GridDB programming tutorial
Revision: 2147
Table of Contents
1 Example
This chapter describes an example showing how to simplify the monitoring system for a PV site performing photovoltaic power generation.
1.1 Monitoring a PV Site
A PV site is a plant equipped with (normally thousands to hundreds of thousands of) solar panels, which collects power generated by each panel and transmits it to the power grid. For the convenience of control, panels are grouped into strings or arrays, each consisting of multiple panels. Electric power generated by the panels is collected via facilities, such as a concentrator (CC), a power conditioning subsystem (PCS) and a gateway (GW), and transmitted to the power grid. Each facility is equipped with various sensors to monitor the condition of power generation.
The PV site monitoring system is a system for monitoring the condition of power generation and detecting abnormalities on a PV site. The schematic view below shows a system configuration.
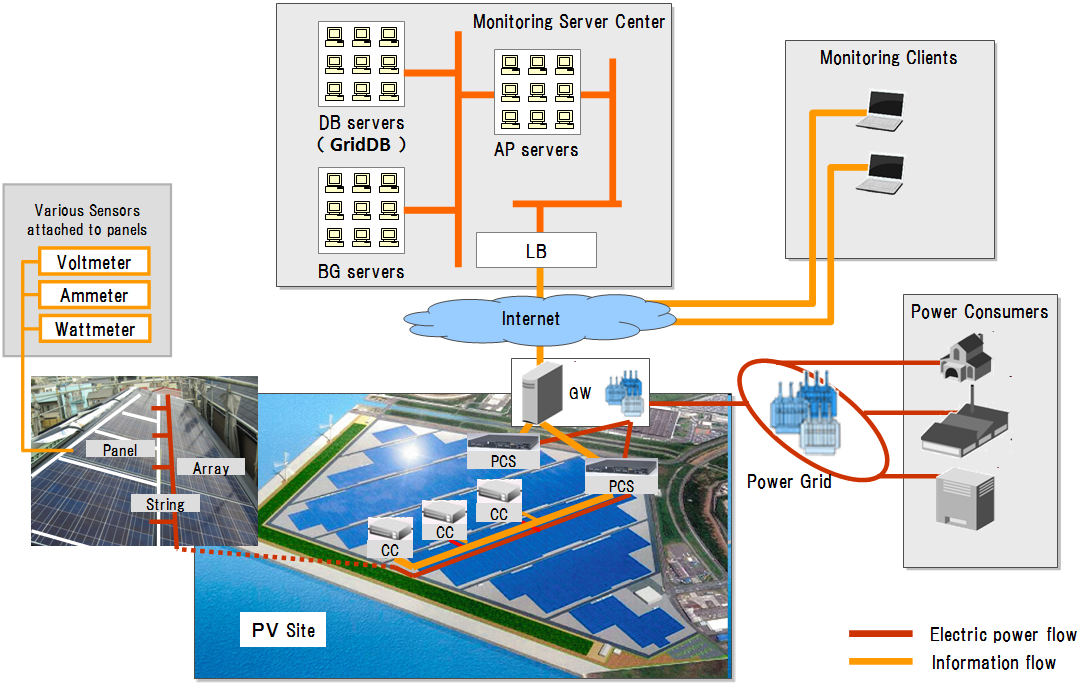
Example of PV site monitoring system
- Electric power generated at the PV site is transmitted from GW to power consumers through the power grid.The PV site measures the conditions of facilities during generating power using various sensors.
- The information on the conditions of facilities measured at the PV site is transmitted from GW to the monitoring server center through the Internet.The monitoring server center accumulates the received various information on the conditions of facilities in a database.At the same time, the PV site determines whether each sensor value is normal or abnormal. If it is determined as abnormal, an alert is sent to the monitoring server center.The configuration and specifications of the PV site's facilities are stored in a database beforehand.In this example, each panel is equipped with a voltmeter, an ammeter, and a wattmeter for measuring the condition of itself.
- A monitoring client monitors the PV site for abnormalities, referencing alert information stored in a database in the monitoring server center.
1.2 Capabilities Described in the Example
This example shows simplified PV site monitoring capabilities using GridDB as a database, as follows:
- To read in the information on facility conditions and alerts collectively from a CSV file and store the information in a database beforehand by a simplified storing function.
- To search for an alert showing serious abnormality among an alert history within the previous 24 hours and display the information of a facility causing an abnormality and the sensor values around the occurrence of abnormality by a simplified abnormality detection function.
The following data resources are used in the example.
-
Facility information
- Describes the information defined for each facility, consisting of an ID and a name assigned for each facility and its specifications.
-
Sensor information
- Describes the correspondence relation between a facility and a sensor, consisting of a name and a type for each sensor and an ID of a facility to be measured.
-
Sensor history information
- Describes a value measured at a certain time, consisting of a date and time of measurement, a measured value, and status information.
-
Alert history information
- Describes detected alerts, consisting of an alert ID, a date and time of alert, an ID of a sensor detecting an alert, an alert level, and alert detail information.
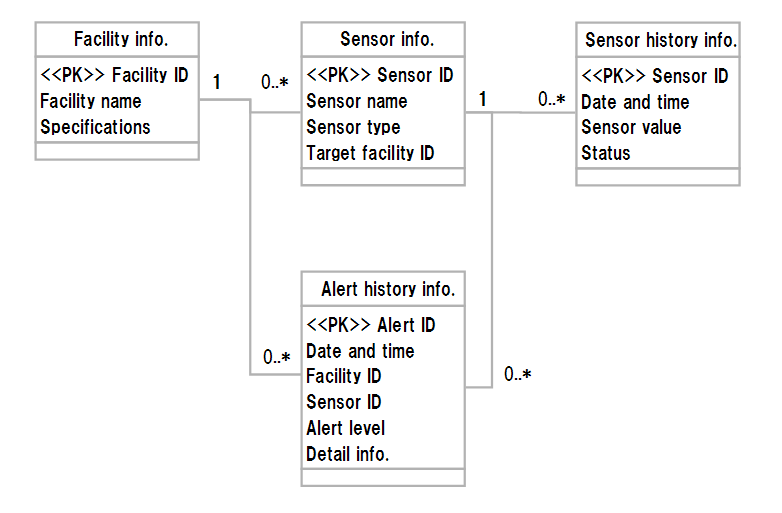
Logical Schema
2 Characteristics of GridDB
GridDB has the following six characteristics you should consider in using GridDB.
- Concept of Container
- Restrictions on transactions
- Restrictions on queries
- Importance of key coding
- Indexing of Collection or TimeSeries
- Proper granularity of Collection and Row
The following sections describe these characteristics.
2.1 Concept of Container
GridDB creates a data storage collectively called Container (corresponding to a table of RDB) for data management. Basically, a Container stores KV data, including not only simple KV-formatted data, but also original schema definitions. There are two types of Containers:
- Collection for general KV data management
- TimeSeries for time-series data management
A schema of a Container (Collection/TimeSeries) is defined as shown below.
- Define a schema as a class in a client program.
- Be sure to specify either one of member variables in a class as a line key.A line key is used as a key of KVS, which must be unique in a single Container.Add "@RowKey" to specify a line key in class definitions.
- A value of KVS can be multiple member variables, and has no restriction on its type.Accordingly, it can be defined like a normal structure.
TimeSeries has the following restriction and characteristic because of the purpose of time-series data management.
- Only a date and time can be specified as a line key.
- Time-series data can be compressed and interpolated.
2.2 Restrictions on Transactions
GridDB manages transactions for each Container. Therefore, no problem occurs in transactions referencing a single Container; however, there are restrictions on transactions referencing more than one Container, as follows:
- Inconsistent data during update can be referenced by another transaction; therefore, consistency is not strictly guaranteed.
- Transactions are committed individually, and so rollback cannot be done easily; therefore, atomicity is also not guaranteed.
You need to use GridDB for a limited purpose and take necessary actions even if inconsistency is acceptable.
- Do not use GridDB for a critical purpose, such as for an accounting system.
- Implement error checking, such as checking for existence of data, and retrying a check if an error occurs, in order to guarantee consistency.
2.3 Restrictions on Queries
GridDB provides simple KV-type search with a given key. You can use a dedicated query language TQL for search with more complicated conditions. TQL is a subset of SQL, a query language of RDB, which has the following limitations.
- Supports only SELECT statements which select data for search or update, limited to the syntax shown below.
- Does not accept other than SELECT statements, such as manipulation or update of selected data.
- Fetching of all Columns (*) and aggregate operations (e.g., SUM) are available for a select expression. (Fetching of a particular Column is not available.)
- Segments not covered by the syntax below, such as ORDER BY, are not available.
SELECT (select expression) [FROM (Collection name or TimeSeries name)] [WHERE (conditional expression)]
However, GridDB provides original advanced search functions to search for time-series data and spatial data for social infrastructure use.
See "GridDB User's Manual" for more information on TQL.
2.4 Indexing of Collection or TimeSeries
GridDB can create indexes for each Column of a Row, so as to provide fast search when specifying not only a key condition for KV, but also a condition about values, such as value comparison and a range condition. Accordingly, you can define schemas like those of RDA without having to work out implementation focusing on search with a key condition.
The following types are available for indexing.
- String type
- Integer type
- Floating point type
- Time type
- 2D type
2.5 Importance of Key Coding
GridDB provides complicated advanced search using a dedicated query language TQL. In complicated search with a combination of multiple conditions, however, search performance would decline because of multiple accesses to Container(s). In order to speed up search, it is effective to analyze search patterns of an application and deliberately design key coding. For example, for the case of search with multiple conditions combined by AND to fetch a pinpoint record, you can use single key search by incorporating key coding related to particular AND conditions. You can reduce the number of accesses to Container(s) to speed up search. Below you can see an example of searching for a Row of a sensor "voltage" of a facility "panel001."
Without any particular key coding, a query as shown below is used when searching for a Row with "'panel001' as a facility ID" and "'voltage' as a sensor type" from a sensor information Collection (Sensor_col) in which sequential positive numbers are assigned to sensor IDs (e.g., 1, 2, 3, …).
select * from Sensor_col where equipId = "panel001" AND sensorType = "voltage"
On the other hand, a query as shown below is available when searching for a Row with "'panel001_voltage' as a sensor ID" from a sensor information Collection (Sensor_col) incorporating key coding to make a sensor ID by concatenating a facility ID and a sensor ID (e.g., panel001_voltage).
select * from Sensor_col where sensorId = "panel001_voltage"
2.6 Granularity of Collection and Row
GridDB can be composed of multiple nodes, so as to increase storage capacity and improve throughput by scaling out. To do this, a set of Rows need to be divided into multiple sets and distributively stored in multiple Collections. You need to design your application to divide a set of Rows (construct a Collection) because GridDB does not have automated tooling. Granularity of Collection division should be properly designed in the cases below.
- Divide a huge size of Collection exceeding the real memory size of a computer into multiple small size of Collections for management.
- Prepare a TimeSeries for each tag/sensor to manage time-series data for each tag/sensor.
- Divide a highly frequently referenced Collection into multiple Collections for load distribution.
GridDB manages Rows written in memory; so you can reduce the cost of creating and referencing Rows (memory) and speed up processing by designing proper granularity of Rows in consideration of the performance balance of your application. Additionally, since GridDB does not support JOIN, you have to take time and effort to implement comparable logic in your application. Therefore, it is advisable to design schema implementation so as to avoid use of JOIN in consideration of the performance balance of your application. You should define schemas so as to attain proper granularity of Rows in the cases below.
- If JOIN is frequently used in an application, adopt schema definitions in a form of cartesian product in consideration of data size and storage performance balance.
- In order to speed up referencing particular Columns, separate such Columns to define separate schemas for each, so as to reduce I/O.
- If particular partial Columns are highly frequently updated, separate such Columns to define separate schemas for each, so as to minimize a memory copy.
3 Schema Designing for the Example
3.1 Generalities about Schema Designing in GridDB
For data management using GridDB, the following should be considered in schema designing.
- In order to avoid complicated search and speed up processing, properly design key coding rules and use key search only.
- In order to avoid JOIN operations and speed up processing, store data based on the schemas in a form of cartesian product without normalization purposely.
- In order to conduct search with a value condition, index a Column to be specified in a condition.
- In order to improve the performance of scaling out time-series data, create a TimeSeries for each sensor and store each data in it.
- In order to prevent inconsistency in update transactions, put concurrently updated Columns into one Collection, if possible.
3.2 Schema and Division of Collections
Facility information, sensor data history information, and alert history information are separately stored in Collections and TimeSeries below, respectively.
| Data | Quantity | Container name |
|---|---|---|
| Facility information | One Collection | equipment_col |
| Sensor history information | One TimeSeries per sensor | Sensor ID assigned (Example: panel001_voltage) |
| Alert history information | One Collection | alert_col |
And, by preparing a sensor ID naming rule as below, relationship between facilities and sensors can be expressed without using sensor information data.
-
Concatenate a facility ID and a sensor type with "_" to make a sensor ID (a form of "facility ID"_"sensor type").
- Example : panel001_voltage
Facility information, sensor data history information, and alert history information are defined based on the schema shown below.
// Facility information
class Equip {
@RowKey String id; // Facility ID
String name; // Facility name
Blob spec; // Specification information
}
// Sensor history
class Point {
@RowKey Date time; // Date and time
double value; // Sensor value
String status; // Sensor status
}
// Alert history
class Alert {
@RowKey int id; // Alert ID
Date timestamp;// Date and time
String sensorId; // Sensor ID
int level; // Alert level
String detail; // Alert detail information
}
- The facility information Collection is a Collection storing the information on each facility.It has a schema defined by "class Equip" shown above and stores a facility ID, a facility name and facility specifications for each record.
- The sensor history consists of a set of TimeSeries for each sensor.Each TimeSeries has a schema defined by "class Point" shown above and stores a date and time of measurement, a measured value, and status information for each record.
- The alert history Collection is a Collection storing alert information detected by a sensor.It has a schema defined by "class Alert" shown above and stores an alert ID, a date and time of alert, an ID of a sensor detecting an alert, an alert level, and alert detail information.
4 Basics of Client Programs of GridDB
This chapter shows an outline of a processing flow of a client program on GridDB. Concrete program examples are shown in "Examples of Client Programs."
4.1 Storing Data in Collection
A flow of storing data in a Collection is shown below.
First, if there is no Collection to store data in, newly create a Collection following the procedure below:
- Get a GridStore instance.
- Create a Collection.
You can store data in an existing Collection by the following procedure:
- Get a GridStore instance.
- Get a Collection.
- Set operation parameters.
- Create indexes.
- Create values to be stored.
- Store values in the Collection.
- Perform a commit at proper intervals.
- Release the GridStore instance.
You can also store data in a TimeSeries by the same procedure as above for a Collection.
4.2 Collection Search
A flow of Collection data search is shown below:
- Get a GridStore instance.
- Get a Collection.
- Search a Collection.
- Get search results.
- Release the GridStore instance.
The following two search methods are available. See "GridStore User's Manual" for more information on the methods.
- Method of searching with specification of a key of KV (get)
- Method of searching with a condition specifying a value of KV (query)
You can also search TimeSeries data by the same procedure as above for Collection data.
5 Examples of Client Programs
This examples below are intended to provide an application which has the following capabilities:
- Storing facility information
- Storing alarm history
- Storing sensor data
- Searching for and displaying facility information and sensor data showing abnormality
The following sections describe client programs which implement each capability based on the schema definitions shown in the previous chapter.
5.1 Storing Facility Information
Technically, in the monitoring system, the information on facility configuration and specifications needs to be stored in a database. For simplicity, however, this section shows a sample program which loads facility information except facility specifications collectively from a CSV file storing the data. An outline of a processing flow is shown below.
- Connect to a server and get a GridStore instance.
- Create a facility information Collection Collection name with a specified name ("equipment_col") in GridStore and get it.
- Create indexes to be used for search.
-
Store a value repeatedly while reading a CSV file, as follows:
- 4-1. Analyze a read CSV-formatted line and create a facility information object to store.
- 4-2. Store (put) the created facility information object in the facility information Collection.
- 4-3. Perform a commit if repeated the predetermined number of times.
- Release the GridStore instance if all CSV-formatted lines are processed.
A concrete sample program is shown below:
package pvrms;
import java.io.FileReader;
import java.io.IOException;
import java.text.ParseException;
import java.util.Properties;
import com.opencsv.CSVReader;
import com.toshiba.mwcloud.gs.Collection;
import com.toshiba.mwcloud.gs.GSException;
import com.toshiba.mwcloud.gs.GridStore;
import com.toshiba.mwcloud.gs.GridStoreFactory;
import com.toshiba.mwcloud.gs.RowKey;
// Facility information
class Equip {
@RowKey String id;
String name;
//Blob spec; // For simplicity, spec information is not used.
}
public class SimplePv0 {
/*
* Load facility information from a CSV file.
*/
public static void main(String[] args) throws GSException, ParseException, IOException {
final String equipColName = "equipment_col";
if (args.length != 4) {
System.out.println("Usage:pvrms.SimplePv0 Addr Port ClusterName Database ");
System.exit(1);
}
// Get a GridStore instance.
Properties props = new Properties();
props.setProperty("notificationAddress", args[0]);
props.setProperty("notificationPort", args[1]);
props.setProperty("clusterName", args[2]);
props.setProperty("database", args[3]);
props.setProperty("user", "system");
props.setProperty("password", "manager");
GridStore store = GridStoreFactory.getInstance().getGridStore(props);
// Read a CSV file.
String dataFileName = "equipName.csv";
CSVReader reader = new CSVReader(new FileReader(dataFileName));
String[] nextLine;
// Create a Collection.
Collection<String,Equip> equipCol = store.putCollection(equipColName, Equip.class);
// Create indices for Columns.
equipCol.createIndex("id");
equipCol.createIndex("name");
// Set autocommit mode to OFF.
equipCol.setAutoCommit(false);
// Set commit interval.
Long commitInterval = (long) 1;
// Store a value.
Equip equip = new Equip();
Long cnt = (long) 0;
byte[] b = new byte[1];
b[0] = 1;
while ((nextLine = reader.readNext()) != null) {
// Store facility information.
equip.id = nextLine[0];
equip.name = nextLine[1];
equipCol.put(equip);
cnt++;
if(0 == cnt%commitInterval) {
// Commit a transaction.
equipCol.commit();
}
}
// Commit a transaction.
equipCol.commit();
System.out.println("Container equip_col has been created. " + cnt + " rows have been put.");
// Release resources.
store.close();
reader.close();
}
}
5.2 Storing Alarm History
Technically, in the monitoring system, a sensor or a facility directly sends an alert to and store it in GridDB. For simplicity, however, this section shows a sample program which loads alert history data collectively from a CSV file storing the data. An outline of a processing flow is shown below.
- Connect to a server and get a GridStore instance.
- Create an alert Collection with a specified name ("alert_col") in GridStore and get it.
- Create indexes to be used for search.
-
Store a value repeatedly while reading a CSV file, as follows:
- 4-1. Analyze a read CSV-formatted line and create an alert object to store.
- 4-2. Store (put) the created alert object in the alert Collection.
- 4-3. Perform a commit if repeated the predetermined number of times.
- Release the GridStore instance if all CSV-formatted lines are processed.
A concrete sample program is shown below:
package pvrms;
import java.io.FileReader;
import java.io.IOException;
import java.text.ParseException;
import java.text.SimpleDateFormat;
import java.util.Date;
import java.util.Properties;
import com.opencsv.CSVReader;
import com.toshiba.mwcloud.gs.Collection;
import com.toshiba.mwcloud.gs.GSException;
import com.toshiba.mwcloud.gs.GridStore;
import com.toshiba.mwcloud.gs.GridStoreFactory;
import com.toshiba.mwcloud.gs.RowKey;
// Alert information
class Alert {
@RowKey Long id;
Date timestamp;
String sensorId;
int level;
String detail;
}
public class SimplePv1 {
/*
* Load alert data from a CSV file.
*/
public static void main(String[] args) throws GSException, ParseException, IOException {
final String alertColName = "alert_col";
if (args.length != 4) {
System.out.println("Usage:pvrms.SimplePv1 Addr Port ClusterName Database ");
System.exit(1);
}
// Get a GridStore instance.
Properties props = new Properties();
props.setProperty("notificationAddress", args[0]);
props.setProperty("notificationPort", args[1]);
props.setProperty("clusterName", args[2]);
props.setProperty("database", args[3]);
props.setProperty("user", "system");
props.setProperty("password", "manager");
GridStore store = GridStoreFactory.getInstance().getGridStore(props);
// Read a CSV file.
String dataFileName = "alarmHistory.csv";
CSVReader reader = new CSVReader(new FileReader(dataFileName));
String[] nextLine;
// Create a Collection.
Collection<Long,Alert> alertCol = store.putCollection(alertColName, Alert.class);
// Create indices for columns.
alertCol.createIndex("timestamp");
alertCol.createIndex("level");
// Set autocommit mode to OFF.
alertCol.setAutoCommit(false);
// Set commit interval.
Long commitInterval = (long) 24;
// Store a value.
SimpleDateFormat format = new SimpleDateFormat("yyyy/MM/dd HH:mm:ss");
Alert alert = new Alert();
Long cnt = (long) 0;
while ((nextLine = reader.readNext()) != null) {
String dateS = nextLine[0];
String timeS = nextLine[1];
String datetimeS = dateS + " " + timeS ;
Date date = format.parse(datetimeS);
alert.id = ++cnt;
alert.timestamp = date;
alert.sensorId = nextLine[2];
alert.level = Integer.valueOf(nextLine[3]);
alert.detail = nextLine[4];
alertCol.put(alert);
if(0 == cnt%commitInterval) {
// Commit a transaction.
alertCol.commit();
}
}
// Commit a transaction.
alertCol.commit();
System.out.println("Container alert_col has been created. " + cnt + " rows have been put.");
// Release resources.
store.close();
reader.close();
}
}
5.3 Storing Sensor Data
Technically, in the monitoring system, a sensor directly sends a measured value to be stored in GridDB. For simplicity, however, this section shows a sample program which loads sensor data collectively from a CSV file storing the data. An outline of a processing flow is shown below.
- Connect to a server and get a GridStore instance.
-
Read the first line of a CSV file and create a set of TimeSeries to be used beforehand, as follows:
- 2-1. Analyze the first CSV-formatted line and obtain multiple sensor IDs (= the names of TimeSeries to be created).
- 2-2. Create an alert Collection in GridStore for each obtained sensor ID.
-
Store a value repeatedly, while reading the rest of the CSV file, as follows:
- 3-1. Analyze a read CSV-formatted file and create a Point object to store.
- 3-2. Store (put) the created Point object in an appropriate TimeSeries.
- Release the GridStore instance if all CSV-formatted lines are processed.
A concrete sample program is shown below:
package pvrms;
import java.io.FileReader;
import java.io.IOException;
import java.text.ParseException;
import java.text.SimpleDateFormat;
import java.util.Date;
import java.util.Properties;
import com.opencsv.CSVReader;
import com.toshiba.mwcloud.gs.GridStore;
import com.toshiba.mwcloud.gs.GridStoreFactory;
import com.toshiba.mwcloud.gs.RowKey;
import com.toshiba.mwcloud.gs.TimeSeries;
// Sensor data
class Point {
@RowKey Date time;
double value;
String status;
}
public class SimplePv2 {
/*
* Load time-series data from a CSV file.
*/
public static void main(String[] args) throws ParseException, IOException {
if (args.length != 4) {
System.out.println("Usage:pvrms.SimplePv2 Addr Port ClusterName Database ");
System.exit(1);
}
// Get a GridStore instance.
Properties props = new Properties();
props.setProperty("notificationAddress", args[0]);
props.setProperty("notificationPort", args[1]);
props.setProperty("clusterName", args[2]);
props.setProperty("database", args[3]);
props.setProperty("user", "system");
props.setProperty("password", "manager");
GridStore store = GridStoreFactory.getInstance().getGridStore(props);
// Read a CSV file.
String dataFileName = "sensorHistory.csv";
CSVReader reader = new CSVReader(new FileReader(dataFileName));
String[] nextLine;
nextLine = reader.readNext();
// Read a sensor ID and create a TimeSeries.
String[] tsNameArray = new String[nextLine.length];
for(int j = 0; j < nextLine.length; j++) {
tsNameArray[j] = nextLine[j];
store.putTimeSeries(tsNameArray[j], Point.class);
}
// Store a value in each TimeSeries.
SimpleDateFormat format = new SimpleDateFormat("yyyy/MM/dd HH:mm:ss");
Point point = new Point();
Long cnt = (long) 0;
while ((nextLine = reader.readNext()) != null) {
String dateS = nextLine[0];
String timeS = nextLine[1];
String datetimeS = dateS + " " + timeS ;
Date date = format.parse(datetimeS);
for(int i = 0, j = 2; j < nextLine.length; i++, j+=2) {
TimeSeries<Point> ts = store.getTimeSeries(tsNameArray[i], Point.class);
point.time = date;
point.value = Double.valueOf(nextLine[j]);
point.status = nextLine[j+1];
ts.put(date,point);
}
cnt++;
}
System.out.println(tsNameArray.length + " timeseries containers have been created. " + cnt + " rows have been put.");
// Release resources.
store.close();
reader.close();
}
}
5.4 Monitoring Abnormalities
This section shows a sample program which simulates monitoring abnormalities (displaying facility information related to a serious alert occurring within 24 hours and time-series data just before the alert), referencing facility information, sensor data and alert data stored in GridDB. An outline of a processing flow is shown below.
- Connect to a server and get a GridStore instance.
- Get an alert Collection with a specified name ("alert_col") from the GridStore instance.
- In order to search the alert Collection for serious alerts (level > 3) occurring within 24 hours, conduct a search with a condition about level and time.Use TQL for search with a condition specifying values.
-
Search for facility information related to a serious alert obtained in search results and time-series data just before the alert, as follows:
- 4-1. First, obtain a facility ID string from a string of a sensor ID causing a serious alert.
- 4-2. Next, get a facility information Collection with a specified name ("equipment_col") from the GridStore instance.
- 4-3. Get facility information from the facility information Collection by specifying the obtained facility ID as a key.
- 4-4. Then, get a TimeSeries with a name indicating a sensor ID from the GridStore instance.
- 4-5. Search the obtained TimeSeries for time-series data for ten minutes before the alert.Specify a time range in a search condition.
A concrete sample program is shown below:
package pvrms;
import java.io.IOException;
import java.text.ParseException;
import java.text.SimpleDateFormat;
import java.util.Date;
import java.util.Locale;
import java.util.Properties;
import com.toshiba.mwcloud.gs.Collection;
import com.toshiba.mwcloud.gs.GSException;
import com.toshiba.mwcloud.gs.GridStore;
import com.toshiba.mwcloud.gs.GridStoreFactory;
import com.toshiba.mwcloud.gs.Query;
import com.toshiba.mwcloud.gs.RowSet;
import com.toshiba.mwcloud.gs.TimeSeries;
import com.toshiba.mwcloud.gs.TimeUnit;
import com.toshiba.mwcloud.gs.TimestampUtils;
public class SimplePv3 {
/*
* Displays facility information related to serious alerts occurring within
* 24 hours and time-series data just before each alert.
*/
public static void main(String[] args) throws GSException, ParseException, IOException {
final String alertColName = "alert_col";
final String equipColName = "equipment_col";
if (args.length != 4) {
System.out.println("Usage:pvrms.SimplePv3 Addr Port ClusterName Database ");
System.exit(1);
}
// Get a GridStore instance.
Properties props = new Properties();
props.setProperty("notificationAddress", args[0]);
props.setProperty("notificationPort", args[1]);
props.setProperty("clusterName", args[2]);
props.setProperty("database", args[3]);
props.setProperty("user", "system");
props.setProperty("password", "manager");
GridStore store = GridStoreFactory.getInstance().getGridStore(props);
Collection<Long,Alert> alertCol = store.getCollection(alertColName, Alert.class);
// Set alert monitoring time.
SimpleDateFormat sf = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss.SSS",Locale.JAPAN);
Date tm1=sf.parse("2015-01-02 08:00:00.000");
System.out.println("Search for serious alerts (level > 3) within 24 hours from alert_col.");
//String from = TimestampUtils.format( TimestampUtils.add(new Date(System.currentTimeMillis()), -24, TimeUnit.HOUR) );
String from = TimestampUtils.format( TimestampUtils.add(tm1, -24, TimeUnit.HOUR) );
Query<Alert> alertQuery = alertCol.query( "select * where level > 3 and " +
"timestamp > " + "TIMESTAMP('" + from + "')" );
System.out.println("select * where level > 3 and " +
"timestamp > " + "TIMESTAMP('" + from + "')");
RowSet<Alert> alertRs = alertQuery.fetch();
System.out.println("Display facility information related to a sensor occurring a serious alert and time-series data just before the alert.");
System.out.println(" Alert count: " + alertRs.size());
while( alertRs.hasNext() ) {
Alert seriousAlert = alertRs.next();
// Obtain a facility ID and a sensor type.
String sensorId = seriousAlert.sensorId;
String sensorType = sensorId.substring(sensorId.indexOf("_")+1);
// Obtain facility information.
Collection<String,Equip> equipCol = store.getCollection(equipColName, Equip.class);
Equip equip = equipCol.get(sensorId);
System.out.println("[Equipment] " + equip.name + " (sensor) "+ sensorType);
System.out.println("[Detail] " + seriousAlert.detail);
// Search for time-series data just before the alert.
String tsName = seriousAlert.sensorId;
TimeSeries<Point> ts = store.getTimeSeries(tsName, Point.class);
Date endDate = seriousAlert.timestamp;
Date startDate = TimestampUtils.add(seriousAlert.timestamp, -10, TimeUnit.MINUTE);
RowSet<Point> rowSet = ts.query(startDate, endDate).fetch();
while (rowSet.hasNext()) {
Point ret = rowSet.next();
System.out.println(
"[Result] " +sf.format(ret.time) +
" " + ret.value + " " + ret.status);
}
System.out.println("");
}
// Release a resource.
store.close();
}
}