5. 運用手順¶
本章では、GridData Analyticsの運用手順を説明します。
5.1. GridData Analytics Serverの運用手順¶
5.1.1. Jupyterを起動する¶
以下の手順は管理者ユーザーで実行してください。
[RHEL / CentOS 6]
# service jupyter start
[RHEL / CentOS 7]
# systemctl start jupyter
5.1.2. Jupyterを停止する¶
以下の手順は管理者ユーザーで実行してください。
[RHEL / CentOS 6]
# service jupyter stop
[RHEL / CentOS 7]
# systemctl stop jupyter
注釈
Jupyterを停止した際に、Jupyterが使用しているプロキシサーバーが再起動する場合があります。 その後、Jupyterを起動すると「Error 503: Proxy Target Missing. 」や 「Address already in use.」、「Name or service not known.」というエラーログが出力され、Jupyterが正常に起動しません。 その場合は、以下のようにプロキシサーバーのプロセスを停止してから、再度Jupyterを起動してください。
# (RHEL / CentOS6の場合) # service jupyter stop # sudo pkill node # (RHEL / CentOS7の場合) # systemctl stop jupyter # sudo pkill node
5.1.3. Jupyterを再起動する¶
以下の手順は管理者ユーザーで実行してください。
[RHEL / CentOS 6]
# service jupyter restart
[RHEL / CentOS 7]
# systemctl restart jupyter
注釈
プロセスが終了するタイミングによっては、Jupyterの再起動が失敗する場合があります。 その場合は、コマンドを再度実行してください。
5.1.4. ユーザーを追加する¶
以下では、user1ユーザーを新規に追加する例で説明します。パスワードはpassword1とします。
以下の手順はgriddataユーザーで実行してください。
$ cd /home/griddata/analytics
$ sh user.sh -a user1 password1
$ sh distribute_sample.sh -u user1
-a の代わりに --add オプションも使用できます。データ配布用のスクリプトdistribute_sample.shに関しては、 ノートブックやデータをユーザーに配布する を参照してください。
このスクリプトによって、以下の処理が実行されます。
サーバー上に、指定したユーザー名とパスワードのLinuxユーザーを新規に作成します。
Gitがインストール済みの場合、以下の内容でGitの設定ファイルにユーザーを登録します。
ユーザー名 メールアドレス (ユーザー名) (ユーザー名)@example.com 注釈
ここで設定したメールアドレスに対し、Gitからメールを送信することはありません。
HDFSが利用可能な場合、HDFS上に以下のユーザー用ディレクトリーを作成します。
ディレクトリ名 ユーザー権限 グループ権限 /user/(ユーザー名) ユーザー名 jupyter
5.1.5. ユーザーを削除する¶
以下では、user1ユーザーを削除する例で説明します。パスワードはpassword1とします。
以下の手順はgriddataユーザーで実行してください。
$ cd /home/griddata/analytics
$ sh user.sh -d user1 password1
-d の代わりに --delete オプションも使用できます。
このスクリプトによって、以下の処理が実行されます。
- 指定したユーザーのLinuxユーザーとホームディレクトリーを削除します。
- HDFSが利用可能な場合、HDFS上にあるユーザ用ディレクトリーを削除します。
利用ユーザーやgriddataユーザーのプロセスが残っているためにユーザーが削除できなかった場合は、以下の手順でプロセスを停止してください。
$ sudo ps aux | grep user1
$ sudo kill -9 <PID>
注釈
ホームディレクトリーを削除すると、ホームディレクトリー上にある、該当するユーザーが作成したノートブックなどのファイルも削除されます。 ノートブックを残す場合、あらかじめ各ファイルを別ディレクトリーに移動してください。 また、以下を実行すると、ホームディレクトリーを残したままLinuxユーザーを削除できます。
$ sudo userdel user1
5.1.6. ノートブックやデータをユーザーに配布する¶
ノートブックや分析用データをgriddataユーザーから別のユーザーにサンプルとして配布することができます。
以下では、user1ユーザーとuser2ユーザーにnotebookdir1ディレクトリーを配布する例を元に説明します。
以下の手順はgriddataユーザーで実行してください。
$ cd /home/griddata/analytics
$ sh distribute_sample.sh -u user1,user2 -n /home/griddata/notebookdir1
配布用スクリプトdistribute_sample.shの仕様は以下の通りです。
distribute_sample.sh [-u|--user] ユーザー名1,ユーザー名2,... [追加オプション]
distribute_sample.shは配布元のディレクトリーにあるノートブックとデータのファイルを、指定したユーザーのディレクトリーに再帰的にコピーします。
-u または --user オプションで配布するユーザーを指定します。複数のユーザーに配布する場合はコンマ区切りでユーザー名を指定します。
配布先は、ノートブックが/home/<ユーザー名>/examples、データが/home/<ユーザー名>/examples/dataになり、変更はできません。
配布先に同名のファイルがある場合は上書きします。
配布先のファイルを上書きしない場合や、別の配布元ディレクトリーを指定する場合は、追加オプションを使用します。
| オプション | 引数 | 説明 |
|---|---|---|
-d | --diff |
- | 配布先に同名のファイルがある場合は、そのファイルを配布しません。 |
-n | --note |
notebook_directory | 配布するノートブックのディレクトリーを指定します。省略した場合は/home/griddata/analytics/examplesを参照します。 |
-f | --file |
data_directory | 配布するデータのディレクトリーを指定します。省略した場合は/home/griddata/analytics/examples/dataを参照します。 |
5.1.7. Gitがインストールされていないサーバーでリビジョン管理機能とリポジトリー管理機能を利用する¶
GitがインストールされていないサーバーにGridData Analytics Serverをインストールした場合、リビジョン管理機能とリポジトリー機能は利用できません。 GridData Analytics Serverのインストール後に、あとからリビジョン管理機能やリポジトリー管理機能を有効にしたい場合は、 以下の手順を実行してください。
(1)Gitをインストールします。 動作環境 に記載されたバージョンをインストールしてください。
以下の手順は、GridData Analytics Serverのユーザーごとに実行してください。以下はユーザーtestの場合を例に説明します。
(2)ホームディレクトリーで、ローカルリポジトリーを作成します。ユーザー名とメールアドレスは任意です。他のユーザーと重複しない値を設定してください。
$ cd
$ git init
$ git config --global user.name "test"
$ git config --global user.email test@example.com
(3)Jupyterを起動中の場合は、 Jupyterを再起動する の手順でJupyterを再起動します。
以上で設定は完了です。
5.1.8. 別のPython実行環境やカーネルを作成する¶
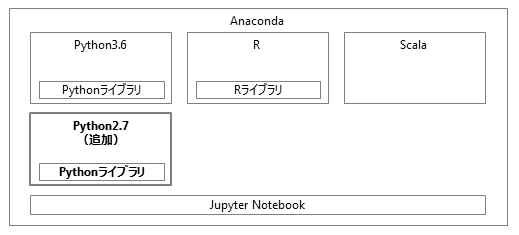
GridData Analyticsでは、Python3.6の実行環境と各種ライブラリー群がインストールされており、初期状態ですぐに利用することができます。
さらに、下図のように、別のPython実行環境を追加できます。
以下のような場合には、別の実行環境の作成を検討してください。
- 異なるバージョンのPythonを使用したい
- Python3.6以外のバージョンのPythonでもノートブックの実行を確かめたい場合などに、別の実行環境を作成して複数のPythonを使い分けることができます。
- デフォルトの環境と異なるバージョンのライブラリーを使用したい
- 異なる環境を作成してライブラリーを追加することで、バージョンの変更による依存ライブラリーへの影響を防ぐことができます。
- pipコマンドなど、condaコマンド以外の方法でライブラリーを追加したい
- デフォルトの環境に対してcondaコマンド以外の方法でライブラリーを追加すると、不具合が起こる可能性があります。詳細は Pythonライブラリーを追加する を参照してください。
また、デフォルトのPython実行環境や追加した実行環境に対し、Pythonカーネルを追加することができます。

初期状態ではデフォルトのPython実行環境にPython3カーネルと3種のPySparkカーネルが作成されています。 他の環境のカーネルを利用することはできないため、別の実行環境を作成した場合、その環境で用いるPythonカーネルを別途作成する必要があります。
別の実行環境の作成とカーネルの追加¶
本項では、Python2.7の実行環境を追加する場合を説明します。
以下の手順はgriddataユーザーで実行してください。
(1)Python2.7の実行環境を作成します。
$ conda create -n 実行環境名 python=2.7
(2)作成した実行環境上にカーネルを作成し、Jupyterに追加します。
$ source activate 実行環境名
(実行環境名) $ conda install notebook ipykernel
(実行環境名) $ ipython kernel install --name カーネル名 --display-name カーネル名 --prefix /home/griddata/analytics/anaconda/
(実行環境名) $ source deactivate
注釈
新たに作成した実行環境は、初期状態ではライブラリーがインストールされていません。condaコマンドなどを使用し、必要なライブラリーをインストールしてください。
Jupyterでそのカーネルを選択することで、すべてのユーザーが追加した実行環境とライブラリー、カーネルを利用することができます。
注釈
カーネルの作成は、デフォルトのPython環境でも行うことができます。 source activateコマンドで環境を切り替えずに、デフォルトのPython環境のままで以下のコマンドを実行してください。
$ ipython kernel install --name カーネル名 --display-name カーネル名 --prefix /home/griddata/analytics/anaconda/
カーネルのカスタマイズ¶
既存のカーネルや 別の実行環境の作成とカーネルの追加 の手順により新規に作成したカーネルは、起動パラメーター変更などのカスタマイズをすることができます。
ここではPySparkカーネルをカスタマイズする場合を説明します。
(1)以下の設定ファイルを修正します。
/home/griddata/analytics/anaconda/share/jupyter/kernels/<カーネル名>/kernel.json
設定項目は以下の通りです。
| 設定名 | 説明 |
|---|---|
| display_name | 画面上に表示されるカーネル名 |
| language | 実行する言語 |
| argv |
|
| env |
|
たとえば、Sparkのリソースパラメーターを変更する場合、envのPYSPARK_SUBMIT_ARGSの値を修正します。
"PYSPARK_SUBMIT_ARGS": "--master yarn --deploy-mode client --num-executors 1 --executor-memory 1g --executor-cores 1 --driver-memory 1g --conf spark.driver.maxResultSize=1g --conf spark.executor.memoryOverhead=384 --name PySpark_verysmall pyspark-shell"
実行環境やカーネルの削除¶
作成したカーネルを削除します。
以下の手順はgriddataユーザーで実行してください。
(1)カーネル一覧を確認し、カーネルを削除します。
$ jupyter kernelspec list
Available kernels:
カーネル名 パス
… …
… …
$ jupyter kernelspec uninstall カーネル名
(2)実行環境一覧を確認し、作成した実行環境を削除します。
$ conda env list
# conda environments:
#
環境名 パス
… …
… …
$ conda remove -n 実行環境名 --all
注意
デフォルトのPython環境(base)を削除しないでください。
5.1.9. Pythonライブラリーを追加する¶
デフォルトのPython環境にライブラリーをインストールするには、griddataユーザーで以下のコマンドを実行します。
$ conda install ライブラリー名
このとき、ライブラリーは以下の図のように、デフォルトの環境にのみインストールされ、他の実行環境からは利用できません。
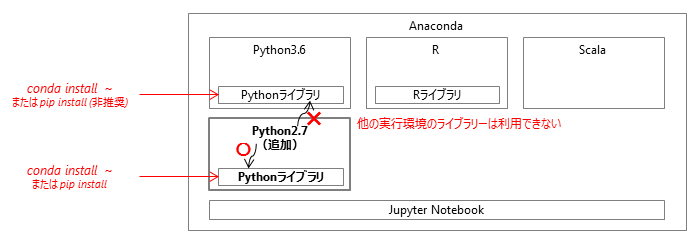
他の実行環境にライブラリーをインストールするには、griddataユーザーで以下のコマンドを実行します。
$ source activate 実行環境名
(実行環境名) $ conda install ライブラリー名
(実行環境名) $ source deactivate
注釈
ライブラリーをインストールする方法には、pipコマンドなどもあります。
$ pip install ライブラリー名
しかし、condaコマンドのパッケージとpipコマンドのパッケージには互換性がありません。 pipコマンドでライブラリーをインストールした場合、ライブラリー本体や依存ライブラリーがすでにcondaコマンドでインストールされていると、重複してインストールされることがあります。 このとき、正常に動作しなくなるなどの不具合が発生することがあります。デフォルトのPython実行環境には、なるべくcondaコマンドを使用してライブラリーを追加してください。
5.1.10. Pythonライブラリーを削除する¶
デフォルトのPython環境からライブラリーをアンインストールするには、griddataユーザーで以下のコマンドを実行します。
$ conda uninstall ライブラリー名
他の実行環境からライブラリーをアンインストールするには、griddataユーザーで以下のコマンドを実行します。
$ source activate 実行環境名
(実行環境名) $ conda uninstall ライブラリー名
(実行環境名) $ source deactivate
5.1.11. Rライブラリーを追加する¶
GridData Analyticsでは、R標準の追加方法によりRライブラリーを追加できます。追加したライブラリーはすべてのユーザーが利用できます。
以下の手順はgriddataユーザーで実行してください。
$ R
> install.packages("ライブラリー名", dependencies = TRUE)
5.2. GridData Analytics Scale Serverの運用手順¶
5.2.1. HDFSクラスターを起動する¶
本節では、HDFSの2回目以降の起動方法について説明します。
初回起動時は 初期設定 および 初回起動 を参照してください。
以下の手順はgriddataユーザーで実行してください。
(1)SERVER1、SERVER2、SERVER3で、ZooKeeperを起動します。
$ cd /home/griddata/griddata-core/zookeeper/logs
$ zkServer.sh start
(2)NameNode(Active)が起動するサーバー(SERVER1)で、HDFSを起動します。
$ start-dfs.sh
(3)NameNode(Active)が起動するサーバー(SERVER1)で、NameNodeの状態を確認します。
$ hdfs haadmin -getServiceState namenode1
active
$ hdfs haadmin -getServiceState namenode2
standby
以上でHDFSの起動は完了です。
5.2.2. HDFSクラスターを停止する¶
マスター・ノード(SERVER1またはSERVER2)から、griddataユーザーで以下のコマンドを実行します。
$ stop-dfs.sh
以上でHDFSの停止は完了です。
5.2.3. YARNクラスターを起動する¶
本項では、YARNの2回目以降の起動方法について説明します。
初回起動時は 初期設定 および 初回起動 を参照してください。
以下の手順はgriddataユーザーで実行してください。
(1)ResourceManager(Active)が起動するサーバー(SERVER2)で、YARNを起動します。
$ start-yarn.sh
(2)ResourceManager(Standby)が起動するサーバー(SERVER3)で、ResourceManagerを起動します。
$ yarn-daemon.sh start resourcemanager
(3)ResourceManager(Active)が起動するサーバー(SERVER2)で、ResourceManagerの状態を確認します。
$ yarn rmadmin -getServiceState rm1
active
$ yarn rmadmin -getServiceState rm2
standby
注釈
YARNの起動のタイミングによってはResourceManagerが以下の状態になることがあります。
$ yarn rmadmin -getServiceState rm1 standby $ yarn rmadmin -getServiceState rm2 active
SERVER2をActiveにする場合は、SERVER3で以下のようにResourceManagerの再起動を行ってください。
$ yarn-daemon.sh stop resourcemanager $ yarn-daemon.sh start resourcemanager
以上でYARNの起動は完了です。
5.2.4. YARNクラスターを停止する¶
以下の手順はgriddataユーザーで実行してください。
(1)マスター・ノード(SERVER2またはSERVER3)で、以下のコマンドを実行します。
$ stop-yarn.sh
(2)ResourceManager(Standby)が起動するサーバーでResourceManagerを停止します。
$ yarn-daemon.sh stop resourcemanager
以上でYARNの停止は完了です。
5.2.5. Hiveを起動する¶
本項では、Hiveの起動方法について説明します。
初回起動時は 初期設定 および 初回起動 を参照してください。
以下の手順はgriddataユーザーで実行してください。
(1)マスター・ノード(SERVER1とSERVER3)で、HiveMetastoreを起動します。
$ hive --service metastore &
以上でHiveの起動は完了です。
5.2.6. Hiveを停止する¶
以下の手順はgriddataユーザーで実行してください。
(1)マスター・ノード(SERVER1、SERVER3)で、HiveMetastoreを停止します。
$ kill -9 ${HiveMetastoreのPID}
以上でHiveの停止は完了です。
5.2.7. HistoryServerを起動する¶
本項では、SparkのHistoryServerの起動方法について説明します。
初回起動時は 初期設定 および 初回起動 を参照してください。
以下の手順はgriddataユーザーで実行してください。
マスター・ノード(SERVER1、SERVER2、SERVER3)で、HistoryServerを起動します。
$ /home/griddata/griddata-core/spark/sbin/start-history-server.sh
以上でHistoryServerの起動は完了です。
5.2.8. HistoryServerを停止する¶
以下の手順はgriddataユーザーで実行してください。
マスター・ノード(SERVER1、SERVER2、SERVER3)で、HistoryServerを停止します。
$ /home/griddata/griddata-core/spark/sbin/stop-history-server.sh
以上でHistoryServerの停止は完了です。
5.2.10. ZooKeeperを停止する¶
SERVER1、SERVER2、SERVER3からgriddataユーザーで、以下のコマンドを実行します。
$ zkServer.sh stop
以上でZooKeeperの停止は完了です。
注釈
ZooKeeperはHDFSのNameNodeやSparkのマスターを二重化し、 HA(High Availability)の構成を行う際の管理用ソフトフェアです。 そのため、HDFSやSparkが起動した状態ではZooKeeperを停止しないでください。
5.2.11. クラスターを縮退する¶
本項では、クラスターを縮退させ、スレーブ・ノードSERVER6を一時的に離脱させる場合を説明します。
以下の手順はgriddataユーザーで実行してください。
(1)マスター・ノード(SERVER1、SERVER2、SERVER3)で、エクスクルードファイル($HADOOP_HOME/conf/hosts.exclude)に縮退するスレーブ・ノード(SERVER6)のホスト名を追記します。
エクスクルードファイルがない場合、新たにファイルを作成してください。
SERVER6
(2)HDFSの設定ファイル($HADOOP_HOME/conf/hdfs-site.xml)を開き、HDFSのレプリケーション数のパラメーターの設定値(dfs.replication)を確認します。
もし、縮退したあとのDataNode数よりも大きな値になっている場合、縮退したあとのDataNode数以下の値に変更してください。
なお、dfs.replicationが記述されていない場合、デフォルト値の3になります。
(3)NameNode(Active)が起動しているサーバー(SERVER1またはSERVER2)で以下のコマンドを実行し、HDFSのクラスター構成情報を更新します。
$ hdfs dfsadmin -refreshNodes
以下のコマンドを実行し、縮退するスレーブ・ノード(SERVER6)のDecommission StatusがDecommisionedになっていることを確認します。
$ hdfs dfsadmin -report
(4)縮退するスレーブ・ノード(SERVER6)で、DataNodeを停止します。
$ hadoop-daemon.sh stop datanode
(5)ResourceManager(Active)が起動するサーバー(SERVER2またはSERVER3)で以下のコマンドを実行し、YARNのクラスター構成情報を更新します。
$ yarn rmadmin -refreshNodes
縮退するスレーブ・ノード(SERVER6)でNodeManagerが停止していることを確認します。
$ jps
以上でクラスターの縮退は完了です。
5.2.12. クラスターにノードを復帰させる¶
本項では、縮退中のスレーブ・ノードSERVER6をクラスターに復帰させる場合を説明します。
以下の手順はgriddataユーザーで実行してください。
(1)マスター・ノード(SERVER1、SERVER2、SERVER3)で、エクスクルードファイル($HADOOP_HOME/conf/hosts.exclude)から 縮退中のサーバーのホスト名(SERVER6)を削除します。
(2)NameNode(Active)が起動しているサーバー(SERVER1またはSERVER2)で以下のコマンドを実行し、HDFSのクラスター構成情報を更新します。
$ hdfs dfsadmin -refreshNodes
(3)縮退中のサーバー(SERVER6)で、DataNodeを起動します。
$ hadoop-daemon.sh start datanode
(4)ResourceManager(Active)が起動しているサーバー(SERVER2またはSERVER3)で以下のコマンドを実行し、YARNのクラスター構成情報を更新します。
$ yarn rmsadmin -refreshNodes
(5)縮退中のサーバー(SERVER6)で、NodeManagerを起動します。
$ yarn-daemon.sh start nodemanager
以上でノードの復帰は完了です。
5.2.13. クラスターにノードを増設する¶
本項では、ホスト名SERVER7、IPアドレス10.0.0.8のサーバーをスレーブ・ノードとして増設する場合を説明します。
(1)すべてのサーバーで、増設するスレーブ・ノード(SERVER7)のホスト名とIPアドレスを/etc/hostsファイルに登録します。
# echo '10.0.0.8 SERVER7' >> /etc/hosts
以下の手順はgriddataユーザーで実行してください。
(2)は増設するスレーブ・ノード(SERVER7)で実施してください。
(2)SSHの設定
(2-1)ssh-keygenコマンドにより鍵を生成します。このとき、passphraseには何も入力せずにEnterを押します。
$ ssh-keygen -t dsa
Generating public/private dsa key pair.
Enter file in which to save the key (/home/griddata/.ssh/id_dsa):
Created directory '/home/griddata/.ssh'.
Enter passphrase (empty for no passphrase):
Enter same passphrase again:
Your identification has been saved in /home/griddata/.ssh/id_dsa.
Your public key has been saved in /home/griddata/.ssh/id_dsa.pub.
The key fingerprint is:
xx:xx:xx:xx:xx:xx:xx:xx:xx:xx:xx:xx:xx:xx:xx:xx griddata@SERVER4
(2-2)鍵が生成されたことを確認します。
$ ls -l ~/.ssh
-rw-------. 1 griddata griddata 668 m月 dd hh:mm yyyy id_dsa
-rw-r--r--. 1 griddata griddata 605 m月 dd hh:mm yyyy id_dsa.pub
(2-3)生成された鍵のうち、公開鍵ファイル「~/.ssh/id_dsa.pub」の内容を「~/.ssh/authorized_keys」ファイルに追加します。
$ cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys
$ chmod 600 ~/.ssh/authorized_keys
(2-4)SSHで自分自身にパスフレーズなしでログインできることを確認します。
$ ssh $(hostname)
Last login: ddd mm dd hh:mm:ss yyyy from SERVER4
$ exit
logout
Connection to SERVER4 closed.
(3)マスター・ノード(SERVER1、SERVER2、SERVER3)から、公開鍵ファイル「~/.ssh/id_dsa.pub」を増設するスレーブ・ノード(SERVER7)に配付します。
SERVER1では以下のコマンドを実行します。
$ cd ~
$ scp ~/.ssh/id_dsa.pub griddata@SERVER7:SERVER1_id_dsa.pub
SERVER2では以下のコマンドを実行します。
$ cd ~
$ scp ~/.ssh/id_dsa.pub griddata@SERVER7:SERVER2_id_dsa.pub
SERVER3では以下のコマンドを実行します。
$ cd ~
$ scp ~/.ssh/id_dsa.pub griddata@SERVER7:SERVER3_id_dsa.pub
(4)マスター・ノードの公開鍵ファイル「SERVER1_id_dsa.pub」および「SERVER2_id_dsa.pub」、「SERVER3_id_dsa.pub」の内容を、 増設するスレーブ・ノード(SERVER7)の「~/.ssh/authorized_keys」ファイルに追加します。
$ cd ~
$ cat SERVER1_id_dsa.pub >> ~/.ssh/authorized_keys
$ rm SERVER1_id_dsa.pub
$ cat SERVER2_id_dsa.pub >> ~/.ssh/authorized_keys
$ rm SERVER2_id_dsa.pub
$ cat SERVER3_id_dsa.pub >> ~/.ssh/authorized_keys
$ rm SERVER3_id_dsa.pub
(5)マスター・ノード(SERVER1、SERVER2、SERVER3)から、増設するスレーブ・ノード(SERVER7)にパスフレーズなしでログインできることを確認します。
SERVER1では以下のコマンドを実行します。
$ ssh SERVER7
Last login: ddd mm dd hh:mm:ss yyyy from SERVER1
$ exit
logout
SERVER2では以下のコマンドを実行します。
$ ssh SERVER7
Last login: ddd mm dd hh:mm:ss yyyy from SERVER2
$ exit
logout
SERVER3では以下のコマンドを実行します。
$ ssh SERVER7
Last login: ddd mm dd hh:mm:ss yyyy from SERVER3
$ exit
logout
(6)すべてのサーバーのHadoopのインクルードファイル(hosts.include)に増設するスレーブ・ノード(SERVER7)のホスト名を追記します。
$ echo 'SERVER7' >> $HADOOP_HOME/conf/hosts.include
(7)すべてのサーバーのHadoopとSparkのスレーブ・ノード設定ファイル(slaves)に増設するスレーブ・ノード(SERVER7)のホスト名を登録します。
$ echo 'SERVER7' >> $HADOOP_HOME/conf/slaves
$ echo 'SERVER7' >> $SPARK_HOME/conf/slaves
(8)増設するスレーブ・ノード(SERVER7)で、DataNodeを起動します。
$ hadoop-daemon.sh start datanode
(9)NameNode(Active)が起動するサーバー(SERVER1またはSERVER2)で以下のコマンドを実行し、HDFSのクラスター構成情報を更新します。
$ hdfs dfsadmin -refreshNodes
(10)ResourceManager(Active)が起動するサーバー(SERVER2またはSERVER3)で以下のコマンドを実行し、YARNのクラスター構成情報を更新します。
$ yarn rmadmin -refreshNodes
(11)増設するスレーブ・ノード(SERVER7)で、NodeManagerを起動します。
$ yarn-daemon.sh start nodemanager
以上でノードの増設は完了です。
5.2.14. クラスターからノードを除外する¶
本項では、スレーブ・ノードSERVER7を除外する場合を説明します。
あらかじめ クラスターを縮退する に従ってSERVER7を縮退してください。
(1)インクルードファイル($HADOOP_HOME/conf/hosts.include)とエクスクルードファイル($HADOOP_HOME/conf/hosts.exclude)から、 除外するスレーブ・ノード(SERVER7)のホスト名を削除します。
(2)HadoopとSparkのスレーブ・ノード設定ファイル($HADOOP_HOME/conf/slaves、$Spark_HOME/conf/slaves)から、 除外するスレーブ・ノード(SERVER7)のホスト名を削除します。
(3)NameNode(Active)が起動するサーバー(SERVER1またはSERVER2)で以下のコマンドを実行し、HDFSのクラスター構成情報を更新します。
$ hdfs dfsadmin -refreshNodes
(4)ResourceManager(Active)が起動するサーバー(SERVER2またはSERVER3)で以下のコマンドを実行し、YARNのクラスター構成情報を更新します。
$ yarn rmadmin -refreshNodes
以上でノードの除外は完了です。