5. ご利用の手引き¶
5.1. リポジトリー管理機能でGitサーバーにssh接続する¶
リポジトリー管理機能でGitサーバーにssh接続する場合は、以下のようにssh接続の設定を行います。
(1)公開鍵と秘密鍵の作成
ダッシュボード画面右上からNew→Terminalを選択し、terminal画面を開きます。
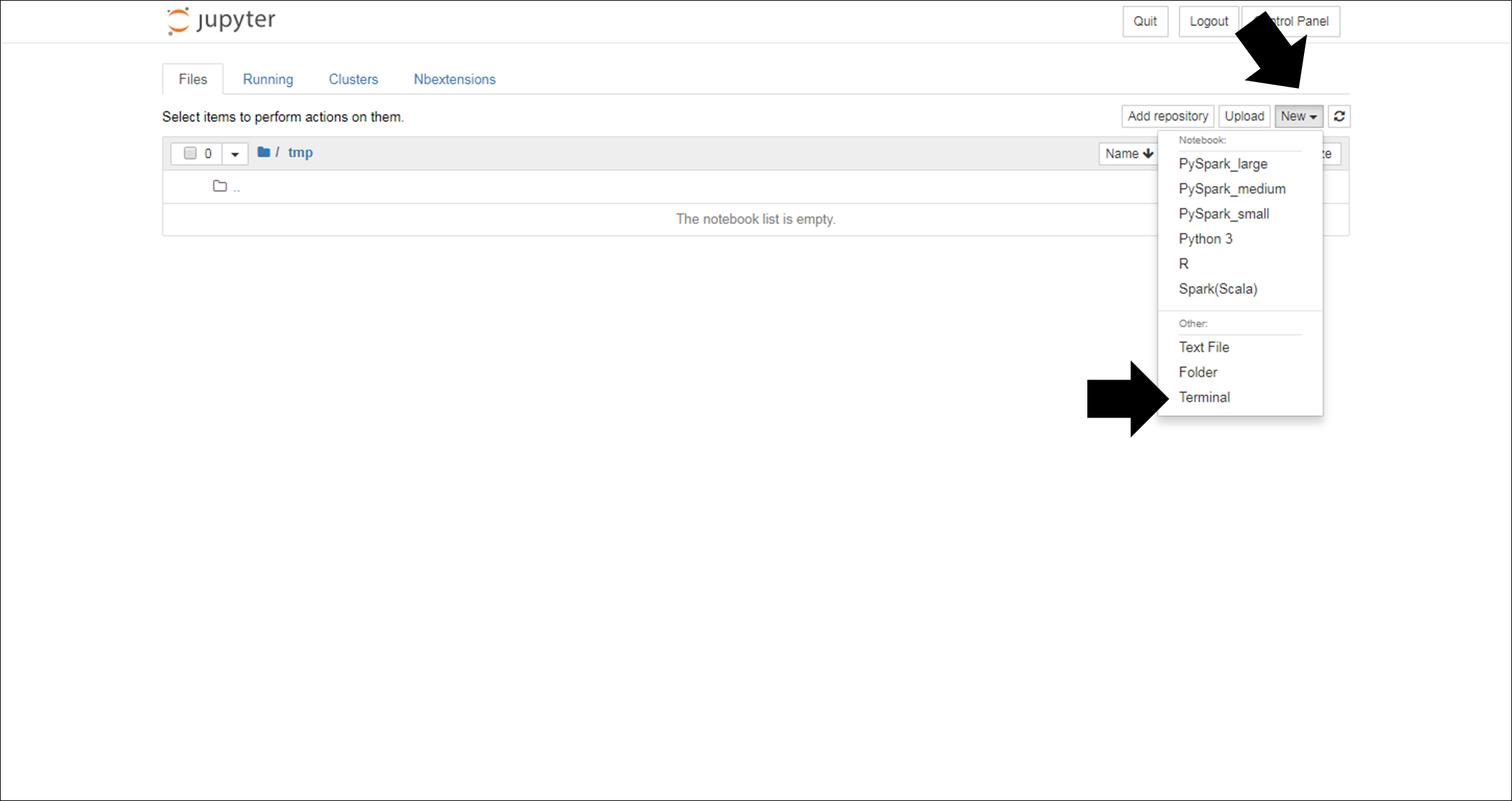
terminal画面で以下のコマンドを実行し、sshの公開鍵と秘密鍵を作成します。コマンドが完了するまでEnterキーを入力してください。
$ ssh-keygen -t rsa -f git_rsa
(中略)
The key's randomart image is:
+---[RSA 2048]----+
| ++o .o*o |
| ... + o.o |
| . o. o . |
| . = . oo * E |
| = . ++S* @ |
| . . ..=+oB . |
| . o+.o . |
| .o= o |
| .+oo |
+----[SHA256]-----+
上記のコマンドにより、git_rsa、git_rsa.pubという二つのファイルが作成されます。
(2)configファイルの作成
ホームディレクトリに、以下の内容のconfigというファイルを作成します。
Host (設定名)
HostName (ホスト名またはIPアドレス)
User (Gitサーバーログイン時のユーザー名)
IdentityFile (git_rsaファイルパス)
設定の例は以下の通りです。
Host gitlab
HostName 10.0.0.1
User username
IdentityFile ~/.ssh/git_rsa
(3)Gitサーバーに公開鍵を登録する
git_rsa.pubを開き、クリップボードに内容をコピーします。
開く際にはTerminal画面で cat git_rsa.pub コマンドを実行するか、
Jupyterのダッシュボード画面からgit_rsa.pubファイルを開きます。
コピーした中身をGitサーバーに登録します。登録方法はGitサーバーによって異なります。 ここでは、GitLabに登録する場合を説明します。
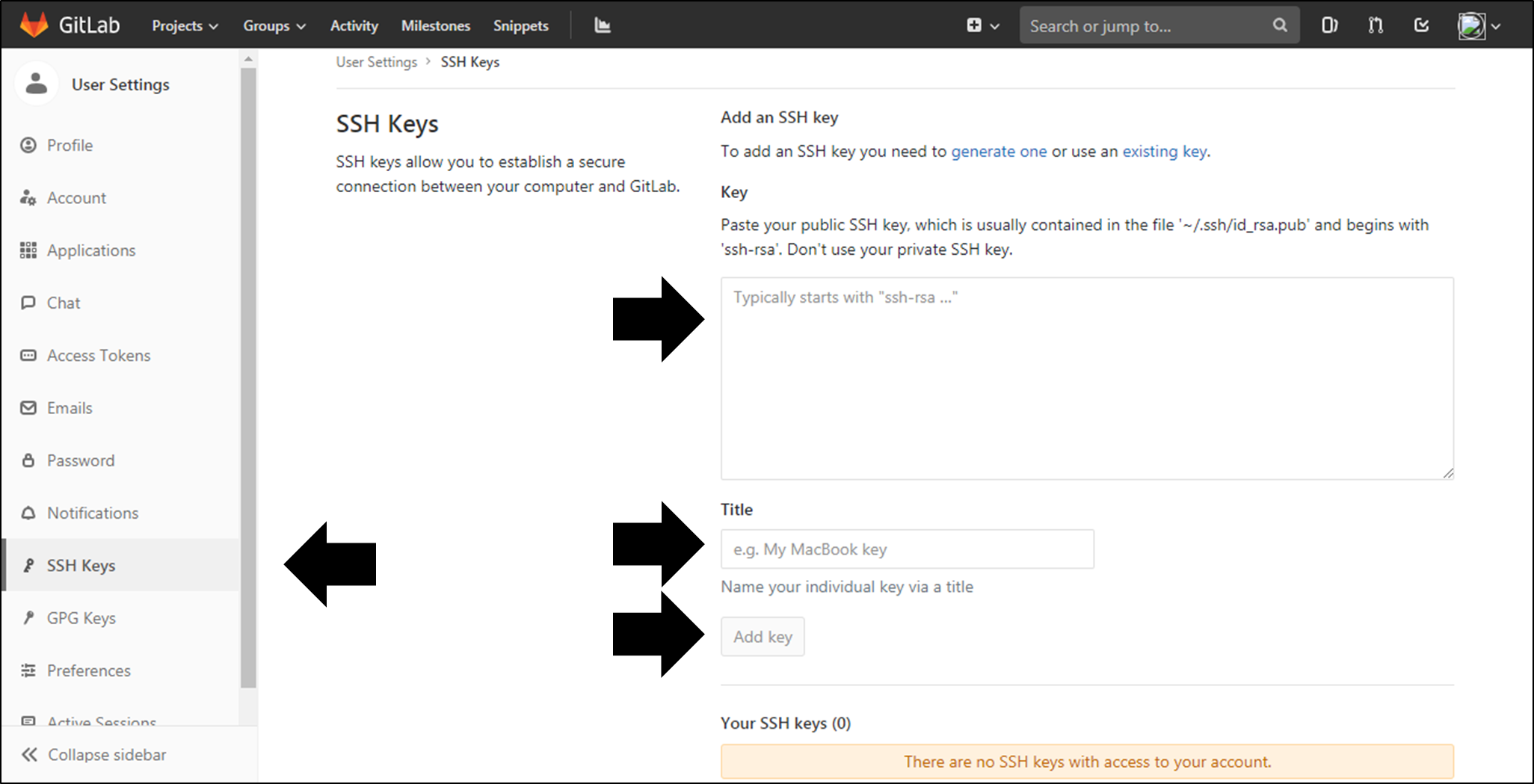
- GitLabにログインし、User Settings画面を開いて左ペインの「SSH Key」を選択する。
- SSH Keys画面の入力欄にコピーした内容を貼りつけ、任意のTitleを入力してから「Add key」をクリックする。
以上でssh接続の設定は完了です。
5.2. 大規模データ処理の手引き¶
■ 2種類のDataFrame
GridData AnalyticsのノートブックでPythonスクリプトを記述する際に、大規模データを扱うためのデータモデルとしてDataFrameがあります。 HDFS上のファイルやGridDBのコンテナなどのテーブル構造でないデータに対し、テーブルスキーマを定義した上でデータを操作することができます。
GridData Analyticsで利用できるDataFrameには、pysparkのものとpandasのものの2種類があります。 いずれも用途や操作方法は似ていますが、互換性がない別種のデータ形式であることに注意してください。 pysparkのDataFrameはGridData Analytics Scale Serverによって、インストールしたマシンごとに並列分散して読み書き、処理が行われます。 これに対し、pandasは処理を分散させず、GridData Analytics Serverのサーバ単体で全データが保持され、処理が行われます。 したがって、大規模なデータを高速に扱いたい場合は、GridData Analytics Scale Serverを導入してpysparkを使用することを推奨します。 一方、pandasはGridData Analytics Server単体で利用できることと、処理のオーバヘッドがpysparkに比べて小さいことから、一般的なサイズのデータの分析に適しています。
以下は、pandasとpysparkでHDFS上のCSVファイルを読み書きした場合の処理時間の比較です。
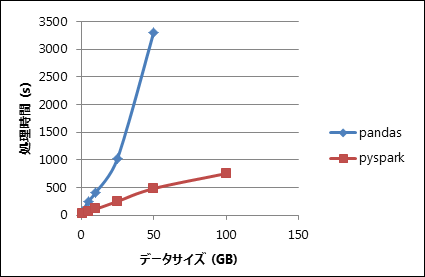
なお、この処理時間を測定した環境は以下の通りです。
- GridData Analytics Server
- 8コアCPU、32GBメモリのサーバー×1台
- GridData Analytics Scale Server
8コアCPU・32GBメモリのサーバー×3台
spark.driver.memoryパラメーター=16GB
spark.executor.memoryパラメーター=16GB
spark.driver.maxResultSizeパラメーター=16GB
pysparkは以下のコードのように、HDFS上のCSVファイルを直接DataFrameに読み出すことができます。この処理は分散して実行されます。
import findspark
findspark.init()
from pyspark.sql import SparkSession
spark = SparkSession.builder.appName("Example").getOrCreate()
DF = spark.read.format("csv").load("hdfs://griddataha/user/test/test.csv")
pandasはHDFSのファイルを直接読み出すことができないため、 一旦CSVファイルをローカルファイルとして取得してから、以下のコードのようにDataFrameに読み出します。
import pandas as pd
DF = pd.read_csv("/home/test/test.csv")
また、pysparkでデータをDataFrameに一度読み出したのち、pandasのDataFrameに変換できます。 pysparkのDataFrameには、pandasのDataFrameにデータを変換するためのtoPandas()メソッドが用意されています。
pysparkDF = spark.read.format("csv").load("hdfs://griddataha/user/test/test.csv")
pandasDF = pysparkDF.toPandas()
しかし、GridData Analyticsで使用するSpark 2.3.1ではtoPandas()メソッドのメモリ効率が悪く、大規模データを扱えません。 たとえば上記の環境では3GBのデータまでは変換できますが、4GBのデータはOutOfMemoryErrorが発生し、DataFrameに変換できません。 この場合、pysparkのDataFrameを一旦CSVファイルとして永続化し、pandasのread_csv()メソッドで読み出すことを推奨します。 こちらの方法であれば、toPandas()よりも大規模なデータをより高速に処理できます。 上記の環境の場合では、50GB以上のデータをpandasで処理できることを確認しています。
pysparkDF = spark.read.format("csv").load("hdfs://griddataha/user/test/test.csv")
pysparkDF.write.format("csv").save("/home/test/test_tmp.csv")
pandasDF = pd.read_csv("/home/test/test_tmp.csv")
5.3. GPU活用の手引き¶
GridData Analyticsでは、CuPyとChainerの二つのライブラリーをGPU上で実行できます。 GPU上で実行することにより、CPU上での実行に比べて処理速度を大幅に高速化することができます。
なお、一連の処理時間を測定した環境は末尾に記載します。
■ CuPyを使用する
CuPyのAPIはNumPyのAPIと互換性があります。 そのため、NumPyで行っていた計算をそのままCuPyに置き換えることができます。
#import numpy as np
import cupy as cp
#ndata = np.array([[1, 2, 3], [4, 5, 6]], np.int32)
cdata = cp.array([[1, 2, 3], [4, 5, 6]], cp.int32)
また、Chainerのto_gpu()メソッドを使用し、NumPyオブジェクトをCuPyオブジェクトに変換できます。
import chainer.cuda
import numpy as np
import cupy as cp
ndata = np.array([[1, 2, 3], [4, 5, 6]], np.int32)
cdata = chainer.cuda.to_gpu(ndata)
同様に、to_cpu()メソッドを使用し、CuPyオブジェクトをNumPyオブジェクトに変換できます。
■ CuPyで処理を高速化する
NumPyの代わりにCuPyを使用し、GPU上で処理することで、処理を高速化できる可能性があります。 しかし、どのような処理でも高速化できるわけではありません。NumPyよりもCuPyの処理が高速化するのは、以下のような場合です。
- 大規模なデータを処理する場合
- 集約処理や複雑な処理が発生せず、配列や行列の要素ごとに処理が行われる場合
以下、それぞれの具体例を示します。
- 大規模なデータを処理する場合
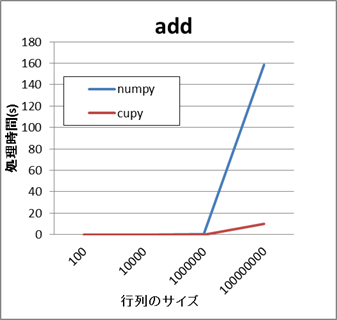
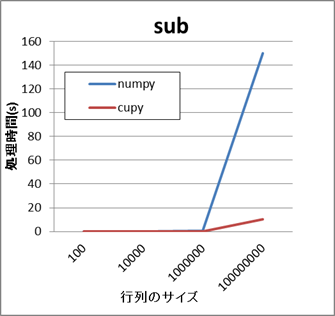
以下は大規模な行列の演算の処理時間について、APIごとにNumPyとCuPyを比較した結果です。
- NumPyとCuPyの比較結果(add,sub)
- NumPyとCuPyの比較結果(sin,matmul)
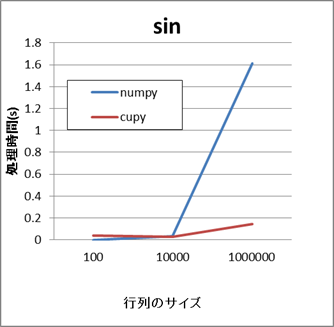
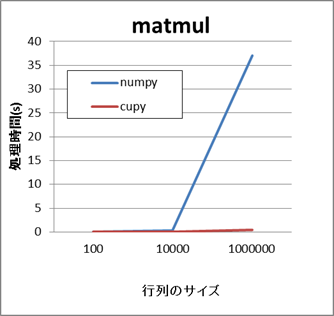
これらの例では、行列のサイズが小さい場合はいずれのAPIもさほど差がありません。 しかし、行列のサイズが数万から数十万以上になると、CuPyの方がより短い時間で処理できます。
- 集約処理や複雑な処理が発生せず、配列や行列の要素ごとに処理が行われる場合
大規模なデータを処理する場合でも、NumPyとCuPyの処理時間に差がない場合や、逆にCuPyの方が時間がかかる場合があります。
すべての要素に対して集約処理を行うAPIの場合、CuPyの方が処理に時間がかかります。
- NumPyとCuPyの比較結果(sum,argmax)
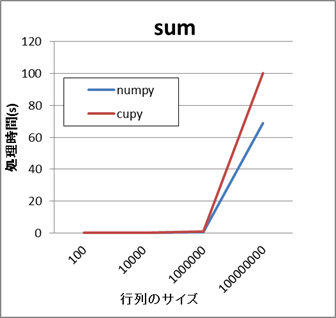
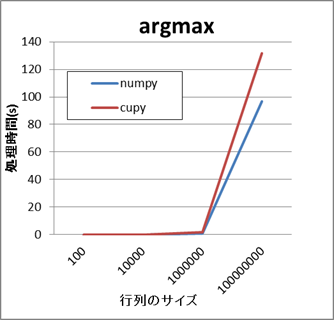
同様に、行列分解のAPIの場合もCuPyの方が処理に時間がかかります。
- NumPyとCuPyの比較結果(qr,svd)
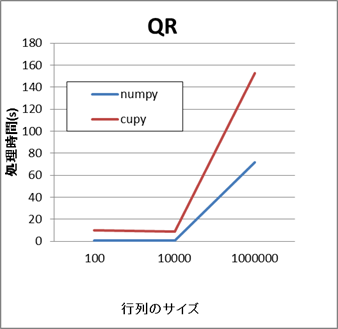
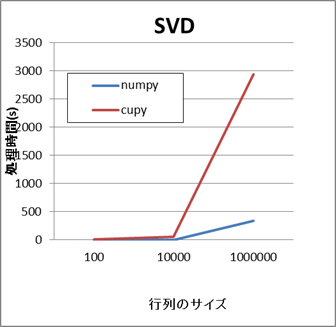
高速化を目的としてCuPyを使用する場合は、適切なAPIの選択と、十分な試行が重要になります。
■ GPU上でChainerを実行する
Chainerを使用し学習モデルを作成する場合、GPUを使用することで、モデルの作成時間を短縮できる可能性があります。
GPUを使用するには、モデルを作成するコードに対し以下の修正を行います。
- NumPyの代わりにCuPyを使用する
- 作成したmodelオブジェクトに対し、model.to_gpu(gpu_id)を呼ぶ
■ GPUで処理を高速化する
以下はMNISTのデータセットから、数値画像分類用の学習モデルを作成する処理時間について、epoch数を変更しながら実行した結果です。
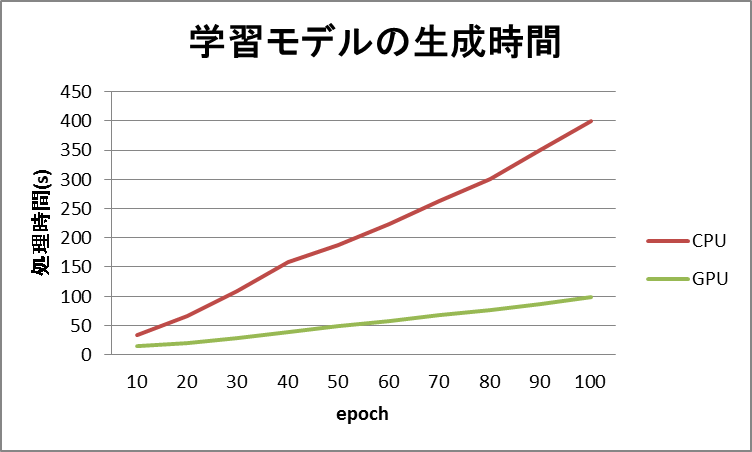
epoch数以外の主なパラメーターは以下の通りです。
- unit:500
- batchsize:1024
- frequency:-1
図のように、GPUを使用することでいずれのepochの場合もモデルの生成時間が短縮されることがわかります。
しかし、どのような条件においてもGPUのほうが処理時間が短縮されるわけではありません。 たとえば、上記のパラメーターでUnit数のみをより小さい値にすると、CPUとGPUの処理時間はほとんど同じになります。 同様に、batchsizeパラメーターを小さい値にしても、CPUとGPUの処理時間は変わらなくなります。
高速化のためには、これらのパラメーターのチューニングと十分な試行が重要です。
■ 測定環境
上記の測定を実施した環境は以下の通りです。
- GridData Analytics Server
4コアCPU、60GBメモリのサーバー×1台
GPU:Tesla K80
5.4. PySparkカーネルの使い分け¶
GridData Analyticsでは、PySparkを使用するために、リソースの異なる3つのPySparkカーネルが用意されています。 各カーネルは、GridData Analyticsの動作環境を基準に、以下のように設定されています。
- PySpark_smallカーネル (small)
1台のサーバーで処理を実行します。
- PySpark_mediumカーネル (medium)
複数台のサーバーで並列に処理を実行します。
複数のジョブを並列に実行することができます。
- PySpark_largeカーネル (large)
mediumより多くのリソースを使用し、複数台のサーバーで並列に処理が行われます。
このカーネルを実行している間、複数のジョブを並列に実行することはできません。
各カーネルの詳細なパラメーターは Sparkクラスター上で処理を実行する を参照してください。
以下は、各カーネルでHDFS上のCSVファイルをワードカウントした場合の処理時間の比較です。

ジョブの並列度はsmall→mediumで6倍、medium→largeで3倍になります。
その結果、処理時間もsmall > medium > largeと減少します。
なお並列度に対して線形に処理時間が減らない理由として、以下の2要因があります。
- タスク間シャッフルの回数、総量が増えた
- 複数のタスクがサーバーリソースを共有するため、リソースの待ちが発生した
また、カーネルによりジョブの並列度だけでなく、確保するメモリー量も異なります。 扱うデータサイズが大きく、メモリーにデータが乗り切らない場合、より大きなカーネルを使用してください。
用意されたPySparkカーネル以外のパラメーターを設定する場合は、Python3カーネルを利用するか、新たなPySparkカーネルを作成してください。