mycolumn2 STRING ) USING TIMESERIES WITH ( expiration_type='ROW', expiration_time=10, expiration_time_unit='DAY' );
3.1.2.2 パーティションテーブルの作成
パーティションテーブルを作成します。
各パーティショニングの機能については、『GridDB テクニカルリファレンス』(GridDB_TechnicalReference.html)を参照ください。
(1) ハッシュパーティションテーブルの作成
構文
-- テーブル(コレクション)
CREATE TABLE [IF NOT EXISTS] テーブル名 ( 列定義 [, 列定義 ...] )
PARTITION BY HASH (パーティショニングキーの列名) PARTITIONS 分割数;
-- 時系列テーブル(時系列コンテナ)
CREATE TABLE [IF NOT EXISTS] テーブル名 ( 列定義 [, 列定義 ...] )
USING TIMESERIES [WITH (プロパティキー=プロパティ値, ...)]]
PARTITION BY HASH (パーティショニングキーの列名) PARTITIONS 分割数;
仕様
- 指定されたパーティショニングキーの列名と分割数の値により、ハッシュパーティションテーブルを作成します。
- 「分割数」は、1以上かつ1024以下の値を指定してください。
- パーティショニングキーに指定した列の値は、更新できません。
- 時系列テーブルの場合、期限解放に関するオプションを" WITH (プロパティキー=プロパティ値, ...)"の形式で指定することができます。指定可能なオプションは通常のテーブルと同様です。
例
-
ハッシュパーティションテーブルの作成
CREATE TABLE IF NOT EXISTS myHashPartition ( id INTEGER PRIMARY KEY, value STRING ) PARTITION BY HASH (id) PARTITIONS 128;
構文
-- テーブル(コレクション)
CREATE TABLE [IF NOT EXISTS] テーブル名 ( 列定義 [, 列定義 ...] )
[WITH (プロパティキー=プロパティ値, ...)]
PARTITION BY RANGE(パーティショニングキーの列名) EVERY(分割幅値 [, 単位 ]);
-- 時系列テーブル(時系列コンテナ)
CREATE TABLE [IF NOT EXISTS] テーブル名 ( 列定義 [, 列定義 ...] )
USING TIMESERIES [WITH (プロパティキー=プロパティ値, ...)]
PARTITION BY RANGE(パーティショニングキーの列名) EVERY(分割幅値 [, 単位 ]);
仕様
- 「パーティショニングキーの列名」には、BYTE型、SHORT型、INTEGER型、LONG型、TIMESTAMP型のいずれかの列を指定してください。
- 「パーティショニングキーの列名」に指定する列は、"PRIMARY KEY"または"NOT NULL"制約を指定する必要があります。
- パーティショニングキーに指定した列の値は、更新できません。
-
分割幅値には次の値が指定できます。
パーティショニングキーの型 分割幅値に指定できる値 BYTE型 1~127 SHORT型 1~32767 INTEGER型 1~2147483647 LONG型 1000~9223372036854775807 TIMESTAMP型 1以上 - TIMESTAMP型の列を指定した場合は、単位を指定する必要があります。単位に指定できる値は、DAYです。
- TIMESTAMP型以外の列を指定した場合は、単位は指定できません。
-
期限解放に関するオプションを" WITH (プロパティキー=プロパティ値, ...)"の形式で指定することができます。
機能 内容 プロパティキー プロパティ値の型 期限解放機能 種別 expiration_type STRING型 (指定可能な値は次の2種類。指定省略時はPARTITION。 PARTITION: パーティション期限解放 ROW: ロウ期限解放) 経過時間 expiration_time INTEGER型 経過単位 expiration_time_unit STRING型 (指定可能な値は次の5種類。 DAY / HOUR / MINUTE / SECOND / MILLISECOND ) 分割数 expiration_division_count INTEGER型 (ロウ期限解放の場合のみ指定) - ロウ期限解放は時系列テーブル(時系列コンテナ)の場合に指定できます。
-
パーティション期限解放は次の場合に指定できます。
- 時系列テーブル(時系列コンテナ)
- パーティショニングキーがTIMESTAMP型のテーブル(コレクション)
- 各項目の内容については『GridDB テクニカルリファレンス』(GridDB_TechnicalReference.html)を参照ください。
例
-
インターバルパーティションテーブルの作成
CREATE TABLE IF NOT EXISTS myIntervalPartition ( date TIMESTAMP PRIMARY KEY, value STRING ) PARTITION BY RANGE (date) EVERY (30, DAY);
-
パーティション期限解放を使用するインターバルパーティションテーブル(時系列テーブル)の作成
CREATE TABLE IF NOT EXISTS myIntervalPartition2 ( date TIMESTAMP PRIMARY KEY, value STRING ) USING TIMESERIES WITH ( expiration_type='PARTITION', expiration_time=90, expiration_time_unit='DAY' ) PARTITION BY RANGE (date) EVERY (30, DAY);
(3) インターバル-ハッシュパーティションテーブルの作成
構文
-- テーブル(コレクション)
CREATE TABLE [IF NOT EXISTS] テーブル名 ( 列定義 [, 列定義 ...] )
[WITH (プロパティキー=プロパティ値, ...) ]
PARTITION BY RANGE(インターバルパーティショニングキーの列名) EVERY(分割幅値 [, 単位 ])
SUBPARTITION BY HASH(ハッシュパーティショニングキーの列名) SUBPARTITIONS 分割数;
-- 時系列テーブル(時系列コンテナ)
CREATE TABLE [IF NOT EXISTS] テーブル名 ( 列定義 [, 列定義 ...] )
USING TIMESERIES [WITH (プロパティキー=プロパティ値, ...)]
PARTITION BY RANGE(インターバルパーティショニングキーの列名) EVERY(分割幅値 [, 単位 ])
SUBPARTITION BY HASH(ハッシュパーティショニングキーの列名) SUBPARTITIONS 分割数;
仕様
- 「インターバルパーティショニングキーの列名」には、BYTE型、SHORT型、INTEGER型、LONG型、TIMESTAMP型のいずれかの列を指定してください。
- 「インターバルパーティショニングキーの列名」に指定する列には、"PRIMARY KEY"または"NOT NULL"制約を指定する必要があります。
-
インターバルパーティショニングの分割幅値には次の値が指定できます。
パーティショニングキーの型 分割幅値に指定できる値 BYTE型 1~127 SHORT型 1~32767 INTEGER型 1~2147483647 LONG型 1000×ハッシュの分割数~9223372036854775807 TIMESTAMP型 1以上 - TIMESTAMP型の列を指定した場合は、単位を指定する必要があります。単位に指定できる値は、DAYです。
- TIMESTAMP型以外の列を指定した場合は、単位は指定できません。
- ハッシュパーティショニングの「分割数」は、1以上かつ1024以下の値を指定してください。
- パーティショニングキーに指定した列の値は、更新できません。
- 期限解放に関するオプションを" WITH (プロパティキー=プロパティ値, ...)"の形式で指定することができます。指定可能なオプションはインターバルパーティションテーブルと同様です。
例
-
インターバルハッシュパーティションテーブルの作成
CREATE TABLE IF NOT EXISTS myIntervalHashPartition ( date TIMESTAMP PRIMARY KEY, value STRING ) PARTITION BY RANGE (date) EVERY (60, DAY) SUBPARTITION BY HASH (value) SUBPARTITIONS 64;
-
パーティション期限解放を使用するインターバルハッシュパーティションテーブル(時系列テーブル)の作成
CREATE TABLE IF NOT EXISTS myIntervalHashPartition2 ( date TIMESTAMP PRIMARY KEY, value STRING ) USING TIMESERIES WITH ( expiration_type='PARTITION', expiration_time=90, expiration_time_unit='DAY' ) PARTITION BY RANGE (date) EVERY (60, DAY) SUBPARTITION BY HASH (value) SUBPARTITIONS 64;
3.1.3 CREATE INDEX
索引を作成します。
構文
CREATE INDEX [IF NOT EXISTS] 索引名 ON テーブル名 ( 索引をつける列名 );
仕様
- 索引名の規則はネーミングの規則を参照ください。
- 既に存在する索引と同じ名前の索引は作成できません。
- 処理対象のテーブルにおいて実行中のトランザクションが存在する場合、それらの終了を待機してから作成を行います。
- BLOB型の列には索引を作成できません。
3.1.4 CREATE USER
一般ユーザを作成します。
構文
CREATE USER ユーザ名 IDENTIFIED BY ‘パスワード文字列’;
仕様
- ユーザ名の規則はネーミングの規則を参照ください。
- 管理ユーザのみが実行可能です。
- インストール時に登録済の管理ユーザ(adminおよびsystem)と同一の名前のユーザは作成できません。
- パスワード文字列に使用できる文字は、ASCII文字のみです。大文字と小文字は区別します。
3.1.5 DROP DATABASE
データベースを削除します。
構文
DROP DATABASE データベース名;
仕様
- 管理ユーザのみが実行可能です。
- 「public」、「information_schema」という名前のデータベース、及び「gs#」で始まる名前のデータベースは、GridDBの内部用に予約済みのため削除できません。
- ユーザが作成したテーブルが存在するデータベースは削除できません。
3.1.6 DROP TABLE
テーブルを削除します。
構文
DROP TABLE [IF EXISTS] テーブル名;
仕様
- “IF EXISTS”が指定された場合、指定した名前のテーブルが存在しない場合は何も変更しません。
- 処理対象のテーブルにおいて実行中のトランザクションが存在する場合、それらの終了を待機してから削除を行います。
3.1.7 DROP INDEX
指定された索引を削除します。
構文
DROP INDEX [IF EXISTS] 索引名 ON テーブル名;
仕様
- “IF EXISTS”が指定された場合、指定した名前の索引が存在しない場合は何も変更しません。
- 処理対象のテーブルにおいて実行中のトランザクションが存在する場合、それらの終了を待機してから削除を行います。
- NoSQLインターフェースから名前無しで付与した索引をDROP INDEXで削除することはできません。
3.1.9 SET PASSWORD
一般ユーザのパスワードを変更します。
構文
SET PASSWORD [FOR ユーザ名 ] = ‘パスワード文字列’;
仕様
- 管理ユーザは全ての一般ユーザのパスワードを変更可能です。
- 一般ユーザは自身のパスワードのみ変更可能です。
3.1.10 ALTER TABLE
テーブルの構造を変更します。
3.1.10.1 カラムを追加する
テーブルの末尾にカラムを追加します。
構文
ALTER TABLE テーブル名 ADD [COLUMN] 列定義 [,ADD [COLUMN] 列定義 ...];
列定義
- 列名 型名 [ 列制約 ]
列制約
- NULL
- NOT NULL
仕様
- 追加するカラムは、テーブルの末尾に配置します。複数のカラムを指定した場合は指定した順序で配置します。
- 列制約に"PRIMARY KEY"は指定できません。
- 既に同じ名前のカラムが存在した場合はエラーになります。
例
-
複数のカラムの追加
ALTER TABLE myTable1 ADD COLUMN col111 STRING NOT NULL, ADD COLUMN col112 INTEGER;
3.1.10.2 データパーティションを削除する
テーブルパーティショニングで作成されたデータパーティションを削除します。
構文
ALTER TABLE テーブル名 DROP PARTITION FOR ( 削除するデータパーティションの区間(下限値から上限値)に含まれる値 );
仕様
- インターバルとインターバル-ハッシュパーティショニングの場合のみ、データパーティションを削除できます。
- 削除するデータパーティションの区間(下限値から上限値)に含まれる値を指定してください。
- 一度削除したデータパーティションの区間(下限値から上限値)に該当するデータの新規登録はできません。
- データパーティションの下限値は、メタテーブルで確認できます。上限値は、下限値+分割幅値の値です。
- インターバル-ハッシュパーティショニングの場合は、同じ下限値のデータパーティションが、ハッシュの分割数分(最大)存在します。データパーティションを削除する場合は、それらの同じ下限値をもつデータパーティションは同時に削除されます。削除の確認はメタテーブルで行います。
メタテーブルの詳細はメタテーブルを参照ください。
例
インターバルパーティショニングテーブル
-
インターバルパーティショニングのテーブル「myIntervalPartition1」(パーティショニングキーの型:TIMESTAMP、分割幅値30DAY)のデータパーティションの下限値一覧を確認する
SELECT PARTITION_BOUNDARY_VALUE FROM "#table_partitions" WHERE TABLE_NAME='myIntervalPartition1' ORDER BY PARTITION_BOUNDARY_VALUE; PARTITION_BOUNDARY_VALUE ----------------------------------- 2017-01-10T13:00:00Z 2017-02-09T13:00:00Z 2017-03-11T13:00:00Z : -
不要なデータパーティションを削除する
ALTER TABLE myIntervalPartition1 DROP PARTITION FOR ('2017-01-10T13:00:00Z');
インターバルハッシュパーティショニングテーブル
-
インターバルハッシュパーティショニングのテーブル「myIntervalHashPartition」(インターバルパーティショニングキーの型:TIMESTAMP、分割幅値90DAY、ハッシュパーティショニングキーの分割数3)のデータパーティションの下限値一覧を確認する
SELECT PARTITION_BOUNDARY_VALUE FROM "#table_partitions" WHERE TABLE_NAME='myIntervalHashPartition' ORDER BY PARTITION_BOUNDARY_VALUE; PARTITION_BOUNDARY_VALUE ----------------------------------- 2016-08-01T10:00:00Z 同じ下限値のデータがハッシュされて3つの 2016-08-01T10:00:00Z データパーティションに分割されている 2016-08-01T10:00:00Z 2016-10-30T10:00:00Z 2016-10-30T10:00:00Z 2016-10-30T10:00:00Z 2017-01-29T10:00:00Z : -
不要なデータパーティションを削除する
ALTER TABLE myIntervalHashPartition DROP PARTITION FOR ('2016-09-15T10:00:00Z'); -
同じ下限値のデータパーティションが削除される
SELECT PARTITION_BOUNDARY_VALUE FROM "#table_partitions" WHERE TABLE_NAME='myIntervalHashPartition' ORDER BY PARTITION_BOUNDARY_VALUE; PARTITION_BOUNDARY_VALUE ----------------------------------- 2016-10-30T10:00:00Z '2016-09-15T10:00:00Z'を含む区間(下限値'2016-08-01T10:00:00Z')の 2016-10-30T10:00:00Z 3つのデータパーティションが削除される 2016-10-30T10:00:00Z 2017-01-29T10:00:00Z :
3.2 データ制御言語(DCL)
3.3 データ操作言語(DML)
3.3.1 SELECT
データを取得します。FROM句、WHERE句など様々な句から構成されます。
構文
SELECT [{ALL|DISTINCT}] 列名1 [, 列名2 ...] [FROM句]
[WHERE句]
[GROUP BY句 [HAVING句]]
[ORDER BY句]
[LIMIT句 [OFFSET句]];
3.3.2 INSERT
テーブルに行を登録します。
構文
{INSERT|INSERT OR REPLACE|REPLACE} INTO テーブル名
{VALUES ( { 数値1 | 文字列1 } [, { 数値2 | 文字列2 } ...] ), ... | SELECT文};
3.3.4 UPDATE
テーブルに存在する行を更新します。
構文
UPDATE テーブル名 SET 列名1 = 式1 [, 列名2 = 式2 ...] [WHERE句];
仕様
- PRIMARY KEY制約のあるカラムの値は更新できません。
-
パーティショニングを設定した場合、UPDATEを使ってパーティションキーになっている項目を別の値に更新することは出来ません。
-
例)
CREATE TABLE tab (a INTEGER, b STRING) PARTITION BY HASH a PARTITIONS 5; -- NG UPDATE tab SET a = a * 2; [240016:SQL_COMPILE_PARTITIONING_KEY_NOT_UPDATABLE] Partitioning column='a' is not updatable -- OK UPDATE tab SET b = 'XXX';
このような場合は、DELETE後にINSERTを行ってください。
-
例)
3.5 述語
比較演算子(=、>など)を使った比較述語以外にBETWEEN、IN、LIKEを使うことができます。
3.7 関数
GridDB AEのSQL文には以下の関数が用意されています。
AVG、GROUP_CONCAT、SUM、TOTAL、EXISTS、ABS、CHAR、COALESCE、IFNULL、INSTR、HEX、LENGTH、LIKE、LOWER、LTRIM、MAX、MIN、NULLIF、PRINTF、QUOTE、RANDOM、RANDOMBLOB、REPLACE、ROUND、RTRIM、SUBSTR、TRIM、TYPEOF、UNICODE、UPPER、ZEROBLOB、NOW、TIMESTAMP、TO_TIMESTAMP_MS、TO_EPOCH_MS、EXTRACT、TIMESTAMPADD、TIMESTAMPDIFF
3.8 ヒント機能
GridDB AEでは、実行計画を示すヒントをクエリに指定することで、SQL文を変えることなく実行計画を制御できます。
【注意事項】
- 本機能は将来のバージョンで変更される可能性があります。
3.8.1 用語
ヒント機能で用いる用語は次のとおりです。
| 用語 | 説明 |
|---|---|
| ヒント句 | 実行計画を制御するための情報 |
| ヒント | ヒント句を列挙したもの。実行計画を制御するクエリに指定する。 |
3.8.2 ヒントの指定方法
実行計画を制御するクエリのブロックコメントの中にヒントを記述します。ヒント用のブロックコメントは、SQL文中の先頭のSELECT(INSERT/UPDATE/DELETE)句の直前または直後のみ記述できます。通常のコメントと区別するため、ヒント用のブロックコメントは「/*+」で始めます。
ヒントの対象は、ヒント句の括弧内にオブジェクト名または別名で指定します。複数のオブジェクト名を指定する場合、スペース、タブ、改行のいずれかで区切って指定します。
以下の例では、MaxDegreeOfParallelismヒント句により処理スレッド数上限を2に設定するとともに、Leadingヒント句により、テーブル結合順序を指定しています。
/*+
MaxDegreeOfParallelism(2)
Leading(t3 t2 t1)
*/
SELECT *
FROM t1, t2, t3
ON t1.x = t2.y and t2.y = t3.z
ORDER BY t1.x
LIMIT 10;
【メモ】
- クエリ中に同一名称のテーブルが複数回現れる場合、それぞれのテーブルに別名をつけて区別してください。
3.8.3 ヒント句一覧
指定できるヒント句の一覧を次に示します。
| 分類 | 命令 | 説明 |
|---|---|---|
| 並列化 | MaxDegreeOfParallelism(並列数上限) | 1クエリの処理スレッド数の上限 |
| MaxDegreeOfTaskInput(上限数) | 1タスクへの入力の上限 | |
| MaxDegreeOfExpansion(上限数) | プランノードの展開数の上限 | |
| 分散プランニング | DistributedPolicy(分散プラン方針) | 分散プラン方針の指定。'LOCAL_ONLY', |
| 'LOCAL_PREFER'のいずれかが指定可能 | ||
| スキャン方式 | IndexScan(テーブル) | 可能な場合はインデックススキャンを選択する |
| NoIndexScan(テーブル) | インデックススキャンを選択しない | |
| 結合方式 | IndexJoin(テーブル テーブル) | 可能な場合はインデックスジョインを選択する |
| NoIndexJoin(テーブル テーブル) | インデックスジョインを選択しない | |
| 結合順序 | Leading(テーブル テーブル[ テーブル ...]) | 指定したテーブルを指定した順序で結合する |
| Leading(( テーブル集合 テーブル集合 )) | 1つ目に指定したテーブル集合を外部表、 | |
| テーブル集合 = { テーブル or | 2つ目に指定したテーブル集合を内部表として | |
| ( テーブル集合 テーブル集合 ) } | 結合する |
3.8.4 ヒント句詳細
ヒント句の分類ごとに詳細を説明します。
3.8.4.1 並列化
並列化処理の制御を行います。
-
MaxDegreeOfParallelism(並列数上限)
- あるノードでSQLを処理する場合の、1クエリあたりの最大並列スレッド数を指定します。
-
MaxDegreeOfTaskInput(上限数)
-
1タスクへの入力の上限数を指定します。以下の処理に適用されます。
- テーブルパーティショニングの設定されたテーブルをスキャンした場合のUNION ALL処理
-
1タスクへの入力の上限数を指定します。以下の処理に適用されます。
-
MaxDegreeOfExpansion(上限数)
-
プランノードの展開数の上限を指定します。以下の処理に適用されます。
- プッシュダウンジョイン最適化処理
-
プランノードの展開数の上限を指定します。以下の処理に適用されます。
3.8.4.2 分散プランニング
分散プランニングの方針を指定します。
-
DistributedPolicy(分散プラン方針)
-
分散プラン方針として、以下のいずれかが指定可能です。
-
'LOCAL_ONLY'
- 分散プランとして、接続したノードだけで分散させずにプランニングします。ローカルになければエラーとなります。
-
'LOCAL_PREFER'
- 分散プランとして、接続したノードのローカル情報を優先してプランニングします。ローカルになければリモートプランを生成します。
-
'LOCAL_ONLY'
-
分散プラン方針として、以下のいずれかが指定可能です。
3.8.4.3 スキャン方式
テーブルのスキャン方式を指定します。
-
IndexScan(テーブル)
- 可能な場合はインデックススキャンを選択します。元々インデックススキャンが不可能な場合は何もしません。
-
NoIndexScan(テーブル)
- インデックススキャンを選択しません。
3.8.4.4 結合方式
結合方式を指定します。
-
IndexJoin(テーブル テーブル)
- 可能な場合はインデックスジョインを選択します。 元々インデックスジョインが不可能な場合は何もしません。
-
NoIndexJoin(テーブル テーブル)
- インデックスジョインを選択しません。
3.8.4.5 結合順序
テーブルのジョイン処理でどのような順番で結合するかを指定します。
(1) 結合順序のみ指定: Leading(テーブル テーブル[ テーブル ...])
先に結合するテーブルから順にテーブル名または別名を指定します。この指定方式の場合、常にLeft-deep joinで結合されます。
(例1)
/*+ Leading(S R Q P) */ SELECT * FROM P,Q,R,S WHERE P.x = Q.x AND ...
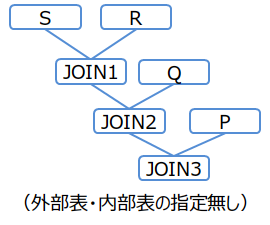
結合順序(例1)
(2) 結合方向を含めた指定: Leading((テーブル集合 テーブル集合))
テーブル集合 = { テーブル or (テーブル集合 テーブル集合) }
(1)のように結合順序のみを指定した場合、結合方向(外部表/内部表の別)が期待と異なる場合があります。結合方向を固定したい場合は以下の書式を使います。
/*+ Leading((t1 (t2 t3))) */ SELECT ...
この書式では、括弧をネストして記述できます。括弧内の1つ目に指定したテーブル集合を外部表、2つ目に指定したテーブル集合を内部表として結合されます。
(例2-1)
/*+ Leading(((P Q) R)) */ SELECT * FROM P,Q,R WHERE P.x = Q.x AND ...
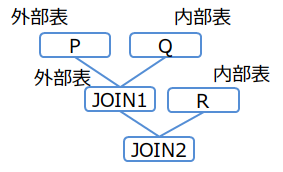
結合順序(例2-1)
(例2-2)
/*+ Leading((R (Q P))) */ SELECT * FROM P,Q,R WHERE P.x = Q.x AND ...
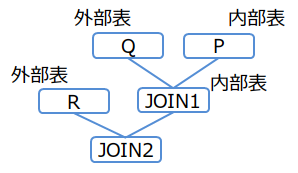
結合順序(例2-2)
(例2-3)
/*+ Leading(((P Q) (R S))) */ SELECT * FROM P,Q,R,S WHERE P.x = Q.x AND ...
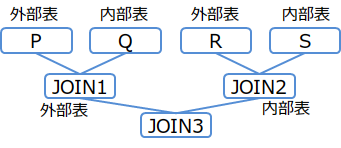
結合順序(例2-3)
【メモ】
- 3つ以上のテーブルの結合で、テーブル間の結合条件が1つもない場合は、ヒントによる順序指定は出来ません。
3.8.5 エラーの扱い
以下の場合は構文エラーとなります。
- ヒント用のブロックコメントを複数記述した場合
- ヒントを記述できない位置にヒントを記述した場合
- ヒント句の記述に構文上の誤りがあった場合
- 同じテーブルに対して同じ分類のヒント句を重複して指定した場合
以下の場合はテーブル指定エラーとなります。
- ヒント句対象のテーブル指定に誤りがあった場合
【メモ】
- テーブル指定エラーが起こった場合、対象のヒント句を無視し、それ以外のヒント句を使ってクエリを実行します。
- 構文エラーとテーブル指定エラーが同時に起こった場合は構文エラーとなります。
4 メタテーブル
4.1 メタテーブルとは
GridDBの管理用のメタデータを参照することができるテーブル群です。
【メモ】
- メタテーブルは、参照のみ可能です。データの登録や削除はできません。
- SELECTで参照する際、メタテーブル名は引用符"で囲んでください。
【注意事項】
- メタテーブルのスキーマは将来のバージョンで変更される可能性があります。
4.2 テーブル情報
テーブルに関する情報を取得できます。
テーブル名
#tables
スキーマ
| 列名 | 内容 | 型 |
|---|---|---|
| DATABASE_NAME | データベース名 | STRING |
| TABLE_NAME | テーブル名 | STRING |
| TABLE_OPTIONAL_TYPE | テーブル種別 | STRING |
| COLLECTION / TIMESERIES | ||
| DATA_AFFINITY | データアフィニティ | STRING |
| EXPIRATION_TIME | 期限解放経過時間 | INTEGER |
| EXPIRATION_TIME_UNIT | 期限解放経過単位 | STRING |
| EXPIRATION_DIVISION_COUNT | 期限解放分割数 | STRING |
| COMPRESSION_METHOD | 時系列圧縮方式 | STRING |
| COMPRESSION_WINDOW_SIZE | 時系列圧縮間引き最大期間 | INTEGER |
| COMPRESSION_WINDOW_SIZE_UNIT | 時系列圧縮間引き最大期間単位 | STRING |
| PARTITION_TYPE | パーティショニング種別 | STRING |
| PARTITION_COLUMN | パーティショニングキー | STRING |
| PARTITION_INTERVAL_VALUE | 分割値(インターバル/インターバルハッシュの場合) | INTEGER |
| PARTITION_INTERVAL_UNIT | 分割単位(インターバル/インターバルハッシュの場合) | STRING |
| PARTITION_DIVISION_COUNT | 分割数(ハッシュの場合) | INTEGER |
| SUBPARTITION_TYPE | パーティショニング種別 | STRING |
| (インターバルハッシュの場合にHASH) | ||
| SUBPARTITION_COLUMN | パーティショニングキー | STRING |
| (インターバルハッシュの場合) | ||
| SUBPARTITION_INTERVAL_VALUE | 分割値 | INTEGER |
| SUBPARTITION_INTERVAL_UNIT | 分割単位 | STRING |
| SUBPARTITION_DIVISION_COUNT | 分割数 | INTEGER |
| (インターバルハッシュの場合) | ||
| EXPIRATION_TYPE | 期限解放種別 | STRING |
| ROW / PARTITION |
4.3 索引情報
索引に関する情報を取得できます。
テーブル名
#index_info
スキーマ
| 列名 | 内容 | 型 |
|---|---|---|
| DATABASE_NAME | データベース名 | STRING |
| TABLE_NAME | テーブル名 | STRING |
| INDEX_NAME | 索引名 | STRING |
| INDEX_TYPE | 索引種別 | STRING |
| TREE / HASH / SPATIAL | ||
| ORDINAL_POSITION | 索引内のカラム列順序 (常に1) | SHORT |
| COLUMN_NAME | カラム名 | STRING |
4.4 パーティショニング情報
パーティショニングされたテーブルの内部コンテナ(データパーティション)に関する情報を取得することができます。
テーブル名
#table_partitions
スキーマ
| 列名 | 内容 | 型 |
|---|---|---|
| DATABASE_NAME | データベース名 | STRING |
| TABLE_NAME | パーティショニングされたテーブルの名前 | STRING |
| PARTITION_BOUNDARY_VALUE | データパーティションの下限値 | STRING |
仕様
-
ロウ1件がひとつのデータパーティションの情報を表します。
- 例えば、分割数128のハッシュパーティショニングテーブルの場合、TABLE_NAMEにテーブル名を指定して検索するとロウが128個表示されます。
- 上記の列以外にも複数の列が表示されます。
- 下限値でソートする場合、対象のパーティショニングキーの型に合わせてキャストする必要があります。
例
-
データパーティションの数を確認する
SELECT COUNT(*) FROM "#table_partitions" WHERE TABLE_NAME='myIntervalPartition'; COUNT(*) ----------------------------------- 8703
-
データパーティションの下限値を確認する
SELECT PARTITION_BOUNDARY_VALUE FROM "#table_partitions" WHERE TABLE_NAME='myIntervalPartition' ORDER BY PARTITION_BOUNDARY_VALUE; PARTITION_BOUNDARY_VALUE ----------------------------------- 2016-10-30T10:00:00Z 2017-01-29T10:00:00Z : -
インターバルパーティショニングのテーブル「myIntervalPartition2」(パーティショニングキーの型:INTEGER、分割基準値 20000)のデータパーティションの下限値一覧を確認する
SELECT CAST(PARTITION_BOUNDARY_VALUE AS INTEGER) V FROM "#table_partitions" WHERE TABLE_NAME='myIntervalPartition2' ORDER BY V; PARTITION_BOUNDARY_VALUE ----------------------------------- -5000 15000 35000 55000 :
5 参考文献
- 日本工業標準調査会ウェブサイト, http://www.jisc.go.jp/, JISX3005-2データベース言語SQL 第2部:基本機能(SQL/Foundation)
6 付録:予約語
GridDB AEのSQLでは、以下の単語が予約語として定義されています。
ABORT ACTION AFTER ALL ANALYZE AND AS ASC BEGIN BETWEEN BY CASE CAST COLLATE COLUMN COMMIT CONFLICT CREATE CROSS DATABASE DAY DELETE DESC DISTINCT DROP ELSE END ESCAPE EXCEPT EXCLUSIVE EXISTS EXPLAIN EXTRACT FALSE FOR FROM GLOB GRANT GROUP HASH HAVING HOUR IDENTIFIED IF IN INDEX INITIALLY INNER INSERT INSTEAD INTERSECT INTO IS ISNULL JOIN KEY LEFT LIKE LIMIT MATCH MILLISECOND MINUTE MONTH NATURAL NO NOT NOTNULL NULL OF OFFSET ON OR ORDER OUTER PARTITION PARTITIONS PASSWORD PLAN PRAGMA PRIMARY QUERY RAISE REGEXP RELEASE REPLACE RESTRICT REVOKE RIGHT ROLLBACK ROW SECOND SELECT SET TABLE THEN TIMESTAMPADD TIMESTAMPDIFF TO TRANSACTION TRUE UNION UPDATE USER USING VALUES VIEW VIRTUAL WHEN WHERE WITHOUT XOR YEAR