2. GridData Analytics Studioの利用方法¶
2.1. ノートブック管理機能¶
2.1.1. ログイン画面¶
GridData Analytics Studioを起動後、http://<GridData Analytics StudioのIPアドレス>:8000/にアクセスします
以下に示すログイン画面にて、あらかじめ作成したユーザ名とパスワードでログインしてください。

起動方法、およびユーザの作成方法については管理者ガイドを参照してください。
2.1.2. ダッシュボード画面¶
ログイン後、以下のようにJupyterのダッシュボード画面が表示されます。 この画面では、ノートブックやJupyterに関する管理や設定を行うことができます。
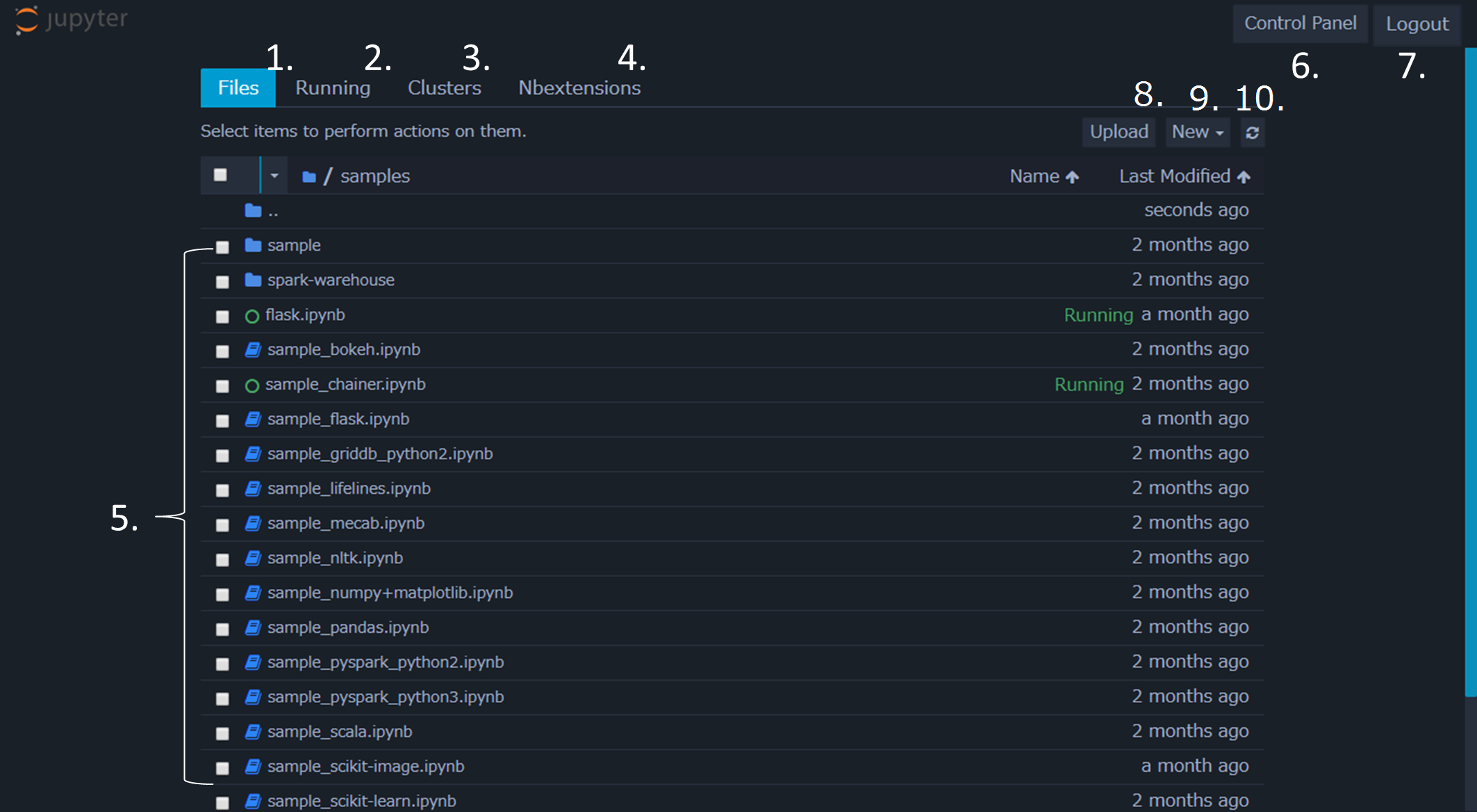
画面の各構成は以下の通りです。
- Files
- ファイル一覧を表示します。
- Running
- 起動中のノートブックを管理します。
- Clusters
- Jupyterのクラスタ実行機能です。GridData Analytics Studioでは使用しません。
- Nbextensions
- Jupyterの拡張機能の管理を行います。
- File Tree
- ファイルの一覧を表示します。起動中のノートブックは緑色のアイコンで表示されます。
- Control Panel
- Jupyterの停止を行います。
- Logout
- ログアウトします。
- Upload
- ローカルのファイルをFile Treeにアップロードします。
- New
- ノートブックのほか、空のファイルやフォルダ、ターミナル画面などを新規作成します。
- Refresh notebook list
- File Treeを更新します。
2.1.3. ノートブックの編集画面¶
ダッシュボード画面からNewボタンを選択し、新しいノートブックを作成します。 このときノートブックごとに、カーネルと呼ばれる各プログラミング言語の実行環境を選択します。
注釈
本マニュアルでは、Python3カーネルによるノートブックを作成した場合に基づき説明を行います。
Python3カーネルを選択しノートブックを作成すると、以下のようにノートブックの編集画面が開きます。
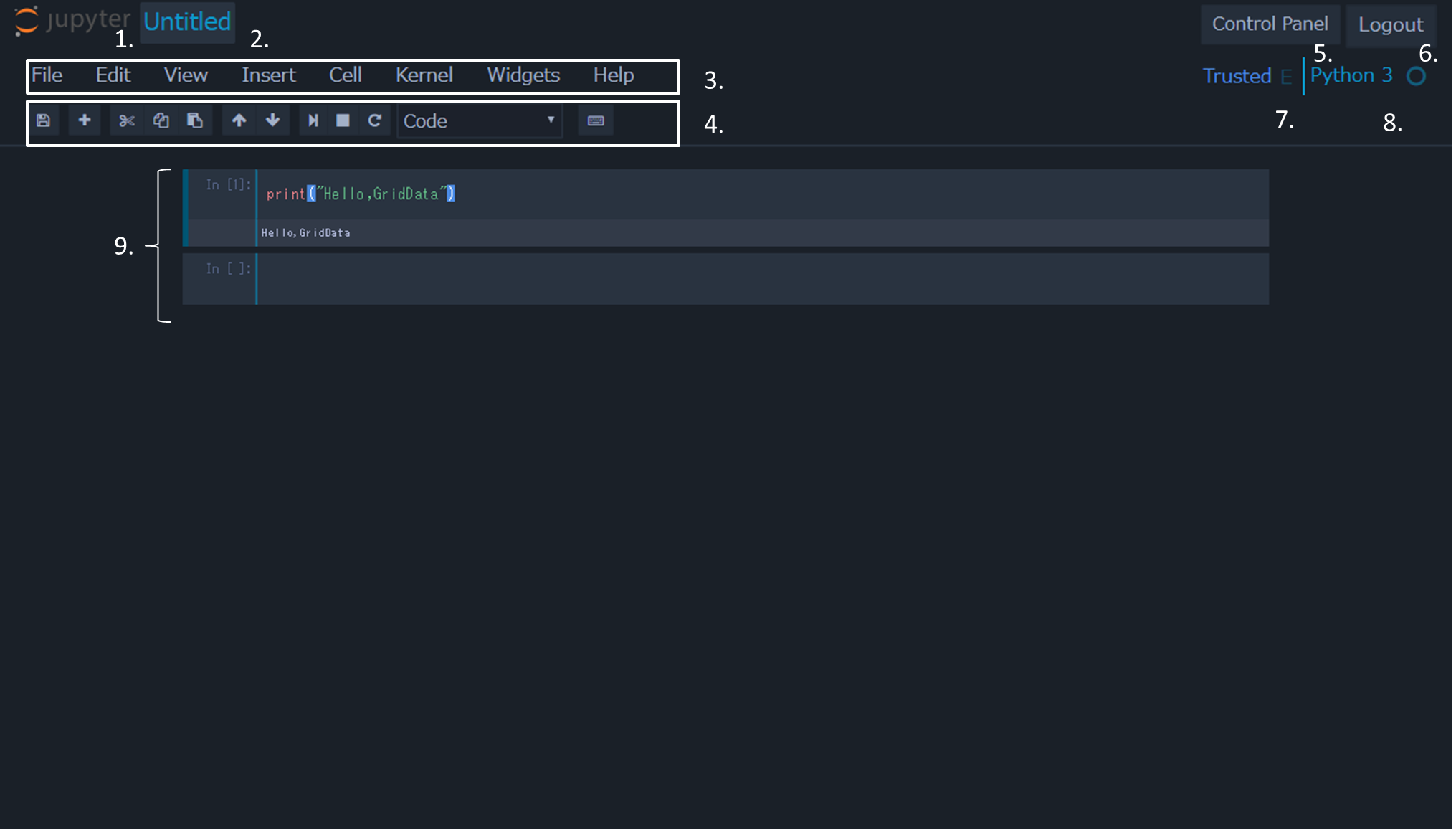
編集画面では、ノートブックにスクリプトを記述し実行します。このとき、ノートブックをセルと呼ばれる単位に分割し、セルごとに実行ができます。 このとき宣言した変数や関数はセル間で共有されます。 また編集画面では、カーネルやセルの管理なども行います。 画面の各構成は以下の通りです。
- ロゴ
- クリックすることでダッシュボード画面に移動します。
- ノートブック名
- クリックすることで名前を変更します。
- メニューバー
- 後述するノートブックの操作を行います。
- ツールバー
- 後述するノートブックの操作を行います。
- Control Panel
- Jupyterの停止を行います。
- Logout
- ログアウトを行います。
- cell mode indicator
- 編集モードの際はE、コマンド操作モードの際はCと表示されます。また、信頼できるノートブックの場合はTrustedと表示されます。
- kernel indicator
- カーネル名やカーネルの状態が表示されます。
- ノートブック画面
- 各セルが表示されます。マウスまたは矢印キーでセルを選択します。また現在選択中のセルは左側にバーが表示されます。
メニューバー¶
メニューバーの各項目について説明します。
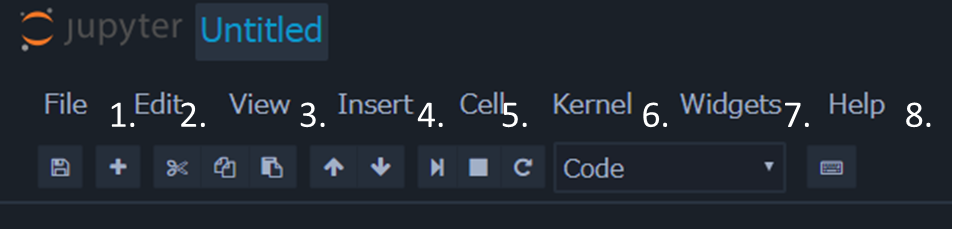
各項目の内容は以下の通りです。
- File
- ノートブックの作成やコピー、リネーム、エクスポートなどを行います
- Edit
- セルのカットやコピーなどの編集を行います
- View
- ツールバーの表示の切り替えなど、見た目の変更を行います
- Insert
- セルの挿入を行います
- Cell
- セルの実行、セルの実行形式の変更、出力結果の設定などを行います
- Kernel
- カーネルの設定と変更を行います
- Widget
- セルにウィジェット機能を追加します
- Help
- 各種ヘルプへのリファレンスです
ツールバー¶
ツールバーの各項目について説明します。

各項目の内容は以下の通りです。
- save and checkout
- ノートブックの保存を行います。
- insert cell below
- 現在選択しているセルの下に、新しくセルを挿入します
- cut selected cells
- 選択中のセルを削除します
- copy selected cells
- 選択中のセルをコピーします
- paste cells below
- コピーしたセルを貼り付けます
- move selected cells up
- 選択中のセルの位置を上のセルと入れ替えます
- move selected cells down
- 選択中のセルの位置を下のセルと入れ替えます
- run cell, select below
- 選択中のセルを実行し下のセルに移動します
- interrupt kernel
- カーネルを停止します
- restart the kernel
- カーネルを再起動します
- プルダウン
- セルの実行形式を選択します。 コードを記述する場合はCodeを、マークダウンを記述する場合はMarkdownを選択します。 なお、マークダウンの仕様については jupyterのページ を 参照してください。
- open the command palette
- 各実行とそのショートカットを参照します
2.1.4. ターミナル画面¶
ダッシュボード画面からNewボタンを選択した際、表示されるメニューからNotebookではなくTerminalを選択することで、 以下のようにターミナル画面が開きます。
ターミナル画面では、通常のターミナルと同様に画面上でコマンドを実行することができます。 このとき、ターミナルの実行ユーザはjupyterのログインユーザ、ホームディレクトリはログインユーザのホームディレクトリです。
通常のダッシュボード画面に戻るには、左上のjupyterのロゴをクリックします。 また、右上のLogoutをクリックした場合はjupyterからログアウトします。
2.1.5. テキストエディタ画面¶
ダッシュボード画面からNewボタンを選択した際、表示されるメニューからNotebookではなくText Fileを選択することで、 以下のようにテキストエディタ画面が開きます。
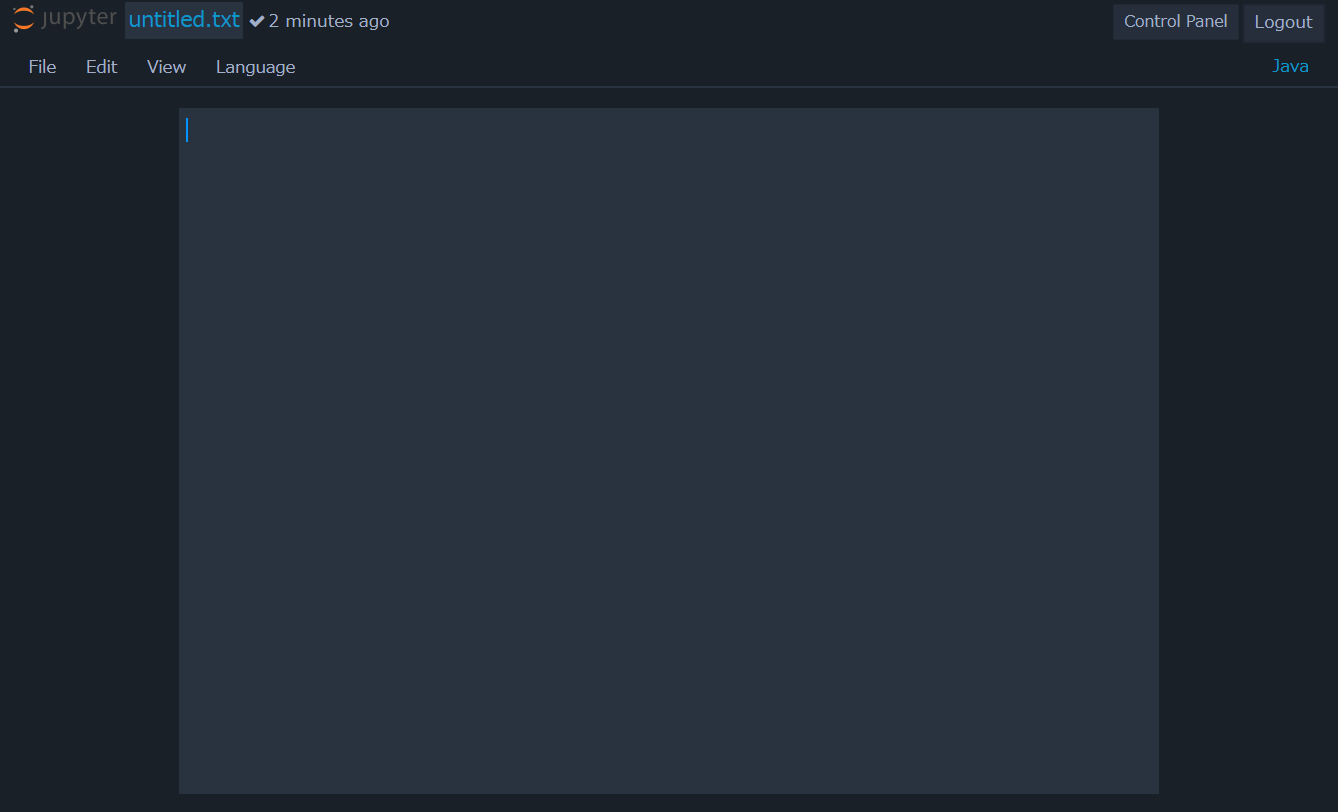
このとき、テキストエディタ画面のメニューバーの各項目について説明します。

File
テキストファイルの新規作成、保存、リネーム、ダウンロードを行います
Edit
文字の検索と置換、キーバインドの設定を行います。キーバインドはSublime Text、Vim、emacsから選択可能です。
View
ヘッダや行番号の表示を切り替えます
Language
各種プログラミング言語のコマンドやキーワードのハイライトを行います。
2.2. ライブラリ¶
2.2.1. 分析ライブラリ¶
本項では、GridData Analytics Studioで利用可能な主なPythonライブラリについて、 用途とサンプル用ノートブックの紹介を行います。 なお、各ライブラリは、Python3カーネルによる実行を前提としています。
bokeh¶
bokehはデータ可視化ライブラリです。 データを様々な形式の図に出力するほか、 マウスによる移動や縮小といった、インタラクティブな効果を図に持たせることができます。
bokehのサンプル用ノートブックsample_bokehでは、 ローレンツ方程式と呼ばれる数式を可視化する例を紹介しています。 ノートブックを実行することで、ローレンツ方程式を描写した図がマウスによる操作が可能な状態で出力されます。
chainer¶
chainerはニューラルネットワーク用のライブラリです。他のニューラルネットワーク用のライブラリに比べ、 直感的にネットワーク構造を記述できる特徴があります。
chainerのサンプル用ノートブックsample_chainerでは、 mnistと呼ばれる数字を表す画像のデータセットを元に、数値を分類する学習モデルを 作成する例を紹介しています。 ノートブックを実行すると、各エポック(学習のイテレーション)ごとに進捗のプログレスバーが表示され、 また、学習結果のモデルがノートブックがあるディレクトリ以下に作成されます。
注釈
本サンプルコードはCPUのみにより実行を行うサンプルコードとなっており、実行が完了するまでに時間がかかります。
Flask¶
FlaskはPython用のWebアプリケーションフレームワークです。小規模なWebアプリケーションの開発に適しており、 数行の記述でアプリケーションサーバを作成し起動することができます。
Flaskのサンプル用ノートブックsample_flaskでは、 Flaskを使用したWebAPIの作成方法について主要な例を紹介しています。 sample_flaskを実行することで実際にAPIサーバが起動し、 ノートブック内に記載されたアドレスにアクセスできるようになります。
lifelines¶
lifelinesは生存分析と呼ばれる、 あるイベントが起きるまでの時間をモデル化する分析手法で使用するライブラリです。
lifelinesのサンプル用ノートブックsample_lifelinesでは、 肺がん患者のサンプルデータを元に、カプラン・マイヤー法と呼ばれる手法で 時間経過によるがんの生存率を推定し、matplotlibを使用しグラフに描画する例を紹介しています。
matplotlib¶
matplotlibはグラフ描画用のライブラリです。通常のグラフの描画のほか、散布図や箱ひげ図、 3Dグラフなど様々な図やグラフを描画することができます。
numpyとmatplotlibのサンプル用ノートブック sample_numpy+matplotlibでは、 正弦波のグラフを表示する例と、乱数により生成したデータをヒストグラムで表示する例を紹介しています。
mecab¶
mecabは日本語の文章を、形態素と呼ばれる単位で解析するエンジンです。 形態素ごとに文章を分割するほか、形態素に応じて品詞名、動詞の原型、読みなどを出力することができます。
mecabのサンプル用ノートブックsample_mecabでは、 「すもももももももものうち」という文章に対し形態素解析を行った例を紹介しています。 このとき、解析結果はchasenというmecabとは異なる解析エンジンの出力形式で出力しています。 ノートブックにある文章を変えてノートブックを実行することで、 日本語の任意の文章で形態素解析を行うことができます。
nltk¶
nltkは自然言語処理用のツールキットです。 単語の正規化、構文解析、意味解析などを実施することができます。 主に英文処理用のツールキットですが、mecabと組み合わせることで日本語の言語処理も可能です。
nltkのサンプル用ノートブックsample_nltkでは、 青空文庫のテキストを読み込み、文字種を元に分かち書きを行う例を紹介しています。
numpy¶
numpyはPythonにおける数値計算用のライブラリです。 多彩な計算処理用の関数が利用できるほか、 配列計算などの繰り返し処理をネイティブなPythonコードよりも高速に実行することができます。
numpyとmatplotlibのサンプル用ノートブック sample_numpy+matplotlibでは、 matplotlibでグラフを表示する際、正弦波や乱数を生成するにあたりnumpyを使用しています。
pandas¶
pandasはデータ分析のライブラリです。DataFrameと呼ばれる形式で データを作成・格納し、DataFrameの変換やDataFrame同士の結合・抽出を行うことで、 大量のデータに対しSQLのように容易に操作や分析を行うことができます。
pandasのサンプル用ノートブックsample_pandasでは、 サンプル用に小規模のDataFrameを新規作成し、データの抽出や表示を行っています。
scikit-image¶
scikit-imageは画像処理用のライブラリです。画像の変換のほか、特徴量や輪郭の抽出など、 画像にまつわる複数の機能が利用できます。
scikit-imageのサンプル用ノートブックsample_scikit-imageでは、 ハフ変換という手法により、サンプル画像から円形の図形を抽出する例を紹介しています。 ノートブックを実行することで、サンプル画像であるコーヒーカップの画像から カップの輪郭が楕円として抽出され、表示されます。
scikit-learn¶
scikit-learnはPythonの機械学習ライブラリです。回帰、分類、クラスタリングなど、 主要な機械学習のアルゴリズムを利用することができます。
scikit-learnのサンプル用ノートブックsample_scikit-learnでは、 データの読み込みテストを行ったのち、機械学習の例としてk-meansによる簡単なクラスタリングを行っています。
scipy¶
scipyはnumpyをベースとした、数学や工学などで使用する数値解析ライブラリです。 微積、信号処理、統計処理といった、各種科学計算を行うことができます。
scipyのサンプル用ノートブックsample_scipyでは、 ベッセル関数と呼ばれる関数を作成し、ある区間内におけるその関数の最大値を求める例を紹介しています。 ノートブックを実行すると、ベッセル関数のグラフとその最大値がmatplotlibを使用し表示されます。
2.2.2. WebAPI作成ライブラリ¶
ここでは、PythonのプラグインであるFlaskを使用し、PythonコードをAPIサーバ化する方法について紹介します。
まず、APIサーバの雛形を以下に示します。
from flask import Flask
api = Flask(__name__)
@api.route("/")
def hello():
return "Hello World!"
if __name__ == '__main__':
# ホスト名とポートを指定して起動開始
api.run(host='localhost', port=3001)
このとき、ホスト名はGridData Analytics StudioをインストールしたマシンのIPアドレスまたはホスト名に変更してください。 上記のPythonコードをJupyter上で実行することでhttp://localhost:3001/が起動し、アクセスすることで Pythonの任意のメソッド(ここではhello)の返り値(ここではHello World!)が表示されます。
ここで、Flaskの代表的な使用方法を紹介します。
■ JSONを返す
追加でjsonifyおよびmake_responseをインポートします。使用例は以下の通りです。
from flask import Flask, jsonify, make_response
import json
@api.route("/")
def hello():
result = {"result":True, "data":{"string":"hello,world!"}}
return make_response(jsonify(result))
if __name__ == '__main__':
api.run(host='localhost', port=3001)
上記のサーバにアクセスすることで、以下のようなJsonが返却されます。
{"result":True,"data":{"string":"hello,world!"}}
■ URLを指定する
@api.route()の記述を変更します。使用例は以下の通りです。
(中略)
@api.route("/my-api")
def hello():
……
上記の例の場合、アクセス先のURLがhttp://localhost:3001/my-apiに変更されます。URLは複数指定が可能です。
(中略)
@api.route("/my-api")
@api.route("/my-api/api2")
def hello():
……
■ HTTPメソッドを指定する
@api.route()の記述を変更します。使用例は以下の通りです。
(中略)
@api.route("/my-api", methods=['GET','PUT','POST']))
def hello():
……
上記の例の場合、アクセス先のURLはGET、PUT、POSTが使用可能になります。デフォルトではGETが使用可能です。
■ クエリを取得する
追加でrequestをインポートします。使用例は以下の通りです。
from flask import Flask, jsonify, make_response,request
import json
@api.route("/my-api")
def hello():
message = request.args.get('query')
message = "hello,world" if message is None else echo_message(message)
result = {"result":True,"data":{"string":message}}
return make_response(jsonify(result))
def echo_message(message):
return "message is "+str(message)
if __name__ == '__main__':
api.run(host='localhost', port=3001)
上記の例のように、request.args.get()を使用することでクエリ文字列とその値を取得することができます。 上記の例の場合、http://localhost:3001/my-api?query=hello にアクセスすることで以下のようなJsonが返却されます。
{"result":True,"data":{"string":"message is hello"}}
■ URLの一部を取得する
ユーザ名やIDなど、URLの一部が可変の場合、その部分文字列を取得できます。使用例は以下の通りです。
(中略)
@api.route('/my-api/<string:username>/')
def hello(username='defaultname'):
result = {"result":True,"data":{ "string":username } }
return make_response(jsonify(result))
……
上記のように、URLの一部に変数名を指定し、その変数をメソッドの引数とすることで、 そのURLにアクセスした場合にメソッドが変数を取得することができます。 上記の例では、http://localhost:3001/my-api/USER1/というURLにアクセスすることで、以下のようなJsonが返却されます
{"result":True,"data":{"string":"USER1"}}
■ htmlを返す
Jsonデータではなくhtmlを返却する場合、新たにrender_templateをインポートします。使用例を以下に示します。 あらかじめノートブックの実行場所にtemplatesまたはstaticというディレクトリを作成し、内部にhtmlファイル(ここではhello.html)を配置してください。
from flask import Flask, jsonify, make_response,request,render_template
import json
@api.route("/my-api")
def hello():
return render_template('hello.html', title='flask')
if __name__ == '__main__':
api.run(host='localhost', port=3001)
render_templateはtemplatesディレクトリとstaticディレクトリを自動的に読み込み、指定したファイルがある場合はそれを返却します。 上記の例では、http://localhost:3001/my-api/にアクセスすることでhello.htmlが表示されます。 なおこのとき、Pythonのテンプレートエンジンjinja2を使用し、動的にhtmlを作成することができます。
■ htmlの変更結果を反映する
render_templateで使用するhtmlに対し、変更した結果を即座に反映する場合、以下のようにTEMPLATES_AUTO_RELOADの設定を行います。
(中略)
if __name__ == '__main__':
app.jinja_env.auto_reload = True
app.config['TEMPLATES_AUTO_RELOAD'] = True
app.run(host='localhost', port=3001)
■ エラーの返却
@api.errorhandlerアノテーションを使用することで、エラーコードごとの処理を実行することができます。 使用例を以下に示します。
(中略)
@api.errorhandler(404)
def page_not_found(error):
return "404 not found"
……
上記の例では、存在しないURLを指定することで404 not foundが返却されます。
その他の使用例については、 Flaskの公式ページ を参照してください。
2.2.3. 外部データソース接続ライブラリ¶
GridData Analytics Studioでは、以下のDBを外部データソースとして利用可能です。
- PostgreSQL
- MySQL
- OracleDB
- GridDB
利用可能な言語はPython3、Python2(GridDBのみ)、およびR(PostgreSQL,MySQLのみ)です。 なお、HDFSおよびSparkの利用法については、 HDFSを操作する や Sparkクラスタ上で処理を実行する を参照してください。
Python用PostgreSQL接続ライブラリ¶
psycopg2を使用したPostgreSQLの接続例を以下に示します。
import psycopg2
# 接続情報の設定
connection = psycopg2.connect(
host='localhost',
user='postgres',
password='postgres'
port='5432'
dbname= 'testdb'
)
stmt=connection.cursor()
# SQLの発行
stmt.execute("select * from testtable;")
# 結果の取得
rows = stmt.fetchall()
for row in rows:
print(row)
stmt.close();
connection.close();
Python用MySQL接続ライブラリ¶
pymysqlを使用したMySQLの接続例を以下に示します。
import pymysql
# 接続情報の設定
connection = pymysql.connect(
host='localhost',
user='user',
password='password',
db='testdb',
cursorclass=pymysql.cursors.DictCursor
)
stmt = connection.cursor()
# SQLの発行
stmt.execute("select * from testtable;")
# 結果の取得
rows = stmt.fetchall()
for row in rows:
print(row)
stmt.close();
connection.close();
Python用OracleDB接続ライブラリ¶
cx_Oracleを使用したOracleDBの接続例を以下に示します。
import cx_Oracle
# 接続情報の設定
connection = cx_Oracle.connect("username","password",
"localhost/dbname")
# SQLの発行
cur = connection.cursor()
cur.execute("select * from testtable")
# 結果の取得
rows = cur.fetchall()
for row in rows:
print(row)
stmt.close();
connection.close();
Python用GridDB接続ライブラリ¶
GridData Analytics Studioでは、Jupyterを使用しPythonからGridDBを利用することができます。 利用可能な言語はPython2およびPython3です。
Python3カーネルにおけるGridDBの使用例を以下に示します。
# ライブラリのパスを指定
import sys
sys.path.append('/home/griddata/analytics/griddb/PythonModule3')
# ライブラリのインポート
import griddb_python_client as griddb
factory = griddb.StoreFactory.get_default()
# 接続情報の設定
gridstore = factory.get_store({
"notificationMember":"localhost:10001",
"sqlNotificationMember":"localhost:20001",
"clusterName": "testCluster",
"user": "admin",
"password": "admin"
})
# コンテナの取得
container = gridstore.get_container("testContainer")
# コンテナへのSQLの発行
query=container.query("select * where name = 'name01'")
rs = query.fetch(True)
# 取得したデータの表示
while rs.has_next():
rs.get_next(row)
name = row.get_field_as_string(0)
print( "name = %s" % name)
注釈
Python2でGridDBを利用する場合、ライブラリのパスをPythonModule2に変更してください。
R用PostgreSQL接続ライブラリ¶
RPostgreSQLを使用したPostgreSQLの接続例を以下に示します。
library(DBI)
library(RPostgreSQL)
dbconnector <- dbConnect(PostgreSQL(), host="localhost", port=5432, dbname="testdb", user="postgres", password="postgres")
dataset <- dbGetQuery(dbconnector,"select * from testtable")
print(dataset)
R用MySQL接続ライブラリ¶
RMySQLを使用したMySQLの接続例を以下に示します。
library(DBI)
library(RMySQL)
md <- dbDriver("MySQL")
dbconnector <- dbConnect(md, host="localhost", dbname="testdb", user="user", password="pass")
dataset <- dbGetQuery(dbconnector,"select * from testtable")
print(dataset)