GridDB Advanced Edition SQL reference
Revision: 2203
Table of Contents
- 1 Introduction
- 2 SQL description format
- 3 SQL commands supported by GridDB AE
- 3.1 Data definition language (DDL)
- 3.2 Data control language (DCL)
- 3.3 Data management language (DML)
- 3.4 Clauses
- 3.5 Predicates
- 3.6 Comment
- 3.7 Functions
- 3.8 Hints
- 4 Metatables
- 5 References
- 6 Annex: Keywords
1 Introduction
1.1 Aim & configuration of this manual
This manual describes how to write a SQL command in the GridDB Advanced Edition. Please read this manual before using the GridDB Advanced Edition.
The functions described in this manual can be used exclusively by users with GridDB Advanced Edition license.
1.2 About the GridDB Advanced Edition
An interface (NewSQL interface) that can access GridDB data using SQL is provided in the GridDB Advanced Edition. This manual explains the SQL commands of the NewSQL interface used to access a database supported by the GridDB Advanced Edition (hereinafter referred to as GridDB AE). Note that the interface is different from the NoSQL interface.
The NewSQL interface treats an container that is created through the NoSQL interface as an table, and it can be referred and updated. Container schema and indices can also be updated. On the other hand, a table that is created through the NewSQL interface can be referred and updated as a container through the NoSQL interface.
See “GridDB Advanced Edition JDBC driver guide” (GridDB_AE_JDBC_DriverGuide.html) for how to use the JDBC driver.
2 SQL description format
This chapter shows the descriptive format of the SQL that can be used in the NewSQL interface.
2.1 Usable operations
Besides the SELECT command, DDL command (Data Definition Language) such as CREATE TABLE, and INSERT/DELETE are also supported. See SQL commands supported by GridDB AE for details.
2.2 Data types
2.2.1 Data types used in data storage
The data types used for data storage in the NewSQL interface are shown in Table 1. These data type names can be specified as a column data type when creating a table.
| Data type | Description |
|---|---|
| BOOL | True/False |
| BYTE | Integer value from -27 to 27-1 (8 bits) |
| SHORT | Integer value from -215 to 215-1 (16 bits) |
| INTEGER | Integer value from -231 to 231-1 (32 bits) |
| LONG | Integer value from -263 to 263-1 (64 bits) |
| FLOAT | Single-precision data type (32 bits), floating-point number defined in IEEE754 |
| DOUBLE | Double-precision data type (64 bits), floating-point number defined in IEEE754 |
| TIMESTAMP | Data type expressing the date and time. When storing and acquiring the value of only date and only time, |
| it is assumed that time 00:00:00 or date 1970-01-01 is specified respectively. | |
| STRING | Text that is composed of an arbitrary number of characters using the unicode code point. |
| BLOB | Data type for binary data such as images and voice, etc. |
| Large objects to be saved directly in the input format. | |
| The character x or X can also be added to create a hexadecimal expression such as X'23AB'. |
A NULL value can be registered to table. The results of operators that is related to NULL value such as "IS NULL" are SQL-compliant.
2.2.2 Expression that can be specified as a column data type when creating a table
In the NewSQL interface, for data type names that are described as column data types when the table was created, even if the name does not match the data type name given in Data types used in data storage, follow the rules to interpret and determine the data type to use for data storage.
Check the following rules in sequence starting from the top and determine the data type to use for data storage based on the applicable rule. The data type name described when checking the rules and the strings to check using the rules are not case sensitive. If multiple rules apply, the rule ranked higher will be prioritized. If no rules are applicable, an error will occur and table creation will fail.
| Rule no. | Specified column type name string | Column type of the table to be created |
|---|---|---|
| 1 | Type names listed in Data types used in data storage | Same as specified type |
| 2 | "REAL" | DOUBLE |
| 3 | "TINYINT" | BYTE |
| 4 | "SMALLINT" | SHORT |
| 5 | "BIGINT" | LONG |
| 6 | Type name including "INT" | INTEGER |
| 7 | Type name including any of "CHAR", "CLOB", "TEXT" | STRING |
| 8 | Type name including "BLOB" | BLOB |
| 9 | Type name including any of "REAL", "DOUB" | DOUBLE |
| 10 | Type name including "FLOA" | FLOAT |
An example to determine the data type using this rule is shown.
- Name of specified data type is "BIGINTEGER" -> INTEGER (Rule 6)
- Name of specified data type is "LONG" -> LONG (Rule 1)
- Name of specified data type is "TINYINT" -> BYTE (Rule 3)
- Name of specified data type is "FLOAT" -> FLOAT (Rule 1)
- Name of specified data type is "VARCHAR" -> STRING (Rule 7)
- Name of specified data type is "CHARINT" -> INTEGER (Rule 6)
- Name of specified data type is "BIGBLOB" -> BLOB (Rule 8)
- Name of specified data type is "FLOATDOUB" -> DOUBLE (Rule 9)
- Name of specified data type is "INTREAL" -> INTEGER (Rule 6)
- Name of specified data type is "FLOATINGPOINT" -> INTEGER (Rule 6)
- Name of specified data type is "DECIMAL" -> error
Write the data type as follows when using the same data type in the NewSQL interface as the data type used in the clients of the NoSQL interface. However, some equivalent data types may not be available as they do not exist.
| Data type in a NoSQL interface client | Column data type descriptions of |
|---|---|
| a NewSQL interface with the same data types | |
| STRING (string data type) | "STRING" or "Expression to be STRING" |
| BOOL (Boolean) | "BOOL" |
| BYTE (8-bit integer) | "BYTE" or "Expression to be BYTE" |
| SHORT (16-bit integer) | "SHORT" or "Expression to be SHORT" |
| INTEGER (32-bit integer) | "INTEGER" or "Expression to be INTEGER" |
| LONG (64-bit integer) | "LONG" or "Expression to be LONG" |
| FLOAT (32 bitwise floating point number) | "FLOAT" or "Expression to be FLOAT" |
| DOUBLE (64 bitwise floating point number) | "DOUBLE" or "Expression to be DOUBLE" |
| TIMESTAMP (time data type) | "TIMESTAMP" |
| GEOMETRY (spatial data type) | Non-existent (cannot be used) |
| BLOB | "BLOB" or "Expression to be BLOB" |
| ARRAY | Non-existent (cannot be used) |
2.2.3 Data type when accessing a container as a table and the treatment of the values
The column data types of the container and treatment of the values when accessing a container created in a NoSQL interface client as a table in the NewSQL interface are shown below.
| Column type of container | Data type mapped in NewSQL | Value |
|---|---|---|
| STRING | STRING | Same as original value |
| BOOL | BOOL | Same as original value |
| BYTE | BYTE | Same as original value |
| SHORT | SHORT | Same as original value |
| INTEGER | INTEGER | Same as original value |
| LONG | LONG | Same as original value |
| FLOAT | FLOAT | Same as original value |
| DOUBLE | DOUBLE | Same as original value |
| TIMESTAMP | TIMESTAMP | Same as original value |
| GEOMETRY | STRING | All the values are NULL |
| BLOB | BLOB | Same as original value |
| ARRAY | STRING | All the values are NULL |
2.3 User and database
There are 2 types of GridDB user, an administrator user and a general user, which differ in terms of the functions which can be used. In addition, access can be separated on a user basis by creating a database. See “GridDB technical reference” (GridDB_TechnicalReference.html) for details of the user and database.
2.4 Naming rules
Naming rules are following:
- A database name, table name, column name, index name and general user name is a string composed of 1 or more ASCII alphanumeric characters, the underscore “_” , the hyphen “-” , the dot “.” , the slash “/” and the equal “=”.
- If the first character of the name is a number or the name contains special characters except the underscore, it is necessary to enclose the name with double quotation marks.
- For table name, the “@” character can also be specified for the node affinity function.
See “GridDB technical reference” (GridDB_TechnicalReference.html) for the details of node affinity function, naming rules and limitations.
3 SQL commands supported by GridDB AE
Supported SQL commands are in the table as follows.
| Command | Overview |
|---|---|
| CREATE DATABASE | Create a database. |
| CREATE TABLE | Create a table. |
| CREATE INDEX | Create an index. |
| CREATE USER | Create a general user. |
| DROP DATABASE | Delete a database. |
| DROP TABLE | Delete a table. |
| DROP INDEX | Delete an index. |
| DROP USER | Delete a general user. |
| SET PASSWORD | Change the password of a general user. |
| ALTER TABLE | Change the structure of a table. |
| GRANT | Assign database access rights to a general user. |
| REVOKE | Revoke database access rights from a general user. |
| SELECT | Select data. |
| INSERT | Insert rows into a table. |
| DELETE | Delete rows from a table. |
| UPDATE | Update rows in a table. |
| Comment | Add a comment. |
| Hints | Control an execution plan. |
An explanation for each category of SQL command is given in this chapter.
3.1 Data definition language (DDL)
3.1.1 CREATE DATABASE
Create a database.
Syntax
CREATE DATABASE database_name;
Specifications
- Can be executed by an administrator user only.
- Databases with the same name as “public”, “information_schema” cannot be created as these are reserved for internal use in GridDB.
- Nothing will be changed if a database with the same name already exists.
- See Naming rules for the rules of database name.
3.1.2 CREATE TABLE
3.1.2.1 Creating a table
Create a table.
Syntax
-- Table (Collection)
CREATE TABLE [IF NOT EXISTS] table_name ( column definition [, column definition ...] );
-- Timeseries table (Timeseries container)
CREATE TABLE [IF NOT EXISTS] table_name ( column_name TIMESTAMP PRIMARY KEY [, column definition ...] )
USING TIMESERIES [WITH (property_key=property_value [, property_key=property_value ...])];
column definition
- column_name data_type [ column_constraint ]
column_constraint
- PRIMARY KEY (only the 1st column can be specified)
- NULL
- NOT NULL
Specifications
- See Naming rules for the rules of table name and column name.
- If “IF NOT EXISTS” is specified, the specified table can be created only if another table with the same name does not exist.
- The column name and data type name need to be specified in column definition. See Data types used in data storage for the data types that can be specified.
- See “GridDB technical reference” (GridDB_TechnicalReference.html) for details of timeseries table.
-
For time series tables, options about expiry release can be specified by the format " WITH (property_key=property_value, ...)".
Function Item Property key Property value Expiry release function Type expiration_type STRING (Any of the followings. ROW: Row expiry release) Elapsed time expiration_time INTEGER Elapsed time unit expiration_time_unit STRING (Any of the followings. DAY / HOUR / MINUTE / SECOND / MILLISECOND ) Division count expiration_division_count INTEGER - See “GridDB technical reference” (GridDB_TechnicalReference.html) for details of each item.
Examples
-
Creating table
CREATE TABLE IF NOT EXISTS myTable ( key INTEGER PRIMARY KEY, value1 DOUBLE NOT NULL, value2 DOUBLE NOT NULL );
-
Creating timeseries table using the row expiry release function
CREATE TABLE IF NOT EXISTS myTimeseries ( mycolumn1 TIMESTAMP PRIMARY KEY, mycolumn2 STRING ) USING TIMESERIES WITH ( expiration_type='ROW', expiration_time=10, expiration_time_unit='DAY' );
3.1.2.2 Creating a partitioned table
Create a partitioned table.
See “GridDB technical reference” (GridDB_TechnicalReference.html) for details of each partitioning function.
(1) Creating a hash partitioned table
Syntax
-- Table (collection)
CREATE TABLE [IF NOT EXISTS] table_name ( column definition [, column definition ...] )
PARTITION BY HASH (column_name_of_partitioning_key) PARTITIONS division_count;
-- Timeseries table (timeseries container)
CREATE TABLE [IF NOT EXISTS] table_name ( column definition [, column definition ...] )
USING TIMESERIES [WITH (property_key=property_value, ...)]]
PARTITION BY HASH (column_name_of_partitioning_key) PARTITIONS division_count;
Specifications
- Create a hash partitioned table by the column name of partitioning key and the value of division count.
- Specify the value from 1 to 1024 for “division_count”.
- The column specified as partitioning key cannot be updated.
- For time series tables, options about expiry release can be specified by the format " WITH (property_key=property_value, ...)". The options that can be specified are same as normal table.
Examples
-
Creating a hash partitioned table
CREATE TABLE IF NOT EXISTS myHashPartition ( id INTEGER PRIMARY KEY, value STRING ) PARTITION BY HASH (id) PARTITIONS 128;
(2) Creating an interval partitioned table
Syntax
-- Table (collection)
CREATE TABLE [IF NOT EXISTS] table_name ( column definition [, column definition ...] )
[WITH (property_key=property_value, ...)]
PARTITION BY RANGE(column_name_of_partitioning_key) EVERY(interval_value [, interval_unit ]);
-- Timeseries table (timeseries container)
CREATE TABLE [IF NOT EXISTS] table_name ( column definition [, column definition ...] )
USING TIMESERIES [WITH (property_key=property_value, ...)]
PARTITION BY RANGE(column_name_of_partitioning_key) EVERY(interval_value [, interval_unit ]);
Specifications
- Specify the column which type is BYTE, SHORT, INTEGER, LONG or TIMESTAMP for “column_name_of_partitioning_key”.
- The column specified for “column_name_of_partitioning_key” is required to be “PRIMARY KEY” or have “NOT NULL” constraint.
- The column specified as partitioning key cannot be updated.
-
The following values can be specified as the “interval_value”.
Partitioning key type Possible interval value BYTE 1 to 127 SHORT 1 to 32767 INTEGER 1 to 2147483647 LONG 1000 to 9223372036854775807 TIMESTAMP from 1 - If the column of TIMESTAMP is specified, it is also required to specify the interval unit. DAY is the only value that can be specified as the interval unit.
- The interval unit cannot be specified for any types other than TIMESTAMP.
-
The options about expiry release can be specified by the format " WITH (property_key=property_value, ...)".
Function Item Property key Property value Expiry release function Type expiration_type STRING (Any of the followings. If omitted, PARTITION. ROW: Row expiry release PARTITION: Partition expiry release) Elapsed time expiration_time INTEGER Elapsed time unit expiration_time_unit STRING (Any of the followings. DAY / HOUR / MINUTE / SECOND / MILLISECOND ) Division count expiration_division_count INTEGER (Only specified for row expiry release) - The row expiry release can only be specified for timeseries table (timeseries container).
-
The partition expiry release can only be specified for followings:
- Timeseries table (timeseries container)
- Table (collection) whose partitioning key is TIMESTAMP type.
- See “GridDB technical reference” (GridDB_TechnicalReference.html) for details of each item.
Examples
-
Creating an interval partitioned table.
CREATE TABLE IF NOT EXISTS myIntervalPartition ( date TIMESTAMP PRIMARY KEY, value STRING ) PARTITION BY RANGE (date) EVERY (30, DAY);
-
Creating an interval partitioned table (timeseries table) using the partition expiry release function.
CREATE TABLE IF NOT EXISTS myIntervalPartition2 ( date TIMESTAMP PRIMARY KEY, value STRING ) USING TIMESERIES WITH ( expiration_type='PARTITION', expiration_time=90, expiration_time_unit='DAY' ) PARTITION BY RANGE (date) EVERY (30, DAY);
(3) Creating an interval-hash partitioned table
Syntax
-- Table (collection)
CREATE TABLE [IF NOT EXISTS] table_name ( column definition [, column definition ...] )
[WITH (property_key=property_value, ...) ]
PARTITION BY RANGE(column_name_of_interval_partitioning_key) EVERY(interval_value [, interval_unit ])
SUBPARTITION BY HASH(column_name_of_hash_partitioning_key) SUBPARTITIONS division_count;
-- Timeseries table (timeseries container)
CREATE TABLE [IF NOT EXISTS] table_name ( column definition [, column definition ...] )
USING TIMESERIES [WITH (property_key=property_value, ...)]
PARTITION BY RANGE(column_name_of_interval_partitioning_key) EVERY(interval_value [, interval_unit ])
SUBPARTITION BY HASH(column_name_of_hash_partitioning_key) SUBPARTITIONS division_count;
Specifications
- Specify the column which type is BYTE, SHORT, INTEGER, LONG or TIMESTAMP for “column_name_of_interval_partitioning_key”.
- The column specified for “column_name_of_interval_partitioning_key” is required to be “PRIMARY KEY” or have “NOT NULL” constraint.
-
The following values can be specified as the “interval_value“.
Partitioning key type Possible interval value BYTE 1 to 127 SHORT 1 to 32767 INTEGER 1 to 2147483647 LONG 1000 * division_count to 9223372036854775807 TIMESTAMP from 1 - If the column of TIMESTAMP is specified, it is also required to specify the interval unit. DAY is the only value that can be specified as the interval unit.
- The interval unit cannot be specified for any types other than TIMESTAMP.
- Specify the value from 1 to 1024 for “division_count”.
- The column specified as partitioning key cannot be updated.
- The options about expiry release can be specified by the format " WITH (property_key=property_value, ...)". The options that can be specified are same as interval partitioned table.
Examples
-
Creating an interval-hash partitioned table
CREATE TABLE IF NOT EXISTS myIntervalHashPartition ( date TIMESTAMP PRIMARY KEY, value STRING ) PARTITION BY RANGE (date) EVERY (60, DAY) SUBPARTITION BY HASH (value) SUBPARTITIONS 64;
-
Creating an interval-hash partitioned table (timeseries table) using the partition expiry release function.
CREATE TABLE IF NOT EXISTS myIntervalHashPartition2 ( date TIMESTAMP PRIMARY KEY, value STRING ) USING TIMESERIES WITH ( expiration_type='PARTITION', expiration_time=90, expiration_time_unit='DAY' ) PARTITION BY RANGE (date) EVERY (60, DAY) SUBPARTITION BY HASH (value) SUBPARTITIONS 64;
3.1.3 CREATE INDEX
Create an index.
Syntax
CREATE INDEX [IF NOT EXISTS] index_name ON table_name ( column_name_to_be_indexed );
Specifications
- See Naming rules for the rules of index name.
- An index with the same name as an existing index cannot be created.
- If a transaction under execution exists in a table subject to processing, the system will wait for these to be completed before creating the data.
- An index cannot be created on a column of BLOB type.
3.1.4 CREATE USER
Create a general user.
Syntax
CREATE USER user_name IDENTIFIED BY 'password_string' ;
Specifications
- See Naming rules for the rules of user name.
- Can be executed by an administrator user only.
- A user with the same name as an administrator user (admin and system) registered during installation cannot be created.
- Only ASCII characters can be used in the password string. The password is case-sensitive.
3.1.5 DROP DATABASE
Delete a database.
Syntax
DROP DATABASE database_name;
Specifications
- Can be executed by an administrator user only.
- Databases with names starting with “gs#” and those named “public” and “information_schema” cannot be deleted as these are reserved for internal use in GridDB.
- A database containing tables created by a user cannot be deleted.
3.1.6 DROP TABLE
Delete a table.
Syntax
DROP TABLE [IF EXISTS] table_name;
Specifications
- If “IF EXISTS” is specified, nothing will change if no table with the specified name exists.
- If there is an active transaction involving the table, the table will be deleted only after the transaction is completed.
3.1.7 DROP INDEX
Delete the specified index.
Syntax
DROP INDEX [IF EXISTS] index_name ON table_name;
Specifications
- If “IF EXISTS” is specified, nothing will change if no index with the specified name exists.
- If there is an active transaction involving the table, the table will be deleted only after the transaction is completed.
- The unnamed index creating through NoSQL I/F can not be deleted by “DROP INDEX”.
3.1.8 DROP USER
Delete a general user.
Syntax
DROP USER user_name;
Specifications
- Can be executed by an administrator user only.
3.1.9 SET PASSWORD
Change the password of a general user.
Syntax
SET PASSWORD [FOR user_name ] = 'password_string';
Specifications
- An administrator user can change the passwords of all general users.
- A general user can change its own password only.
3.1.10 ALTER TABLE
Change the structure of a table.
3.1.10.1 Adding columns to a table
Add columns to the end of the table.
Syntax
ALTER TABLE table_name ADD [COLUMN] column definition [,ADD [COLUMN] column definition ...];
column definition
- column_name data_type [ column_constraint ]
column_constraint
- NULL
- NOT NULL
Specifications
- The added column is located in the end of the table. If multiple columns are specified, they are located in their order.
- "PRIMARY KEY" can not be specified to the column constraint.
- If the same name column exists, an error occurs.
Examples
-
Adding multiple columns to the table
ALTER TABLE myTable1 ADD COLUMN col111 STRING NOT NULL, ADD COLUMN col112 INTEGER;
3.1.10.2 Deleting data partitions
Delete data partitions created by table partitioning.
Syntax
ALTER TABLE table_name DROP PARTITION FOR ( value_included_in_the_data_partition );
Specifications
- Data partitions can be deleted only for interval and interval-hash partitioning.
- Specify the value included in the data partition to be deleted.
- Data in the range of the once deleted data partition (from the lower limit value to the upper limit value of the data partition) cannot be registered.
- The lower limit value of a data partition can be checked by metatable. The upper limit value is obtained by adding the interval value to the lower limit value.
- For interval-hash partitioned tables, there are multiple data partitions which have the same lower limit value, and the maximum number of those partitions is equal to the hash division count. Those data partitions are deleted simultaneously. Deleted partitions are checked by metatable.
See Metatables for the details on the metatable.
Examples
Interval partitioned table
-
Check the lower limit value of the interval partitioned table “myIntervalPartition1” (partitioning key type: TIMESTAMP, interval: 30 DAY)
SELECT PARTITION_BOUNDARY_VALUE FROM "#table_partitions" WHERE TABLE_NAME='myIntervalPartition1' ORDER BY PARTITION_BOUNDARY_VALUE; PARTITION_BOUNDARY_VALUE ----------------------------------- 2017-01-10T13:00:00Z 2017-02-09T13:00:00Z 2017-03-11T13:00:00Z : -
Delete unnecessary data partitions
ALTER TABLE myIntervalPartition1 DROP PARTITION FOR ('2017-01-10T13:00:00Z');
Interval-hash partitioned table
-
Check the lower limit value of each data partitions on the interval hash partitioned table “myIntervalHashPartition” (partitioning key type: TIMESTAMP, interval value: 90 DAY, division count 3)
SELECT PARTITION_BOUNDARY_VALUE FROM "#table_partitions" WHERE TABLE_NAME='myIntervalHashPartition' ORDER BY PARTITION_BOUNDARY_VALUE; PARTITION_BOUNDARY_VALUE ----------------------------------- 2016-08-01T10:00:00Z # There are 3 data partitions that are 2016-08-01T10:00:00Z # divided by same boundary value. 2016-08-01T10:00:00Z # 2016-10-30T10:00:00Z 2016-10-30T10:00:00Z 2016-10-30T10:00:00Z 2017-01-29T10:00:00Z : -
Delete unnecessary data partitions
ALTER TABLE myIntervalHashPartition DROP PARTITION FOR ('2016-09-15T10:00:00Z'); -
Data partitions that have same boundary value will be deleted
SELECT PARTITION_BOUNDARY_VALUE FROM "#table_partitions" WHERE TABLE_NAME='myIntervalHashPartition' ORDER BY PARTITION_BOUNDARY_VALUE; PARTITION_BOUNDARY_VALUE ----------------------------------- 2016-10-30T10:00:00Z # The 3 data partitions that in the interval (boundary value is '2016-08-01T10:00:00Z') 2016-10-30T10:00:00Z # includes '2016-09-15T10:00:00Z' have been deleted. 2016-10-30T10:00:00Z 2017-01-29T10:00:00Z :
3.2 Data control language (DCL)
3.3 Data management language (DML)
3.3.1 SELECT
Select data. Made up of a variety of Clauses such as FROM, WHERE, etc.
Syntax
SELECT [{ALL|DISTINCT}] column_name_1 [, column_name_2 ...] [ FROM clause ]
[ WHERE clause ]
[ GROUP BY clause [ HAVING clause ]
[ ORDER BY clause ]
[ LIMIT clause [ OFFSET clause ]];
3.3.2 INSERT
Register rows in a table.
Syntax
{INSERT|INSERT OR REPLACE|REPLACE} INTO table_name
{VALUES ( { number_1 | string_1 } [, { number_2 | string_2 } ...] ), ... | SELECT statement};
3.3.4 UPDATE
Update the rows existing in a table.
Syntax
UPDATE table_name SET column_name_1 = expression_1 [, column_name_2 = expression_2 ...] [ WHERE clause ];
Specifications
- The value of the PRIMARY KEY column can not be updated.
-
For partitioned tables, it is impossible to update a value of partition key to a different value using the UPDATE statement.
-
Example:
CREATE TABLE tab (a INTEGER, b STRING) PARTITION BY HASH a PARTITIONS 5; -- NG UPDATE tab SET a = a * 2; [240016:SQL_COMPILE_PARTITIONING_KEY_NOT_UPDATABLE] Partitioning column='a' is not updatable -- OK UPDATE tab SET b = 'XXX';
In such a case, INSERT after DELETE.
-
Example:
3.4 Clauses
3.4.2 GROUP BY
Among the results of the clauses specified earlier, rows having the same value in the specified column will be grouped together.
Syntax
GROUP BY column_name_1 [, column_name_2 ...]
3.4.3 HAVING
Perform filtering using the search condition on data grouped by the GROUP BY clause. GROUP BY clause cannot be omitted.
Syntax
HAVING search_conditions
3.4.4 ORDER BY
Sort search results.
ORDER BY column_name_1 [{ASC|DESC}] [, column_name_2 [{ASC|DESC}] ...]
3.4.5 WHERE
Apply a search condition on the result of the preceding FROM clause.
Syntax
WHERE search_conditions
Specifications
- Predicates and the SELECT statement, etc. can be used for search conditions.
3.5 Predicates
BETWEEN, IN and LIKE predicates can be used in addition to comparison predicates that use comparison operators (=, >, etc.).
3.5.1 BETWEEN
Extract values of the specified range.
Syntax
expression_1 [NOT] BETWEEN expression_2 AND expression_3
Specifications
-
BETWEEN predicate is true when the following condition is satisfied.
expression_2 <= expression_1 <= expression_3
- When NOT is specified, this predicate is true for rows which do not satisfy the condition.
3.5.2 IN
Extract a set that satisfies that conditions.
Syntax
expression_1 [NOT] IN ( expression_2 [, expression_3 ...] )
3.5.3 LIKE
Conduct a comparison of the matching patterns.
Syntax
expression [NOT] LIKE character_pattern [ESCAPE escape_character ]
Specifications
-
A character pattern is expressed using special characters such as % or _.
- %: Any string
- _: Any character
If you want to use % and _ as normal characters, write the escape characters in front of the % or _ after specifying the escape characters in the [ESCAPE escape_character ] format.
3.6 Comment
Comments can be written in a SQL command. Format: Description at the back of -- (2 hyphens) or enclose with /* */. A new line needs to be returned at the end of the comment.
3.7 Functions
The following functions are available in the SQL commands of GridDB AE.
AVG, GROUP_CONCAT, SUM, TOTAL, EXISTS, ABS, CHAR, COALESCE, IFNULL, INSTR, HEX, LENGTH, LIKE, LOWER, LTRIM, MAX, MIN, NULLIF, PRINTF, QUOTE, RANDOM, RANDOMBLOB, REPLACE, ROUND, RTRIM, SUBSTR, TRIM, TYPEOF, UNICODE, UPPER, ZEROBLOB, NOW, TIMESTAMP, TO_TIMESTAMP_MS, TO_EPOCH_MS, EXTRACT, TIMESTAMPADD, TIMESTAMPDIFF
3.8 Hints
In GridDB AE, specifying the hints indicating the execution plan in the query makes it possible to control the execution plan without changing the SQL statement.
[Points to note]
- This function might change in future release.
3.8.1 Explanation of terms
The following table explains the hint function related terms.
| Term | Meaning |
|---|---|
| Hint phrase | Information for controlling the execution plan |
| Hint | An enumeration of hint phrases |
3.8.2 Specifying hints
Write the hint in the block comment of the query to control the execution plan. The block comment for the hint, can only be written immediately before or after the first SELECT (INSERT/UPDATE/DELETE) statement in SQL. To distinguish a hint comment from regular comments, the block comment for the hint begin with "/*+".
The target to give a hint is specified by the object name or alias in parentheses. The targets are separated by either space, tab, or newline.
In the following example, the MaxDegreeOfParallelism hint phrase sets the upper limit of processing thread number to 2, and the Leading hint phrase specifies the table join order.
/*+
MaxDegreeOfParallelism(2)
Leading(t3 t2 t1)
*/
SELECT *
FROM t1, t2, t3
ON t1.x = t2.y and t2.y = t3.z
ORDER BY t1.x
LIMIT 10;
[Memo]
- In case of using a table with the same name more than once in the query due to a schema difference or multiple use of the same table, distinguish each table by giving an alias to the table.
3.8.3 List of hint phrases
The following table shows the available hint phrases.
| Class | Operation | Description |
|---|---|---|
| Parallelism | MaxDegreeOfParallelism(upper_limit) | Maximum number of processing threads for one query. |
| MaxDegreeOfTaskInput(upper_limit) | Maximum number of inputs for one task. | |
| MaxDegreeOfExpansion(upper_limit) | Maximum number of expansion nodes of planning. | |
| Distributed planning | DistributedPolicy(policy) | Selection of distributed planning policy. |
| 'LOCAL ONLY' or 'LOCAL PREFER' are available. | ||
| Scanning method | IndexScan(table) | Index scan is used if possible. |
| NoIndexScan(table) | No index scan is used. | |
| Joining method | IndexJoin(table table) | Using index join if possible. |
| NoIndexJoin(table table) | No index join is used. | |
| Table joining order | Leading(table table [table ...]) | Join specified tables in the specified order. |
| Leading(( table set table set )) | Join the first specified table set as the outer table and | |
| table set = { table or | the second set as the inner table. ('Table set' in expression | |
| ( table set table set ) } | indicates single table or table set) |
3.8.4 Details of hint phrases
This chapter shows details for each category of hint phrases.
3.8.4.1 Parallelism
Control parallelization processing.
-
MaxDegreeOfParallelism(upper_limit)
- Specify the maximum number of processing threads for one query when processing SQL in a node.
-
MaxDegreeOfTaskInput(upper_limit)
-
Specify the maximum number of inputs for one task. It applies to the following processing:
- UNION ALL processing when scanning the partitioned table
-
Specify the maximum number of inputs for one task. It applies to the following processing:
-
MaxDegreeOfExpansion(upper_limit)
-
UNION ALL processing when scanning the partitioned table It applies to the following processing:
- Push down join optimization processing
-
UNION ALL processing when scanning the partitioned table It applies to the following processing:
3.8.4.2 Distributed planning
Specify distributed planning policy.
-
DistributedPolicy(policy)
-
Following distributed planning policies are available:
-
'LOCAL_ONLY'
- The planner uses only the local information of the connected node without distributing. An error occurs if no table found in local.
-
'LOCAL_PREFER'
- The planner gives priority to the local information of the connected node. A remote plan is generated if no table found in local.
-
'LOCAL_ONLY'
-
Following distributed planning policies are available:
3.8.4.3 Scanning method
Specify scanning method.
-
IndexScan(table)
- Index scan is used if possible. If it cannot be used, nothing is done.
-
NoIndexScan(table)
- No index scan is used.
3.8.4.4 Joining method
Specify which joining method to select for a table combination.
-
IndexJoin(table table)
- Index join is used if possible. If it cannot be used, nothing is done.
-
NoIndexJoin(table table)
- No index join is used.
3.8.4.5 Table joining order
Specify in what order the tables are joined.
(1) Specify only joining order: Leading(table table [table ...])
Specify the table names or aliases in order from the first table to be joined. In this method, using only Left-deep join orders.
[Example 1]
/*+ Leading(S R Q P) */ SELECT * FROM P,Q,R,S WHERE P.x = Q.x AND ...
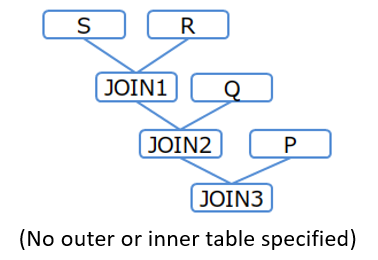
Table joining order (Example 1)
(2) Specify joining order and direction: Leading(( _table set_ _table set_ ))
table set = { table or ( table set table set ) }
In case of specifying only joining order like (1), the joining direction (different for outer table or inner table) may be different from expectation. To fix the joining direction, use the following expression.
/*+ Leading((t1 (t2 t3))) */ SELECT ...
In this expression, parentheses can be nested. It joins the first specified table set as the outer table and the second set as the inner table.
[Example 2-1]
/*+ Leading(((P Q) R)) */ SELECT * FROM P,Q,R WHERE P.x = Q.x AND ...
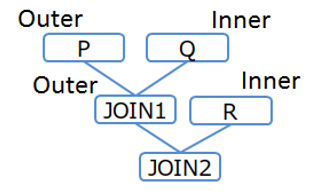
Table joining order (Example 2-1)
[Example 2-2]
/*+ Leading((R (Q P))) */ SELECT * FROM P,Q,R WHERE P.x = Q.x AND ...
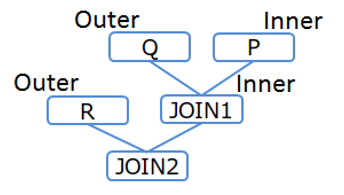
Table joining order (Example 2-2)
[Example 2-3]
/*+ Leading(((P Q) (R S))) */ SELECT * FROM P,Q,R,S WHERE P.x = Q.x AND ...
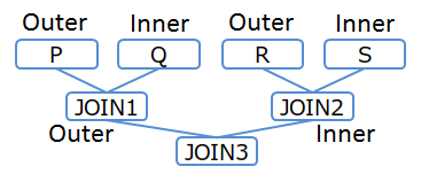
Table joining order (Example 2-3)
[Memo]
- If three or more tables are joined and there is no join condition between the tables, it is impossible to specify the order by hint.
3.8.5 Error handling
In the following cases, a syntax error occurs.
- Multiple block comments for hints are described
- The hint is described in the wrong position
- There is a syntax error in the description of the hint phrase
- Duplicate hint of the same class are specified for the same table
In the following case, a table specification error occurs:
- The table specification of the hint phrase is incorrect
[Memo]
- When a table specification error occurs, ignore the error hint phrase and execute the query using the others.
- When a syntax error and a table specification error occur at the same time, a syntax error occurs.
4 Metatables
4.1 About metatables
The metatables are tables that are used for checking metadata of data management in GridDB.
[Memo]
- Metatables can only be referred. It is not allowed to register or delete data in the metatables.
- When SELECT data from the metatables, it is necessary to enclose the table name with double quotation marks.
[Points to note]
- The schema of metatables may be changed in future version.
4.2 Table information
Table information can be obtained.
Table name
#tables
Schema
| Column name | Description | Type |
|---|---|---|
| DATABASE_NAME | Database name | STRING |
| TABLE_NAME | Table name | STRING |
| TABLE_OPTIONAL_TYPE | Table type | STRING |
| COLLECTION / TIMESERIES | ||
| DATA_AFFINITY | Data affinity | STRING |
| EXPIRATION_TIME | Expiry release elapsed time | INTEGER |
| EXPIRATION_TIME_UNIT | Expiry release elapsed time unit | STRING |
| EXPIRATION_DIVISION_COUNT | Expiry release division count | STRING |
| COMPRESSION_METHOD | Time series compression method | STRING |
| COMPRESSION_WINDOW_SIZE | Time series compression max period of thinning | INTEGER |
| COMPRESSION_WINDOW_SIZE_UNIT | Time series compression max period unit of thinning | STRING |
| PARTITION_TYPE | Partitioning type | STRING |
| PARTITION_COLUMN | Partitioning key | STRING |
| PARTITION_INTERVAL_VALUE | Interval value (For interval or interval hash) | INTEGER |
| PARTITION_INTERVAL_UNIT | Interval unit (For interval of interval hash) | STRING |
| PARTITION_DIVISION_COUNT | Division count (For hash) | INTEGER |
| SUBPARTITION_TYPE | Partitioning type | STRING |
| ("Hash" for interval hash) | ||
| SUBPARTITION_COLUMN | Partitioning key | STRING |
| (For interval hash) | ||
| SUBPARTITION_INTERVAL_VALUE | Interval value | INTEGER |
| SUBPARTITION_INTERVAL_UNIT | Interval unit | STRING |
| SUBPARTITION_DIVISION_COUNT | Division count | INTEGER |
| (For interval hash) | ||
| EXPIRATION_TYPE | Expiration type | STRING |
| ROW / PARTITION |
4.3 Index information
Index information can be obtained.
Table name
#index_info
Schema
| Column name | Description | Type |
|---|---|---|
| DATABASE_NAME | Database name | STRING |
| TABLE_NAME | Table name | STRING |
| INDEX_NAME | Index name | STRING |
| INDEX_TYPE | Index type | STRING |
| TREE / HASH / SPATIAL | ||
| ORDINAL_POSITION | Order of column in index (always 1) | SHORT |
| COLUMN_NAME | Column name | STRING |
4.4 Partitioning information
Data about partitioned tables can be obtained from this metatable.
Table name
#table_partitions
Schema
| Column name | Description | Type |
|---|---|---|
| DATABASE_NAME | Database name | STRING |
| TABLE_NAME | Partitioned table name | STRING |
| PARTITION_BOUNDARY_VALUE | The lower limit value of each data partition | STRING |
Specifications
-
Each row represents the information of a data partition.
- For example, when searching rows of a hash partitioned table in which the division count is 128, the number of rows displayed will be 128.
- In the metatable “#table_partitions”, the other columns may be displayed besides the above columns.
- It is required to cast the lower limit value to the partitioning key type for sorting by the lower limit value.
Examples
-
Check the number of data partitions
SELECT COUNT(*) FROM "#table_partitions" WHERE TABLE_NAME='myIntervalPartition'; COUNT(*) ----------------------------------- 8703
-
Check the lower limit value of each data partition
SELECT PARTITION_BOUNDARY_VALUE FROM "#table_partitions" WHERE TABLE_NAME='myIntervalPartition' ORDER BY PARTITION_BOUNDARY_VALUE; PARTITION_BOUNDARY_VALUE ----------------------------------- 2016-10-30T10:00:00Z 2017-01-29T10:00:00Z : -
Check the lower limit value of each data partitions on the interval partitioned table “myIntervalPartition2” (partitioning key type: INTEGER, interval value: 20000)
SELECT CAST(PARTITION_BOUNDARY_VALUE AS INTEGER) V FROM "#table_partitions" WHERE TABLE_NAME='myIntervalPartition2' ORDER BY V; PARTITION_BOUNDARY_VALUE ----------------------------------- -5000 15000 35000 55000 :
5 References
- Website of Japan Industrial Standards Committee, http://www.jisc.go.jp/, JISX3005-2 database language SQL, Section 2: Basic Functions (SQL/Foundation)
6 Annex: Keywords
The following terms are defined as keywords in the SQL of GridDB AE.
ABORT ACTION AFTER ALL ANALYZE AND AS ASC BEGIN BETWEEN BY CASE CAST COLLATE COLUMN COMMIT CONFLICT CREATE CROSS DATABASE DAY DELETE DESC DISTINCT DROP ELSE END ESCAPE EXCEPT EXCLUSIVE EXISTS EXPLAIN EXTRACT FALSE FOR FROM GLOB GRANT GROUP HASH HAVING HOUR IDENTIFIED IF IN INDEX INITIALLY INNER INSERT INSTEAD INTERSECT INTO IS ISNULL JOIN KEY LEFT LIKE LIMIT MATCH MILLISECOND MINUTE MONTH NATURAL NO NOT NOTNULL NULL OF OFFSET ON OR ORDER OUTER PARTITION PARTITIONS PASSWORD PLAN PRAGMA PRIMARY QUERY RAISE REGEXP RELEASE REPLACE RESTRICT REVOKE RIGHT ROLLBACK ROW SECOND SELECT SET TABLE THEN TIMESTAMPADD TIMESTAMPDIFF TO TRANSACTION TRUE UNION UPDATE USER USING VALUES VIEW VIRTUAL WHEN WHERE WITHOUT XOR YEAR