GridDB プログラミングチュートリアル
Revision: 1614
Table of Contents
1 はじめに
1.1 本書の目的と構成
本書では、GridDB NoSQLインターフェースを用いたアプリケーションを設計・開発をする際の考慮点を、例題を用いて説明します。
本書は、アプリケーションを設計・開発する開発者を対象としています。
本書の構成は以下のとおりです。
-
例題
- アプリケーション開発のターゲットとする例題の仕様を説明します。
-
GridDBの特徴
- アプリケーション開発時にあらかじめ理解・注意いただきたいGridDBの特徴を説明します。
-
例題のスキーマ設計
- GridDBを用いてスキーマ設計をする際に考慮すべき点について説明します。
-
クライアントプログラムの処理
- GridDBの動作を制御するパラメータについて説明します。
-
プログラム例
- 実際に動作するサンプルプログラムを提示し、処理を説明します。
2 例題
『太陽光発電を行うPVサイトの監視システム』を簡略化した処理の開発を例題に用いて説明していきます。
2.1 PVサイトの監視
PVサイトは、発電を行うパネルを複数(通常、数千枚から数十万枚)設置し、各パネルが発電した電力を集約して、電力網に送電する設備です。制御の都合上、ストリングやアレイという単位でパネルを複数まとめ、これらを用いて発電した電力を、集電箱(CC)、パワーコンディショナ(PCS)およびゲートウェイ(GW)といった設備を介して集約し、集約した電力をGWを介して電力網に送電することとします。また、各設備には発電状況などの状態を監視できるよう、各種センサを備えているという仕様とします。
PVサイト監視システムは、PVサイトの発電状況を監視して異状を検知するためのシステムです。システム構成の模式図を以下に示します。
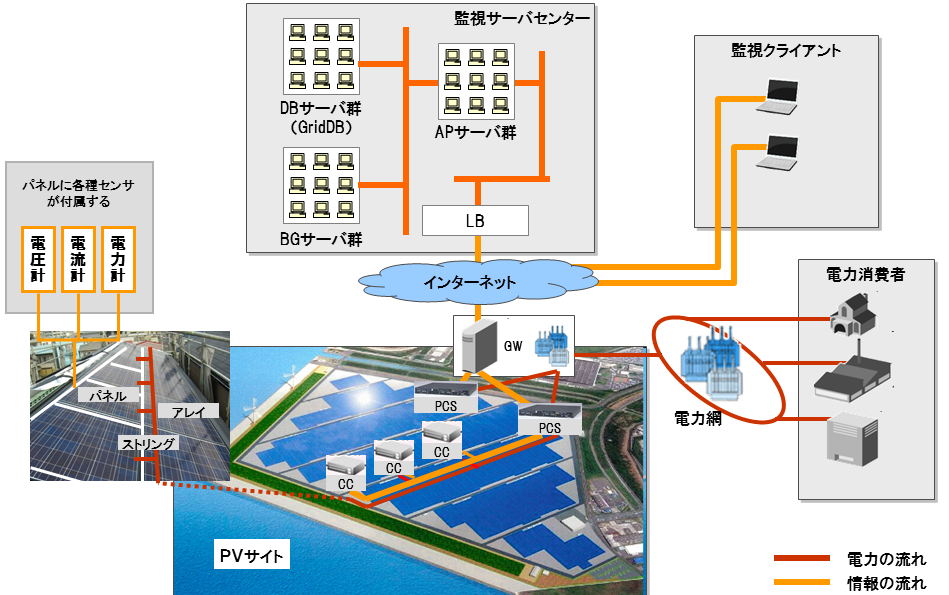
PVサイト監視システムの例
- PVサイトで発電された電力は、GWから電力網を経由して電力消費者に送電される。PVサイトでは各種センサを用いて発電中の設備状態を計測している。
- PVサイトで計測された設備状態情報は、GWからインターネットを経由して監視サーバセンターに送信される。監視サーバセンターでは、受信した各種状態情報がデータベースに蓄積される。この際、PVサイト側で各種センサ値の正常/異状を判断し、異状時にはアラート情報が監視サーバセンターに送信される。
- PVサイトの設備構成および設備仕様は予めデータベースに登録されている。今回の例では、設備状態の計測のために、各パネルに電圧計、電流計、電力計のセンサを備えている。
- 監視クライアントは、監視サーバセンターのデータベースに蓄積されたアラート情報を参照し、PVサイトの異状を監視する。
2.2 例題で扱う機能
今回、例題としてGridDBを使用し、以下のように単純化したPVサイト監視機能を開発することとします。
- 設備状態情報、アラート情報の登録機能を単純化し、それぞれの情報をCSVファイルから一括読み込み、予めクラスタデータベースに登録しておく。
- 異状検知機能を単純化し、直近24時間のアラート履歴から、重大な異状を示すアラートを探し、その異状が発生した設備の設備情報、および異状発生時刻近辺のセンサ値を表示する。
例題では以下のデータリソースが存在します。
-
設備情報
- 設備毎の定義情報を表現するものであり、設備毎に割り当てられた設備ID、設備名および設備仕様で構成される。
-
センサ情報
- 設備とセンサの対応関係を表現するものであり、センサ毎のセンサ名、センサ種別と測定対象の設備IDで構成される。
-
センサ履歴情報
- ある時刻での計測値を表現するものであり、計測した日付時刻、その時点での計測値および状態で構成される。
-
アラート履歴情報
- 検知されたアラート情報を表現するものであり、発生したアラートのアラートID、発生した日付時刻、検知したセンサID、アラートのレベル、およびアラート詳細情報で構成される。
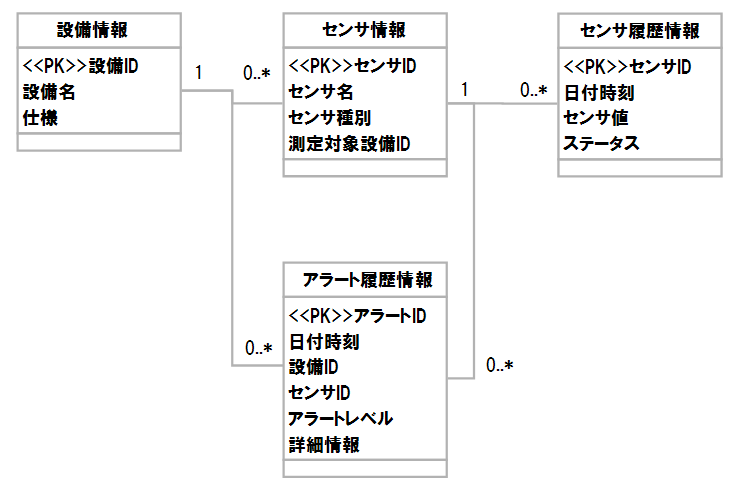
論理スキーマ
3 GridDBの特徴
GridDBを使用する上で注意すべき5つの特徴を以下に示します。
- コンテナの概念
- トランザクションの制限
- クエリの制限
- キーコーディングの重要性
- コレクションや時系列コンテナの索引付与
- 正しいコレクションとロウの粒度
以下、順に説明する。
3.1 コンテナの概念
GridDBでは、(RDBにおけるテーブルに相当する)コンテナと総称されるデータ格納先を作成し、データを管理します。コンテナは、基本的にはKVデータを格納するものですが、単純なKV形式に限定せず、独自にスキーマ定義して使用できます。コンテナには以下の二種類があります。
- 一般的なKVデータ管理用のコレクション
- 時系列データ管理用の時系列コンテナ
コンテナ(コレクション/時系列コンテナ)のスキーマはあらかじめデータ形式をクラスとして定義する方法と動的にプログラムでデータの型を指定して作成する方法の2つの方法があります。
ここでは、クラスとしてデータ型を定義する方法を説明します。
- スキーマはクライアントプログラム中でクラスとして定義する。
- 必ず、クラス中のいずれかのメンバ変数を行キーとして指定する。行キーはKVSのキーとして使用されるもので、同一コンテナ内では重複値は許されない。クラス定義の際、"@RowKey"を付与して指定する。
- KVSのバリュー(値)として複数のメンバ変数を持て、また、型に関して制約は無い。そのため、通常の構造体と同様に定義できる。
また、時系列コンテナは時系列データの管理用途に用いられるデータ構造であり、以下のような制限・特徴があります。
- 行キーとして指定できるのは、日付時刻のみ。
- 時系列データの、データ圧縮、補間が可能。
3.2 トランザクションの制限
GridDBは、コンテナ単位でトランザクション管理を行います。1コンテナへアクセスする際のデータの一貫性は保証されます。一方、複数コンテナを参照するトランザクション処理では以下の制限があります。
- コンテナ単位に個別にコミットされるのでロールバックが困難なため、原子性も保証されない。
- 複数コンテナの一括コミットがないため、更新途中の不整合状態を別トランザクションが参照でき厳密には一貫性が保証されない。
以下のように、限定的な用途にのみ使用し、不整合が許容される用途においても対策を検討する必要があります。
- 勘定系など、クリティカルな用途では用いない。
- 整合状態を保証するため、データの存在有無など可能なエラーチェックを行い、エラー時にはリトライする。
3.3 クエリの制限
GridDBでは、キーを指定して検索する、単純なKV型の検索が実行できます。より複雑な条件を記述する場合は、専用の問合せ言語TQLを使用し、検索を行ないます。
TQLは、RDBの問合せ言語SQLのサブセットであり、以下の機能に限定してサポートしています。
- データの検索・更新対象の選択を行う、SELECT文相当のみをサポート。
- 選択したデータの操作や更新処理といったSELECT以外の構文は扱わない。
- 選択式には、全カラムの取得(*)、もしくは集約演算式(SUM等)のみが指定可能。(特定カラムだけの取出しは不可)
- ORDER BYで検索結果の並べ替えが可能。
- LIMIT,OFFSETを用いて、検索結果の取得件数、結果取得の相対位置を指定可能。
- EXPLAIN,EXPLAIN ANALYZEを用いた実行計画の解析
[EXPLAIN [ANALYZE]] SELECT (選択式) [FROM (コレクション・時系列名)] [WHERE (条件式)] [ORDER BY (ソート条件)] [LIMIT (数値) [OFFSET (数値)]]
GridDBでは、データ型に応じた専用の関数も提供しており、時系列データ、空間データに関する検索高速な検索を実現しています。
TQLに関する詳細は『GridDB APIリファレンス』(GridDB_API_Reference.html)を参照してください。
3.4 コレクションや時系列コンテナへの索引付与
GridDBでは、ロウのカラム毎に索引を作成でき、KVのキー条件とした検索のみならず、値一致や範囲条件などのバリュー(値)に関する検索も高速に行えます。そのために、キー条件検索のみを想定した作りこみは必要なく、RDBと同様の感覚でスキーマ定義を行うことができます。
索引タイプにはハッシュ索引(HASH)、ツリー索引(TREE)、空間索引(SPATIAL)の3種類があり、データ型に応じて設定できるタイプが異なります。また、索引のタイプを指定せずに索引設定操作をした場合、デフォルトの索引が設定されます。
| データ型 | HASH | TREE | SPATIAL |
|---|---|---|---|
| STRING | ○ | ● | - |
| BOOL | ○ | ● | - |
| 数値型 | ○ | ● | - |
| TIMESTAMP | ○ | ● | - |
| GEOMETRY | - | - | ● |
○:指定可能 ●:デフォルトの索引 -:指定不可
3.5 キーコーディングの重要性
GridDBでは、専用の問合せ言語TQLを用いた複雑な検索を行えます。しかしながら、複数条件の組合せによる条件検索では、コンテナアクセスが複数回発生するため、検索性能が低下してしまいます。このような場合、アプリの検索パタンを分析し、キーコーディングを設計しておくことで高速化を図れます。キーコーディングとは、一般のKV型データベースで用いるキーを指定した検索のことです。KVデータベースでは、キー検索が最も高速なため、できるだけキー検索で処理できるようにデータモデルを検討します。
例えば、複数条件のAND結合により検索を行いピンポイントで1件取得するようなケースでは、AND条件を織り込んでキー表現しておくことで、キー検索1回で検索が行えます。コンテナアクセス回数を大幅に減らせ、高速化を図れます。以下に、"panel001"設備の"voltage"センサのロウを検索する場合の例を示します。
特にキーコーディングを想定せず、センサIDに単純に正数の連番を割り当てた(例:1, 2, 3,…など)センサ情報コレクション(Sensor_col)から「設備IDが"panel001"」かつ「センサ種別が"voltage"」のロウを検索する場合、以下のような問合せ文で検索します。
select * from Sensor_col where equipId = "panel001" AND sensorType = "voltage"
これに対して、設備IDとセンサ種別を”_”でつなげてセンサIDとする(例:panel001_voltageなど)キーコーディングを施したセンサ情報コレクション(Sensor_col)から「センサIDが"panel001_voltage"」のロウを検索する場合、以下のような問合せ文で検索できます。
select * from Sensor_col where sensorId = "panel001_voltage"
3.6 コンテナとロウの粒度
GridDBは複数ノードでのクラスタ構成が可能であり、システムの成長に合わせてスケールアウトでノードを追加することで容量増加およびスループット向上が達成できます。
そのためには、コンテナに格納するロウ集合を分割し、ロウを分散配置する必要があります。GridDBではこれを自動的に行う機能はないため、アプリケーションシステムでロウ集合の分割(コレクション構成)を設計する必要があります。
以下のようなケースでは適切な粒度にコンテナを分割して実装する必要があります。
- ノードの実メモリサイズを超える巨大なサイズのコンテナは、複数の小さなサイズのコンテナに分けて分割管理する。
- 時系列データは、タグ/センサ毎に1つ時系列コンテナを設けて、タグ/センサ毎にデータを管理する。
- 高頻度で参照されるコレクションは、複数のコンテナに分けて分割管理することで、負荷分散を図れる。
GridDBでは、インメモリデータベースとして動作するので、ロウをメモリ上に書き込み、管理しています。アプリの性能バランスを考慮して、適切な粒度のロウ(実装スキーマ)を設計することで、ロウ(メモリ)の作成・参照コストが削減でき、処理の高速化が図れます。また、GridDBでは、JOINはサポートしていないため、アプリケーションの処理として実現する必要があり、処理コストがかかります。そのため、アプリの性能バランスを考慮して、JOINを回避できるような実装スキーマの設計を行う必要があります。
以下のようなケースでは適切な粒度のロウとなるよう、スキーマ定義を行う必要があります。
- アプリケーションでJOINが頻発する場合、データサイズや登録性能とのバランスを考慮して、直積展開した形のスキーマ定義を行う。
- 特定カラムの参照を高速化する場合、I/O削減のため、該当カラム範囲を分解して別々のスキーマを定義する。
- 一部のカラムのみが高頻度更新される場合、メモリコピーを最小化するため、該当カラム範囲を分解して別々のスキーマを定義する。
4 例題のスキーマ設計
4.1 GridDB上のスキーマ設計一般論
GridDBを用いたデータ管理を行う場合、以下に示すポイントを考慮してスキーマ設計を行う必要があります。
- 複雑な検索処理を避けて高速化するため、キーコーディングルールをうまく設計しキー検索のみで処理することを検討する。
- JOIN処理を避けて高速化するため、あえて正規化を行わずに直積展開したままのスキーマでデータを格納する。
- 値条件による検索を行う場合には、条件で使用するカラムに索引を設定する。
- 時系列データのスケールアウト性能向上のため、センサ毎に1つ時系列コンテナを作成し、それぞれにデータ格納する。
- 更新トランザクションでの不整合を回避するため、同時に更新されるカラムは1つのコレクションに極力まとめる。
4.2 スキーマとコンテナ分割
例題のスキーマをRDB上のテーブルで表現すると以下のようになります。
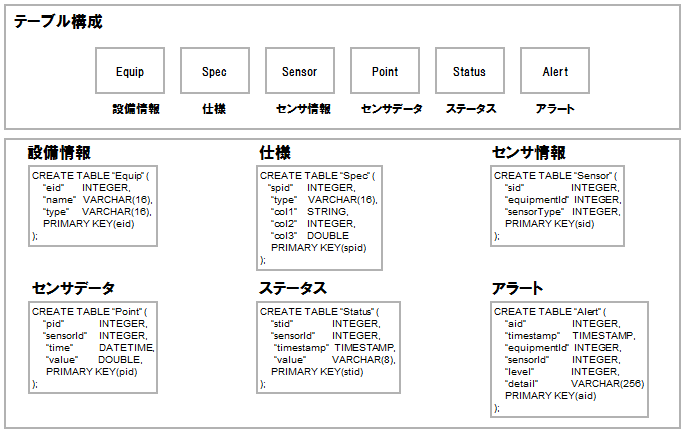
RDBにおけるテーブル表現
一方、GridDB上のコンテナで表現すると以下のようになります。
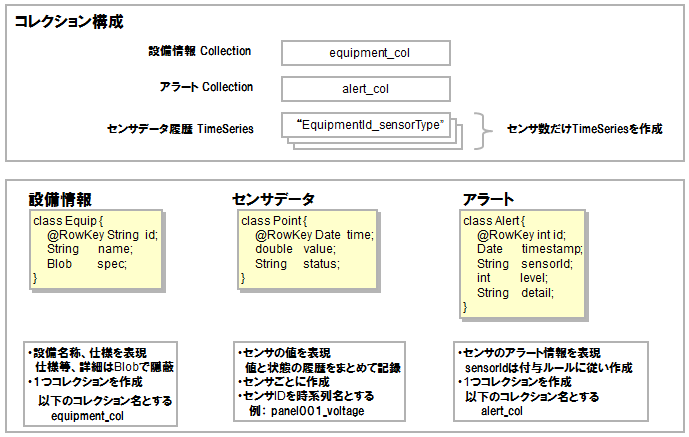
GridDBにおけるコンテナ表現
設備情報、センサデータ履歴情報、アラート履歴情報を、それぞれ以下のコレクション、時系列コンテナに分割して格納します。
| データ | 作成数 | コンテナ名 |
|---|---|---|
| 設備情報 | 1コレクション | equipment_col |
| センサ履歴情報 | センサ毎1時系列コンテナ | センサIDを割当て(例: panel001_voltage) |
| アラート履歴情報 | 1コレクション | alert_col |
また、以下のセンサID命名規則を設けることで、センサ情報データ(センサ管理用のコレクション)を使用しないで設備とセンサの対応関係を表現することとします。
-
設備IDとセンサ種別を”_”でつなげ、センサIDとする("設備ID"_"センサ種別" の形式)。
- 例:panel001_voltage
設備情報、センサデータ履歴情報、アラート履歴情報を、以下のスキーマで定義します。
// 設備情報
class Equip {
@RowKey String id; // 設備ID_センサ種別=センサID
String name; // 設備名
Blob spec; // 仕様情報
}
//センサ履歴
class Point {
@RowKey Date time; // 時刻
double value; // センサ値
String status; // センサ状態
}
//アラート履歴
class Alert {
@RowKey int id; // アラートID
Date timestamp;// 時刻
String sensorId; // センサID
int level; // アラートレベル
String detail; // アラート詳細情報
}
- 設備情報コレクションは、各設備に関する情報を格納するコレクションである。図に示す「Equipクラス」で定義されるスキーマを持ち、設備ID、設備名およびその設備仕様、を格納する。
- センサ履歴は、センサ毎の時系列コンテナで構成される。各時系列コンテナは、図に示す「Pointクラス」で定義されるスキーマを持ち、センサが計測した時刻とその時刻の計測値および状態、を格納する。
- アラート履歴コレクションは、センサで検知されたアラート情報を格納するコレクションである。図に示す「Alertクラス」で定義されるスキーマを持ち、アラートID、発生した時刻、検知したセンサID、アラートレベルおよびアラート詳細情報、を格納する。
5 クライアントプログラムの処理
GridDB上のクライアントプログラムの処理の大まかな流れを以下に説明していきます。なお、具体的なプログラムについては、クライアントプログラムの章で説明します。
5.1 コレクション登録
コレクションへのデータ登録処理の流れは以下のようになります。
まず、データ登録するコレクションが存在しない場合は、以下の処理手順によりコレクションを新規に作成します。
- GridStoreインスタンスの取得
- コレクションの作成
既存のコレクションへは、以下の処理手順によりデータ登録を行います。
- GridStoreインスタンスの取得
- コレクションの取得
- 動作パラメータ設定
- 索引設定
- 登録する値を作成
- コレクションに値を登録
- 適切な間隔でコミット
- GridStoreインスタンスの解放
時系列コンテナへのデータ登録もコレクションと同様の処理手順で行えます。
5.2 コレクション検索
コレクションに対するデータ検索処理の流れは以下のようになります。
- GridStoreインスタンスの取得
- コレクションの取得
- コレクションを検索
- 検索結果を取得
- GridStoreインスタンスの解放
検索する方法には以下の2種類があります。それぞれの詳細については、『GridDB APIリファレンス』(GridDB_API_Reference.html)を参照してください。
- KVのキーを指定して検索する(get)方法
- KVのバリューに関する条件を指定して検索する(query)方法
時系列コンテナに対するデータ検索もコレクションと同様の処理手順で行えます。
6 プログラム例
今回想定するアプリケーションでは、以下の機能を実現することとします。
- 設備情報の登録
- アラーム履歴の登録
- センサデータの登録
- 異状のある設備情報、センサデータの検索、表示
以下では、前章の実装スキーマを元にして、各機能を実現するクライアントプログラムについて説明します。
なお、サンプルプログラムでは、CSVファイルの読み込みにApache License, Version 2.0のソフトウェアであるopencsvを用いています。opencsvは、GridDB製品の運用ツールでも利用しており、GridDBのクライアントパッケージをインストールすると/usr/griddb/lib/opencsv-3.9.jarに配置されます。
6.1 設備情報の登録
本来の監視システムでは、設備構成および設備仕様を予めデータベースに登録しておく必要があります。処理の簡単化のため、ここでは設備仕様を除いた設備情報を記録したCSVファイルから、データを一括ロードすることとして、処理を行なうサンプルプログラムを以下に示します。大まかな流れは次のとおりです。
- クラスタに接続し、GridStoreインスタンスを取得する。
- コレクション名("equipment_col")を指定し、GridStoreインスタンスに設備情報コレクションを作成し、取得する。
- 検索で使用する索引を作成する。
- CSVファイルを読み出しながら、以下のように繰り返し値を登録する。
- 読み出したCSV行を解析し、登録する設備情報オブジェクトを作成する
- 設備情報コレクションに、作成した設備情報オブジェクトを登録(put)する。
- 想定した繰り返し数に到達した場合には、コミットする。
- 全CSV行を登録したら、最終データをコミットし、取得したGridStoreインスタンスを開放し、終了する。
具体的なサンプルプログラムは以下のようになります。
1: package pvrms; 2: 3: import java.io.FileReader; 4: import java.io.IOException; 5: import java.text.ParseException; 6: import java.util.Properties; 7: 8: import com.opencsv.CSVReader; 9: 10: import com.toshiba.mwcloud.gs.Collection; 11: import com.toshiba.mwcloud.gs.GSException; 12: import com.toshiba.mwcloud.gs.GridStore; 13: import com.toshiba.mwcloud.gs.GridStoreFactory; 14: import com.toshiba.mwcloud.gs.RowKey; 15: 16: // 設備情報 17: class Equip { 18: @RowKey String id; 19: String name; 20: //Blob spec; // 簡単化のため、仕様情報は未使用とする 21: } 22: 23: public class SimplePv0 { 24: 25: /* 26: * CSVファイルから、設備情報をロードする 27: */ 28: public static void main(String[] args) throws GSException, ParseException, IOException { 29: 30: final String equipColName = "equipment_col"; 31: if (args.length != 4) { 32: System.out.println("Usage:pvrms.SimplePv0 Addr Port ClusterName Database "); 33: System.exit(1); 34: } 35: 36: // GridDB接続時のパラメータ設定 37: Properties props = new Properties(); 38: props.setProperty("notificationAddress", args[0]); 39: props.setProperty("notificationPort", args[1]); 40: props.setProperty("clusterName", args[2]); 41: props.setProperty("database", args[3]); 42: props.setProperty("user", "system"); 43: props.setProperty("password", "manager"); 44: GridStore store = GridStoreFactory.getInstance().getGridStore(props); 45: 46: /* 47: * CSVファイルの読み込み 48: * 49: *先頭行はセンサID 50: * センサIDは、センサ名1,センサ名2,センサ名3・・・ 51: *それ以降の行はデータ 同一時刻に発生する各センサの測定値 52: * データは、date,time,センサ1値,ステータス,センサ2値,ステータス, ... 53: */ 54: String dataFileName = "equipName.csv"; 55: CSVReader reader = new CSVReader(new FileReader(dataFileName)); 56: String[] nextLine; 57: 58: // コレクションを作成 59: Collection<String,Equip> equipCol = store.putCollection(equipColName, Equip.class); 60: 61: // カラムに索引を設定 カラム タイプがStringなのでTREE索引 62: equipCol.createIndex("id"); 63: equipCol.createIndex("name"); 64: 65: // 自動コミットモードをオフ 66: equipCol.setAutoCommit(false); 67: 68: //コミット間隔 69: Long commtInterval = (long) 1; 70: 71: //値を登録 72: Equip equip = new Equip(); 73: Long cnt = (long) 0; 74: byte[] b = new byte[1]; 75: b[0] = 1; 76: 77: while ((nextLine = reader.readNext()) != null) { 78: // 設備情報登録 79: equip.id = nextLine[0]; 80: equip.name = nextLine[1]; 81: equipCol.put(equip); 82: cnt++; 83: if(0 == cnt%commtInterval) { 84: // トランザクションの確定 85: equipCol.commit(); 86: } 87: } 88: // トランザクションの確定 89: equipCol.commit(); 90: System.out.println("◆ equip_colコンテナを作成し、ROWを"+cnt+"件登録しました。◆"); 91: // リソースの解放 92: store.close(); 93: reader.close(); 94: } 95: } 96:
登録する equipName.csv ファイルの中身は以下のとおりとします。
panel001_voltage,panel001 panel002_voltage,panel002 panel003_voltage,panel003
6.2 アラーム履歴登録
本来の監視システムでは、センサや設備がアラームを直接送信し、GridDBに格納する流れになります。ここでも処理の簡単化のため、アラーム履歴を記録したCSVファイルから、データを一括ロードするものとして、処理を行なうサンプルプログラムを以下に示します。大まかな流れは次のとおりです。
- クラスタに接続し、GridStoreインスタンスを取得する。
- コレクション名("alert_col")を指定し、GridStoreインスタンスにアラートコレクションを作成し、取得する。
- 検索で使用する索引を作成する。
- CSVファイルを読み出しながら、以下のように繰り返し値を登録する。
- 読み出したCSV行を解析し、登録するアラートオブジェクトを作成する
- アラートコレクションに、作成したアラートオブジェクトを登録(put)する。
- 想定した繰り返し数に到達した場合には、コミットする。
- 全CSV行を登録したら、最終データをコミットし、取得したGridStoreインスタンスを開放し、終了する。
具体的なサンプルプログラムは以下のようになります。
1: 2: package pvrms; 3: 4: import java.io.FileReader; 5: import java.io.IOException; 6: import java.text.ParseException; 7: import java.text.SimpleDateFormat; 8: import java.util.Date; 9: import java.util.Properties; 10: 11: import com.opencsv.CSVReader; 12: 13: import com.toshiba.mwcloud.gs.Collection; 14: import com.toshiba.mwcloud.gs.GSException; 15: import com.toshiba.mwcloud.gs.GridStore; 16: import com.toshiba.mwcloud.gs.GridStoreFactory; 17: import com.toshiba.mwcloud.gs.RowKey; 18: 19: // アラート情報 20: class Alert { 21: @RowKey Long id; 22: Date timestamp; 23: String sensorId; 24: int level; 25: String detail; 26: } 27: 28: public class SimplePv1 { 29: 30: /* 31: * CSVファイルから、アラートデータをロードする 32: */ 33: public static void main(String[] args) throws GSException, ParseException, IOException { 34: 35: final String alertColName = "alert_col"; 36: if (args.length != 4) { 37: System.out.println("Usage:pvrms.SimplePv1 Addr Port ClusterName Database "); 38: System.exit(1); 39: } 40: 41: // GridDB接続時のパラメータ設定 42: Properties props = new Properties(); 43: props.setProperty("notificationAddress", args[0]); 44: props.setProperty("notificationPort", args[1]); 45: props.setProperty("clusterName", args[2]); 46: props.setProperty("database", args[3]); 47: props.setProperty("user", "system"); 48: props.setProperty("password", "manager"); 49: GridStore store = GridStoreFactory.getInstance().getGridStore(props); 50: 51: // CSVファイルの読み込み 52: String dataFileName = "alarmHistory.csv"; 53: CSVReader reader = new CSVReader(new FileReader(dataFileName)); 54: String[] nextLine; 55: 56: //コレクションを作成 57: Collection<Long,Alert> alertCol = store.putCollection(alertColName, Alert.class); 58: 59: // カラムに索引を設定 カラム タイプがDate,StringなのでTREE索引 60: alertCol.createIndex("timestamp"); 61: alertCol.createIndex("level"); 62: 63: // 自動コミットモードをオフ 64: alertCol.setAutoCommit(false); 65: 66: // コミット間隔 67: Long commtInterval = (long) 24; 68: 69: //値を登録 70: SimpleDateFormat format = new SimpleDateFormat("yyyy/MM/dd HH:mm:ss"); 71: Alert alert = new Alert(); 72: Long cnt = (long) 0; 73: while ((nextLine = reader.readNext()) != null) { 74: 75: String dateS = nextLine[0];//2011/1/1 76: String timeS = nextLine[1];//19:00:00 (時) 77: String datetimeS = dateS + " " + timeS ; 78: Date date = format.parse(datetimeS); 79: 80: alert.id = ++cnt; 81: alert.timestamp =date; 82: alert.sensorId = nextLine[2]; 83: alert.level = Integer.valueOf(nextLine[3]); 84: alert.detail = nextLine[4]; 85: 86: alertCol.put(alert); 87: 88: if(0 == cnt%commtInterval) { 89: // トランザクションの確定 90: alertCol.commit(); 91: } 92: } 93: // トランザクションの確定 94: alertCol.commit(); 95: System.out.println("◆ alert_colコンテナを作成し、ROWを"+cnt+"件登録しました。◆"); 96: 97: // リソースの解放 98: store.close(); 99: reader.close(); 100: } 101: } 102:
登録する alarmHistory.csv ファイルの中身は以下のとおりとします。
2015/1/1,20:00:00,panel001_voltage,5,LEVEL_ERROR:LEVEL is Low
6.3 センサデータ登録
本来の監視システムでは、センサが測定した値を直接送信し、GridDBに格納する流れになります。ここでも処理の簡単化のため、センサデータを記録したCSVファイルから、データを一括ロードするものとして、処理を行なうサンプルプログラムを以下に示します。大まかな流れは次のとおりです。
- クラスタに接続し、GridStoreインスタンスを取得する。
- CSVファイルの先頭行を読み出し、以下のように予め、使用する時系列コンテナを作成する。
- まず、先頭のCSV行を解析し、複数のセンサID(=作成する時系列コンテナ名)を取得する。
- 取得された全センサIDについて、GridStoreインスタンスにアラートコレクションを作成する。
- 次に、残りのCSVファイルを読み出しながら、以下のように繰り返し値を登録する。
- 読み出したCSV行を解析し、登録するポイントオブジェクトを作成する
- 作成したポイントオブジェクトを、登録すべき時系列コンテナに登録(put)する。オートコミットのため登録と同時にデータはコミットされる。
- 全CSV行を登録したら、取得したGridStoreインスタンスを開放し、終了する。
具体的なサンプルプログラムは以下のようになります。
1: 2: package pvrms; 3: 4: import java.io.FileReader; 5: import java.io.IOException; 6: import java.text.ParseException; 7: import java.text.SimpleDateFormat; 8: import java.util.Date; 9: import java.util.Properties; 10: 11: import com.opencsv.CSVReader; 12: 13: import com.toshiba.mwcloud.gs.GridStore; 14: import com.toshiba.mwcloud.gs.GridStoreFactory; 15: import com.toshiba.mwcloud.gs.RowKey; 16: import com.toshiba.mwcloud.gs.TimeSeries; 17: 18: // センサデータ 19: class Point { 20: @RowKey Date time; 21: double value; 22: String status; 23: } 24: 25: public class SimplePv2 { 26: 27: /* 28: * CSVファイルから、時系列データをロードする 29: */ 30: public static void main(String[] args) throws ParseException, IOException { 31: 32: if (args.length != 4) { 33: System.out.println("Usage:pvrms.SimplePv2 Addr Port ClusterName Database "); 34: System.exit(1); 35: } 36: 37: // GridDB接続時のパラメータ設定 38: Properties props = new Properties(); 39: props.setProperty("notificationAddress", args[0]); 40: props.setProperty("notificationPort", args[1]); 41: props.setProperty("clusterName", args[2]); 42: props.setProperty("database", args[3]); 43: props.setProperty("user", "system"); 44: props.setProperty("password", "manager"); 45: 46: GridStore store = GridStoreFactory.getInstance().getGridStore(props); 47: 48: /* 49: * CSVファイルの読み込み 50: * 51: *先頭行はセンサID 52: * センサIDは、 センサ名1,センサ名2,センサ名3・・・ 53: *それ以降の行はデータ 同一時刻に発生する各センサの測定値 54: * データは、 date,time,センサ1値,ステータス,センサ2値,ステータス, ... 55: */ 56: 57: String dataFileName = "sensorHistory.csv"; 58: CSVReader reader = new CSVReader(new FileReader(dataFileName)); 59: String[] nextLine; 60: nextLine = reader.readNext(); 61: 62: //センサIDを読み込み、時系列を作成 63: String[] tsNameArray = new String[nextLine.length]; 64: 65: for(int j = 0; j < nextLine.length; j++) { 66: tsNameArray[j] = nextLine[j]; 67: store.putTimeSeries(tsNameArray[j], Point.class); 68: } 69: 70: //各時系列に値を登録 71: SimpleDateFormat format = new SimpleDateFormat("yyyy/MM/dd HH:mm:ss"); 72: Point point = new Point(); 73: Long cnt = (long) 0; 74: while ((nextLine = reader.readNext()) != null) { 75: String dateS = nextLine[0];//2011/1/1 76: String timeS = nextLine[1];//19:00:00 (時刻) 77: String datetimeS = dateS + " " + timeS ; 78: Date date = format.parse(datetimeS); 79: for(int i = 0, j = 2; j < nextLine.length; i++, j+=2) { 80: TimeSeries<Point> ts = store.getTimeSeries(tsNameArray[i], Point.class); 81: point.time = date; 82: point.value = Double.valueOf(nextLine[j]); 83: point.status = nextLine[j+1]; 84: //指定した時刻でデータを登録 現在時刻の場合はts.append(point) 85: //autocommitなので1件ずつトランザクションは確定 86: ts.put(date,point); 87: } 88: cnt++; 89: } 90: System.out.println("◆ 時系列コンテナ"+tsNameArray.length+"件を作成し、ROWを"+cnt+"件ずつ登録しました。◆"); 91: // リソースの解放 92: store.close(); 93: reader.close(); 94: } 95: } 96:
登録する sensorHistory.csv ファイルの中身は以下のとおりとします。
panel001_voltage,panel002_voltage,panel003_voltage 2015/1/1,19:50:00,1.00,None,2.30,None,3.51,None 2015/1/1,19:53:00,0.30,None,2.80,None,3.331,None 2015/1/1,19:57:00,0.20,None,2.87,None,3.43,None 2015/1/1,19:58:00,0.20,None,2.47,None,3.481,None 2015/1/1,20:00:00,0.00,LEVEL_ERROR,2.76,None,3.21,None 2015/1/1,20:05:00,0.50,None,2.56,None,3.55,None 2015/1/1,21:00:00,2.98,None,2.76,None,3.56,None 2015/1/1,22:00:00,2.98,None,2.88,None,3.57,None 2015/1/1,23:00:00,2.98,None,2.76,None,3.59,None 2015/1/2,0:00:00,2.98,None,2.46,None,3.21,None 2015/1/2,1:00:00,2.98,None,2.76,None,3.28,None
6.4 異状監視
格納された、設備情報、センサデータ、アラートデータを参照し、異状監視処理(24時間以内に発生した重大アラートについて、設備情報と直前の時系列データを表示する)を模擬的に実現するサンプルプログラムを以下に示します。大まかな流れは次のとおりです。
- クラスタに接続し、GridStoreインスタンスを取得する。
- コレクション名("alert_col")を指定し、GridStoreインスタンスからアラートコレクションを取得する。
- 取得したアラートコレクションから、24時間以内の重大アラート(level>3)を検索するため、levelとtimeに関する条件で検索を行う。値に関する条件での検索のため、TQLを用いた検索を行う。
- 検索結果で得られた重大アラートについて、以下のように設備情報と直前の時系列データを検索する。
- まず、重大アラートのセンサID文字列から、設備ID文字列部分を切り出す。
- 次に、コレクション名("equipment_col")を指定し、GridStoreインスタンスから設備情報コレクションを取得する。
- 切り出した設備IDをキーとして、取得した設備情報コレクションから設備情報を取得(get)する。
- さらに、センサIDを名前に持つ時系列コンテナをGridStoreインスタンスから取得する。
- 取得した時系列コンテナから、重大アラート発生の10分前から発生時点までの時系列データを検索する。timeの時刻範囲を指定する条件で検索を行う。
具体的なサンプルプログラムは以下のようになります。
1: 2: package pvrms; 3: 4: import java.io.IOException; 5: import java.text.ParseException; 6: import java.text.SimpleDateFormat; 7: import java.util.Date; 8: import java.util.Locale; 9: import java.util.Properties; 10: 11: import com.toshiba.mwcloud.gs.Collection; 12: import com.toshiba.mwcloud.gs.GSException; 13: import com.toshiba.mwcloud.gs.GridStore; 14: import com.toshiba.mwcloud.gs.GridStoreFactory; 15: import com.toshiba.mwcloud.gs.Query; 16: import com.toshiba.mwcloud.gs.RowSet; 17: import com.toshiba.mwcloud.gs.TimeSeries; 18: import com.toshiba.mwcloud.gs.TimeUnit; 19: import com.toshiba.mwcloud.gs.TimestampUtils; 20: 21: public class SimplePv3 { 22: 23: /* 24: * 24時間以内に発生した重大アラートについて、設備情報と直前の時系列データを表示する 25: * 本サンプルでは、alert_colに登録した時刻に合わせて検索します。 26: */ 27: public static void main(String[] args) throws GSException, ParseException, IOException { 28: 29: final String alertColName = "alert_col"; 30: final String equipColName = "equipment_col"; 31: 32: if (args.length != 4) { 33: System.out.println("Usage:pvrms.SimplePv3 Addr Port ClusterName Database "); 34: System.exit(1); 35: } 36: 37: // GridDB接続時のパラメータ設定 38: Properties props = new Properties(); 39: props.setProperty("notificationAddress", args[0]); 40: props.setProperty("notificationPort", args[1]); 41: props.setProperty("clusterName", args[2]); 42: props.setProperty("database", args[3]); 43: props.setProperty("user", "system"); 44: props.setProperty("password", "manager"); 45: GridStore store = GridStoreFactory.getInstance().getGridStore(props); 46: Collection<Long,Alert> alertCol = store.getCollection(alertColName, Alert.class); 47: 48: //アラートの監視時間を設定 現在時刻の場合 new Date(System.currentTimeMillis()) 49: SimpleDateFormat sf = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss.SSS",Locale.JAPAN); 50: Date tm1=sf.parse("2015-01-02 08:00:00.000"); 51: 52: System.out.println("◆ alert_colから指定した日時の24時間前以降の重大アラート(>レベル3)を検索◆"); 53: 54: //String from = TimestampUtils.format( TimestampUtils.add(new Date(System.currentTimeMillis()), -24, TimeUnit.HOUR) ); 55: String from = TimestampUtils.format( TimestampUtils.add(tm1, -24, TimeUnit.HOUR) ); 56: Query<Alert> alertQuery = alertCol.query( "select * where level > 3 and " + 57: "timestamp > " + "TIMESTAMP('" + from + "')" ); 58: 59: // 検索式を出力 検索時の時刻はUTC 60: System.out.println("select * where level > 3 and " + 61: "timestamp > " + "TIMESTAMP('" + from + "')"); 62: RowSet<Alert> alertRs = alertQuery.fetch(); 63: 64: System.out.println("◆ 重大アラートが発生したセンサの設備情報とアラート直前10分のデータを表示◆"); 65: System.out.println("◆ アラート数 : "+alertRs.size()+" ◆"); 66: while( alertRs.hasNext() ) { 67: Alert seriousAlert = alertRs.next(); 68: 69: // センサIDとセンサ種別を取得 70: String sensorId = seriousAlert.sensorId; 71: String sensorType = sensorId.substring(sensorId.indexOf("_")+1); 72: 73: // 設備を検索 74: Collection<String,Equip> equipCol = store.getCollection(equipColName, Equip.class); 75: Equip equip = equipCol.get(sensorId); 76: 77: System.out.println("[Equipment] " + equip.name + " (sensor) "+ sensorType); 78: System.out.println("[Detail] " + seriousAlert.detail); 79: 80: //直前の時系列データを検索 81: String tsName = seriousAlert.sensorId; 82: TimeSeries<Point> ts = store.getTimeSeries(tsName, Point.class); 83: Date endDate = seriousAlert.timestamp; 84: Date startDate = TimestampUtils.add(seriousAlert.timestamp, -10, TimeUnit.MINUTE); 85: RowSet<Point> rowSet = ts.query(startDate, endDate).fetch(); 86: while (rowSet.hasNext()) { 87: Point ret = rowSet.next(); 88: System.out.println( 89: "[Result] " +sf.format(ret.time) + 90: " " + ret.value + " " + ret.status); 91: } 92: System.out.println(""); 93: } 94: 95: // リソースの解放 96: store.close(); 97: } 98: } 99:
6.5 プログラムの実行結果
サンプルプログラムの実行は以下の通りです。
$ export CLASSPATH=:/usr/share/java/gridstore.jar:/usr/java:/usr/griddb/lib/opencsv-3.9.jar:.
$ ls
alarmHistory.csv equipName.csv pvrms sensorHistory.csv
$ java pvrms.SimplePv0 239.0.0.150 31999 demo public
◆ equip_colコンテナを作成し、ROWを3件登録しました。◆
$ java pvrms.SimplePv1 239.0.0.150 31999 demo public
◆ alert_colコンテナを作成し、ROWを1件登録しました。◆
$ java pvrms.SimplePv2 239.0.0.150 31999 demo public
◆ 時系列コンテナ3件を作成し、ROWを11件ずつ登録しました。◆
$ java pvrms.SimplePv3 239.0.0.150 31999 demo public
◆ alert_colより、2015/1/2 8:00の24時間前以降の重大アラート(>レベル3)を検索◆
select * where level > 3 and timestamp > TIMESTAMP('2014-12-31T23:00:00.000Z')
◆ 重大アラートが発生したセンサの設備情報とアラート直前10分のデータを表示◆
◆ アラート数 : 1 ◆
[Equipment] panel001 (sensor) voltage
[Detail] LEVEL_ERROR:LEVEL is low
[Result] 2015-01-01 19:50:00.000 1.0 None
[Result] 2015-01-01 19:53:00.000 0.3 None
[Result] 2015-01-01 19:57:00.000 0.2 None
[Result] 2015-01-01 19:58:00.000 0.2 None
[Result] 2015-01-01 20:00:00.000 0.0 LEVEL_ERROR